007 基于YOLOv3的目标检测系统 |
您所在的位置:网站首页 › 操的笔画顺序表怎么写 › 007 基于YOLOv3的目标检测系统 |
007 基于YOLOv3的目标检测系统
|
007 基于YOLOv3的目标检测系统 功能 PyThon实现的目标检测系统代码,基于深度学习框架PyTorch编程,采用YOLOv3检测网络作为核心模型,可用于对车辆、行人、飞机、轮船、猫、狗等几十种类别进行检测和识别,并在QT界面中将结果可视化。代码可用于训练、验证和评估模型。在QT界面中,用户可以选择加载图像、摄像头和视频流三种模式作为模型输入。对模型训练完成后,用户可以根据自己数据集完成权重替换并可视化结果。用户还可以根据自己的需求,去更改QT界面的背景、按钮等,界面的操作和相关的代码都有详细的注释。 模型 YOLOv3(You Only Look Once version 3)是一种基于深度学习的目标检测模型。与传统的目标检测算法不同,YOLOv3将目标检测任务视为回归问题,通过一个卷积神经网络来直接从输入图像预测目标框和对应的类别概率。YOLOv3采用了多尺度检测技术,即在不同的网络层级上进行特征提取和融合,以检测不同大小的目标。此外,YOLOv3还引入了残差网络(ResNet)和特征金字塔网络(FPN)等技术,以提高模型的特征表示能力和检测精度。YOLOv3具有较快的检测速度和较高的检测精度,适用于对实时性要求较高的应用场景。YOLOv3已被广泛应用于自动驾驶、智能安防、人体姿态估计等领域,成为目标检测领域的重要技术之一。 数据集检测类别 常用包括车辆、行人、飞机、轮船、猫、狗、马、鸟、羊、自行车、瓶、椅子、火车、沙发、餐桌、电视机、盆栽植物等几十个类别进行检测和识别。
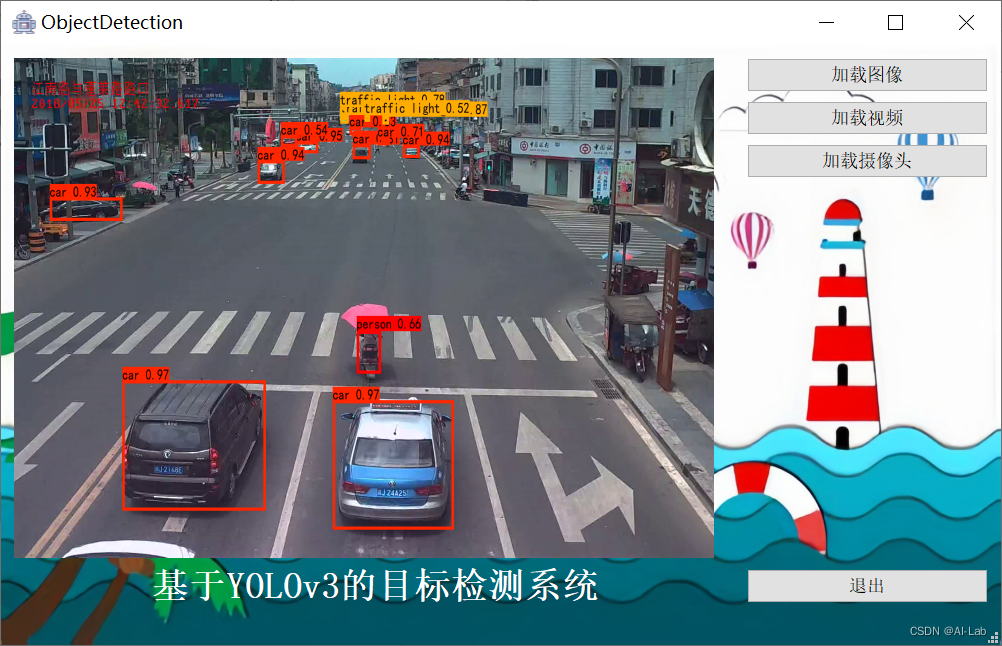
文件夹包含的内容 完整的程序文件(.py)UI界面文件(qt.py)可供预测的图像文件和视频文件(./img/street.jpg and video.avi)训练和预测代码(.py)(1)加载图像进行检测:可以选择图像进行目标检测,系统将检测和识别后的结果标注在图像上并在界面上自动展示。
(2)加载视频进行检测:可以选择视频进行目标检测,系统将检测和识别后的结果标注在视频上并在界面上自动展示。
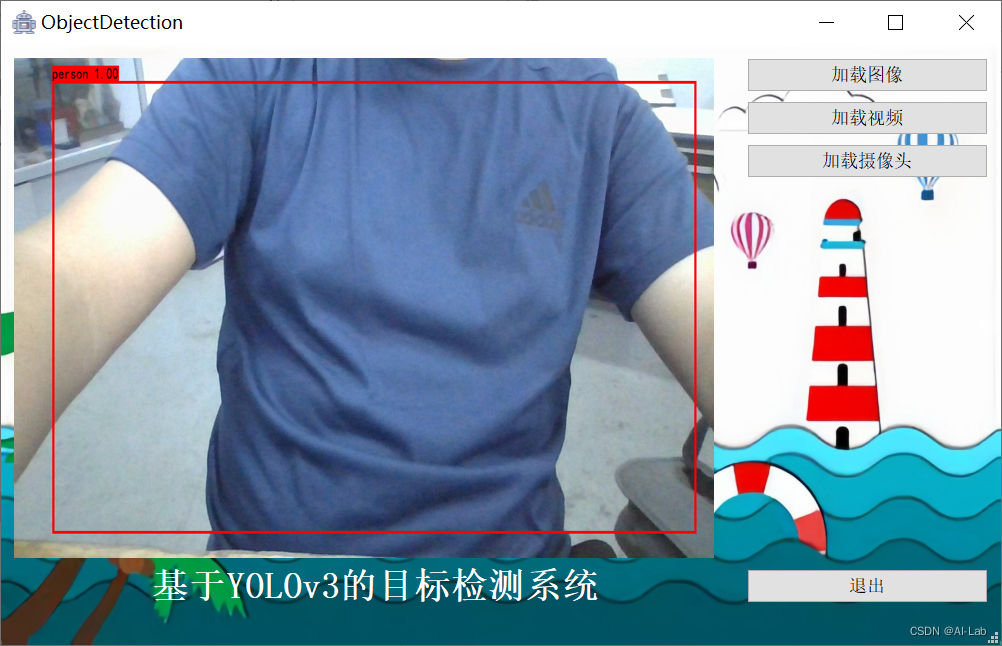
(3)加载摄像头进行检测:可以选择摄像头进行目标检测,系统将检测和识别后的结果标注在图像流上并在界面上自动展示。
代码展示
内附项目的详细操作说明,完整代码可私信获取,如有疑问可直接私信提供远程调试。 |


【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |