【NLP】一文详解生成式文本摘要经典论文Pointer |
您所在的位置:网站首页 › 摘要自动生成目录怎么做 › 【NLP】一文详解生成式文本摘要经典论文Pointer |
【NLP】一文详解生成式文本摘要经典论文Pointer
|
写在前面 Pointer-Generator Network 以及微软的 Unilm 是小喵在20年所研读的自动文本摘要方向系列论文中的两篇,到今天为止个人依旧认为它们是非常值得一读的。今天我们先分享 Pointer-Generator Networks。 简单地说,Pointer-Generator Networks 这篇论文的idea以及背后的动机具备说服力。它直接抛出问题,给出解决办法,并且解决办法的motiviation以及本身的描述都不会让人困惑,接受度强。 需要注意的是,Pointer-Generator Networks 所针对的是 长文本摘要(multi-sentences summaries、longer-text summarization),而不是 短文本摘要(headline、short-text summarization)。 本文关键词:自动文本摘要、文本生成、copy机制、attention 论文名称:《Get To The Point:Summarization with Pointer-Generator Networks》 论文链接:https://arxiv.org/abs/1704.04368 代码地址:https://www.github.com/abisee/pointer-generator 1. 背景 1.1 为什么要做文本摘要简单地说就是信息过载,再加上时间就是金钱。大家可能不愿意同时也没有那么多时间从头到尾去看一篇或许自己并不感兴趣的文章。 这个时候,就需要咱们的 NLP 的技术了。可以利用 摘要/关键词/实体识别 等技术对文章进行加工处理获得一些概括性信息。这些信息虽然短,但表达了文章的大意、关键信息,可以让读者对文章有个大体的认识,帮助读者更快地过滤信息,进而选择自己更感兴趣的文章再去了解细节。 1.2 文本摘要的主要技术路线自动文本摘要主要有两条技术路线:抽取式和生成式。 (1) 抽取式文本摘要抽取式文本摘要 通常是从原文中抽取短语/词/句子形成摘要,也可视为二分类问题或者是重要性排序问题。 其优点是概括精准且语法正确。但是,抽取式的结果不符合大多数情况下人阅读以后做总结/概括的模式:建立在理解的基础上,可能会用原文中的词,也可能会用新词(未出现在原文中的词)来做表述,即允许一定的用词灵活性。 (2)生成式文本摘要与 生成式文本摘要 类似的任务有:标签生成、关键词生成等。通常,生成式任务的模型基础就是 seq2seq/encoder+decoder,也就是一个序列到序列的生成模型。attention 出现以后,生成式的基础模型就是 seq2seq+attention。 其优点是相比于抽取式而言用词更加灵活,因为所产生的词可能从未在原文中出现过。总的来说,与我们在阅读文章后为其写摘要或总结的模式一致:基于对原文的理解,并以相较于原文更简短的语句来重述故事。 2. 问题根据第1部分所述,似乎生成式相比于抽取式更加优越。其实不然,因为我们还没有提生成式的缺点。那这一节,我们就来看看生成式弱在哪儿? 2.1 生成式的基本原理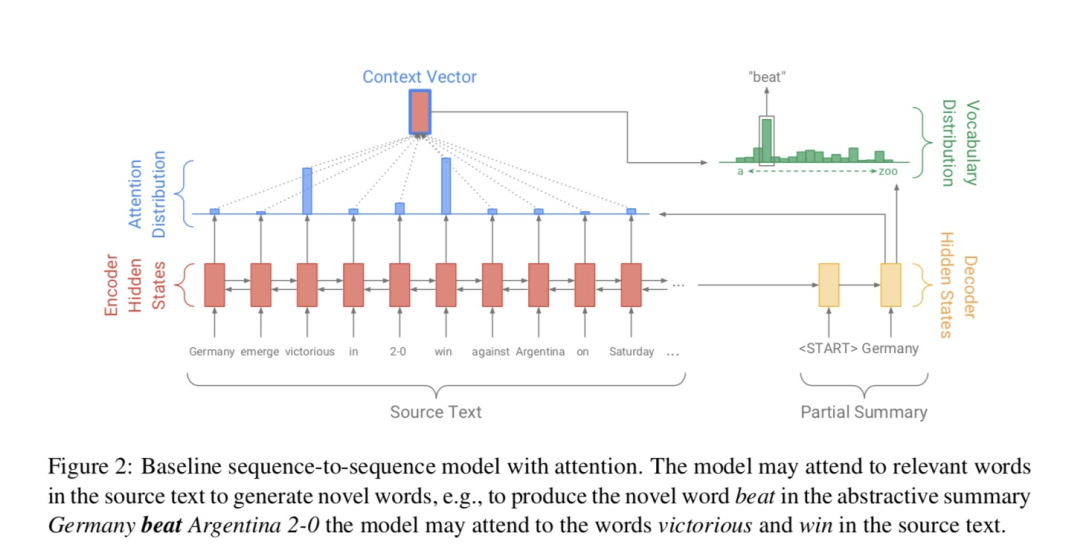
生成类模型的基本建模思想是语言模型: 这是一个序列生成过程:每个time step(时间步)都在一个fixed vocabulary(预先设定好的固定词库)中选一个词。实际上,每个时间步都在做多分类,我们通过计算固定词表中的每个词在当前条件下出现的概率,来选出当前时间步下应该出现的词。 2.2 生成式模型的问题总的来说,抽取式技术毕竟用的就是原文的内容,所以通常在语法层面的正确性以及对原文概括的准确性上比较占优势;而生成式的灵活性则导致了生成式模型普遍具有的问题:易重复;还原事实时不可控:可能生成语义不完整/不连续的句子,或者压根就跟原文表达的意思相去甚远;OOV问题。 (1) OOV既然是 fixed vocabulary,那么必然就会有词 out of the fixed vocabulary。换句话说,生成模型存在 OOV 问题:无法生成OOV的词,只能生成固定词表中的词。 (2) 重复性另外一点就是重复性,模型可能在某些time step上生成先前time step 已经生成过的词。 (3) 语义不连贯、语法逻辑性低、重述准确性不高每一步去 fixed vocabulary 中选词,最终形成摘要,这里面就会存在生成的摘要语义不连贯、语义不通顺。相较于抽取式,更为严重的问题就是重述原文的准确性不高。 3. 核心思想那么如何解决生成式模型的这些问题,以提高生成式摘要的质量呢? 其实,我们可以看到生成式的这些缺点都是相较于抽取式而言的。那么融合抽取模式,是不是就可能既保留了生成式的灵活性,又将生成的摘要的质量向抽取式的质量标杆靠近了些呢? 答案是可以的。那究竟怎么做呢? 3.1 hybird pointer-generator network针对重述语义不正确/精确的问题,同时也针对OOV问题,设计了一个个融合模型 pointer-generator。 模型基础依旧是 seq2seq+attention,这部分作为 generator;此外,引入了 pointer。所以,它既能基于 pointer 从原文中选词,也能基于 generator 生成词。 注意这里的 generator 本质上还是选词,但是是基于固定的词库通过 softmax 来选。词库本身是在训练模型时从训练数据统计构造的。 3.2 coverage-mechinism针对重复性问题,设计了coverage-mechinism。其本质上是会跟踪记录在当前step前已经被选过的词,这样能在后续step生成词时弱化对这部分的关注,从而减少重复性问题。 4. 模型细节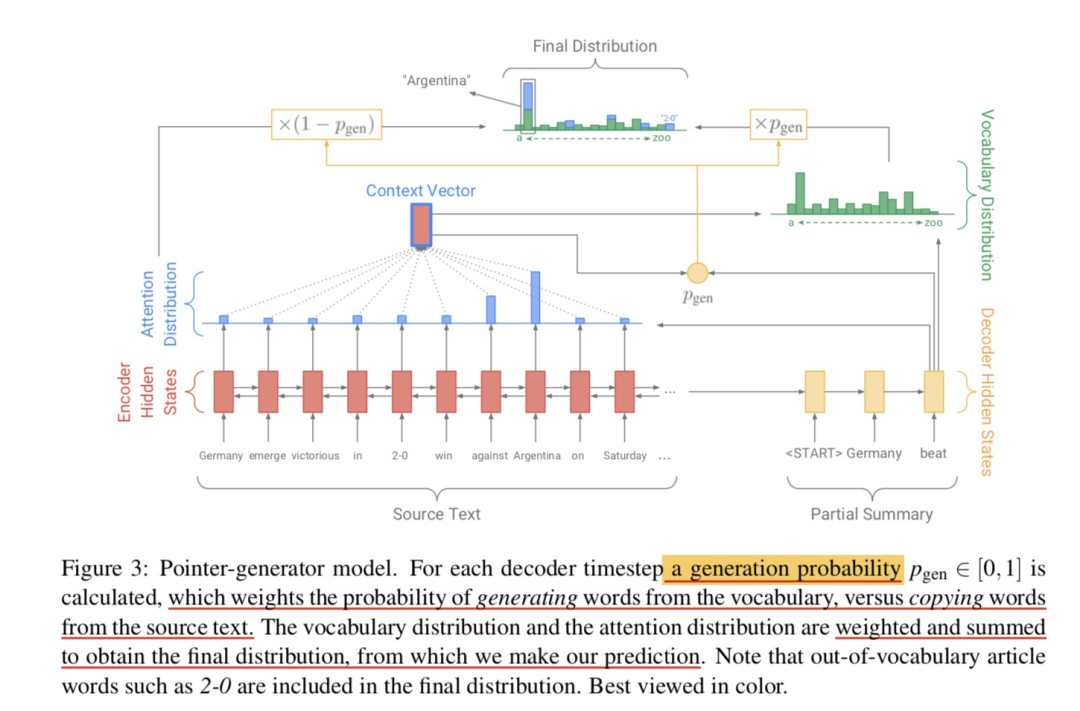 4.1 baseline model:seq2seq+attention
4.1 baseline model:seq2seq+attention
这部分主要分享其思想,就不再赘述相关公式了。 编码器(encoder): 双向序列模型,如双向lstm/rnn。 解码器(decoder): 因为解码的过程是一个马尔可夫过程,要确保不能见到将来的信息,所以解码器一般是单向序列模型,如单向的lstm/rnn。 注意力机制(attention): 基于当前解码步的decoder state 以及编码器所有时刻的 hidden state 计算 attention score,即对编码器的所有时刻 hidden state 的关注程度。然后基于 attention score 加权编码器端的 hidden state 形成当前解码步的 context vector。解码步再基于这个 context vector 和当前 decode state 去生成词。 4.2 pointer-generator network (1) 思路要抽取原文的内容,加一个 pointer 就可以,它的作用是告诉我们当前 time step 应该从原文中选择哪一个词。 另一方面,生成的灵活性我们也不能丢掉。那么问题就可以这样 转换成这样: 其中,就是生成式的模型,是抽取式的模型。也就是说每个 time step的词一定概率我们用生成获取,一定概率我们用抽取获取。 进一步还可以更加 soft,不是非此即彼,而是二者加权表决。怎么做呢? (2) 解法在决定生成哪一个词时,取二者的加权和: 402 Payment Required其中: 生成式模型,也就是公式中的,计算方式和 baseline model一致; 抽取式模型,利用pointer来实现,也即公式中的,这里就是简单地就是利用生成模型计算出的attention求和,表示所有位置处对该词关注度的和。 则利用contex vector和decode state、decode input来计算,表示是生成式的权重;代表抽取式的权重。 这里相当于是扩展词库了,利用待抽取摘要的文章中的词把 fixed vocabulary 变成 extened vocabulary,模型有能力可以生成 OOV的词。 对于OOV的词来说,它的,所以是利用pointer从原文中获取;而对于未出现在原文中的词来说,我们自然有它的,所以是依靠generator从固定词库中获取。对于既出现在原文又出现在词库中的词,当然就是两部分一起作用。 4.3 coverage-mechinism (1) 思路说了这么多,还有一个待解决的问题,就是repetition(重复性问题)。 要怎么解决呢。简单且直观的做法就是追踪前面已经用过的词,这样就能避免或者说一定程度上减缓重复。 (2) 解法具体怎么做呢,就是利用一个coverage vector,综合计算每个词在当前时间步前受到的总的关注度。这里呢,主要就是累加各个时间步的 attention score: 这个可以这么理解:pointer的部分不就是利用attention score 来选词的吗(选 attention score 大的词),所以我把这个记住,然后加一个损失惩罚来惩罚选词的重复性: 显然只有 attention 和 coverage vector 在每一个位置上都极大差异,这个损失才能最小(有上界的损失)。所以这个损失可以避免attention的重复:也就是当前时间步尽可能被忽视在当前时间步之前受关注度大的词(极大可能已经被选过的词)。 此外,对于generator部分,我们可以动的就是改进attention的计算: 每一步,把先前的这个coverage vector考虑进去,让它起作用:期望能够生成不一样的attention score, 从而产生不一样的context vector,进而在解码生成词的时候不一样。 最终每一步的损失即为两部分损失和,一部分为抽取式的,另一部分为生成式的负对数似然: 402 Payment Required而总的损失即为: 总结好了,关于生成式摘要论文 pointer-generator Networks 的内容就到这里了。如果本文对你有帮助的话,欢迎点赞&在看&分享,这对我继续分享&创作优质文章非常重要。感谢🙏!
|


【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |