python读取大型csv文件,降低内存占用,提高程序处理速度 |
您所在的位置:网站首页 › 提取内存中的文件 › python读取大型csv文件,降低内存占用,提高程序处理速度 |
python读取大型csv文件,降低内存占用,提高程序处理速度
|
文章目录
简介读取前多少行读取属性列逐块读取整个文件总结参考资料
简介
遇到大型的csv文件时,pandas会把该文件全部加载进内存,从而导致程序运行速度变慢。 本文提供了批量读取csv文件、读取属性列的方法,减轻内存占用情况。 import pandas as pd input_file = 'data.csv' 读取前多少行加载前100000行数据 df = pd.read_csv(input_file, nrows=1e5) df查看每个字段占用的系统内存的情况 df.info(memory_usage='deep')设置 memory_usage 的参数为 ‘deep’ 时,深度检查对象中的内存使用情况,包括对象中可能包含的其他对象(如列表、数组或其他数据结构)。若不设置deep参数,memory_usage 只会返回一个对象的基础内存使用情况,这主要基于对象本身的内存占用,而不考虑它可能引用的其他对象。 查看每列属性的内存占用情况; item = df.memory_usage(deep=True)
针对每个属性列的字节数进行求和,使用/ (1024 ** 2),实现1B到1MB的单位转换。验证了所有属性列的内存占用确实为 220.8MB。
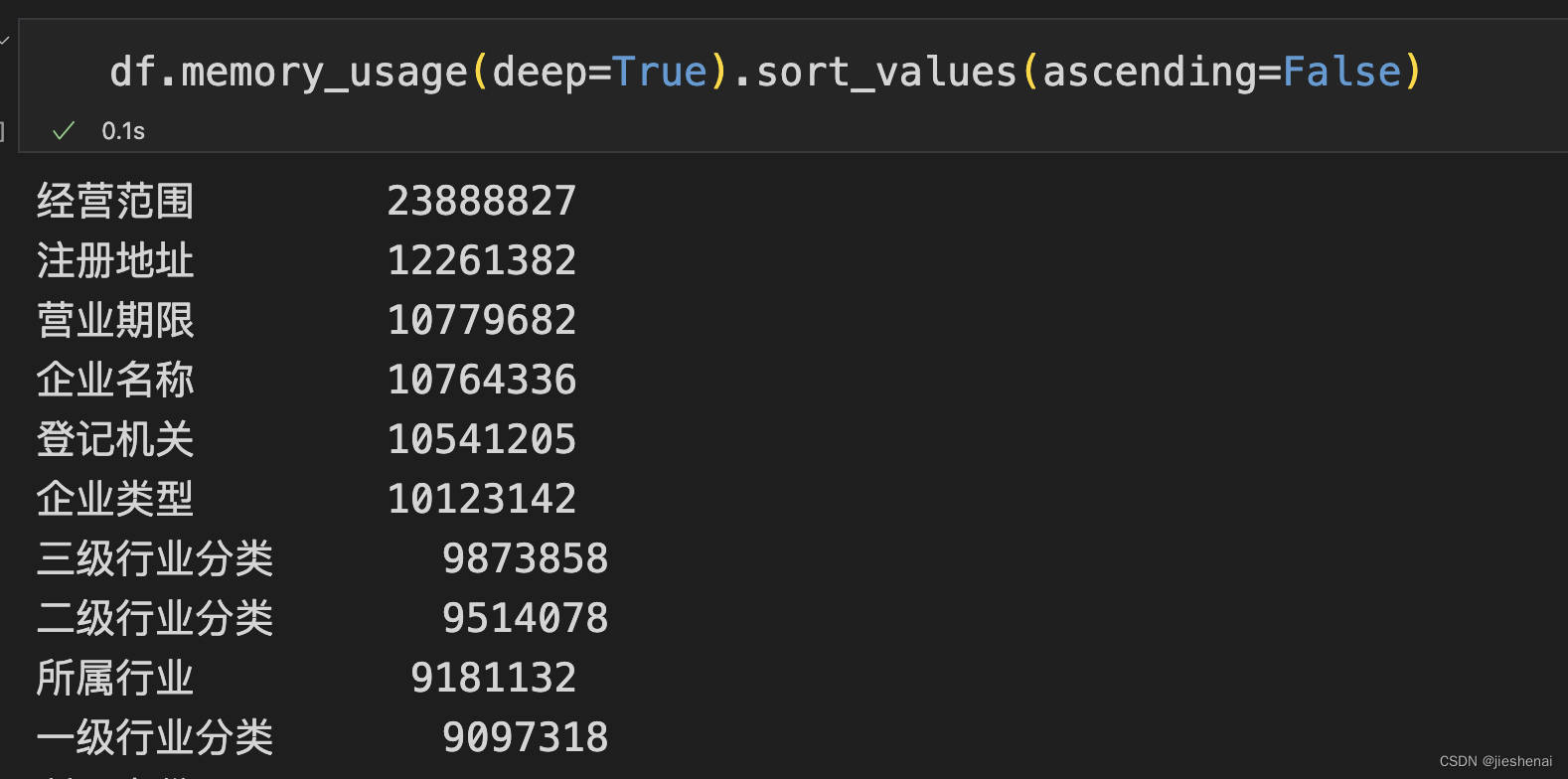
内存占用从高到低降序排列: df.memory_usage(deep=True).sort_values(ascending=False)
可能我们只关心, 一整张表中的某几个属性,比如:'企业名称', '经营范围'。那么便无需把整张表加载进内存。 df2 = pd.read_csv(input_file, nrows=1e5, usecols=['企业名称', '经营范围'])查看一下内存占用 df2.memory_usage(deep=True).sum() / (1024 ** 2)
pd.read_csv(input_file, chunksize=1e3, nrows=1e5) nrows=1e5: 读取100000条数据;chunksize=1e3: 每一块是1000条数据;故1e5条数据,应该由100块1e3的数据组成; # 分批次读取, 每chunksize是一个批次 chunk_dfs = pd.read_csv(input_file, chunksize=1e3, nrows=1e5) v = 0 cnt = 0 # 每个chunk_df 都是 dataframe 类型数据 for chunk_df in chunk_dfs: print(chunk_df.shape) cnt += 1 v += chunk_df.shape[0] print(v, cnt)
|
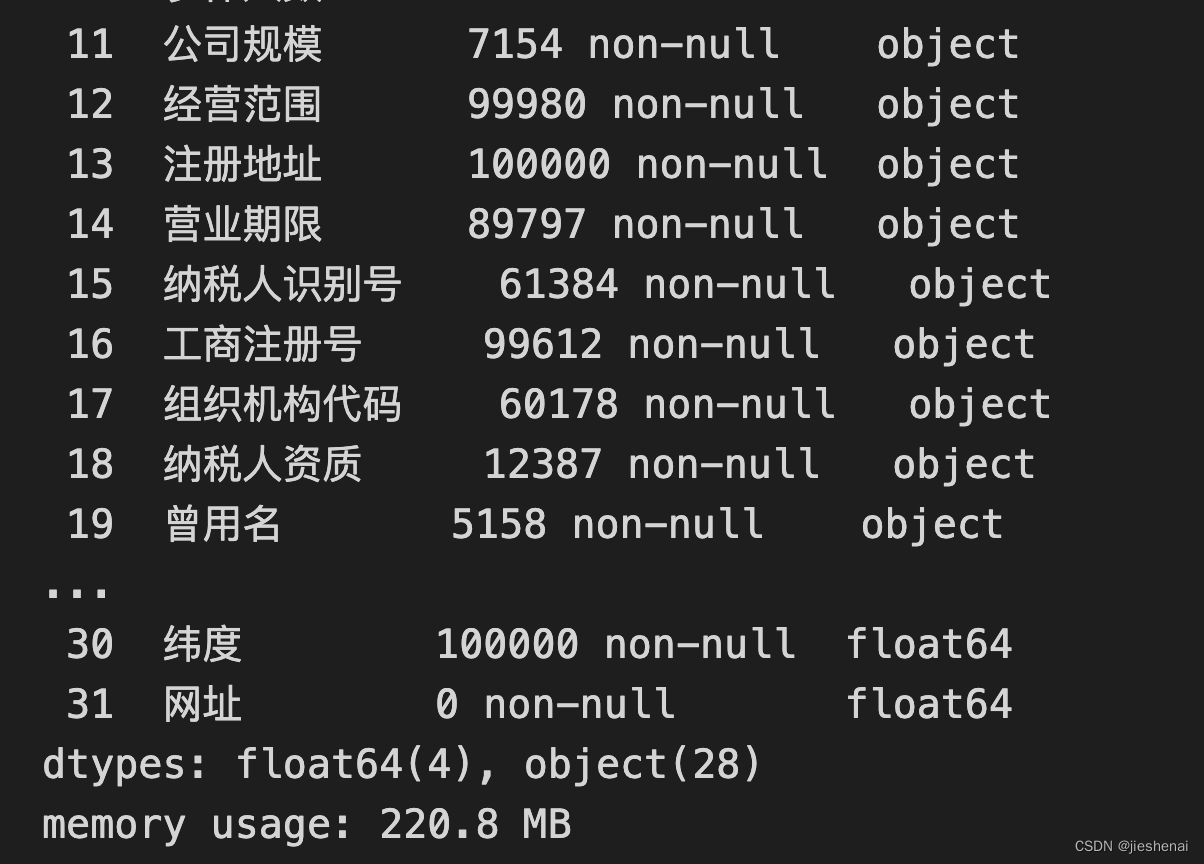 如上图所示,前100000行数据共占用220.MB内存。
如上图所示,前100000行数据共占用220.MB内存。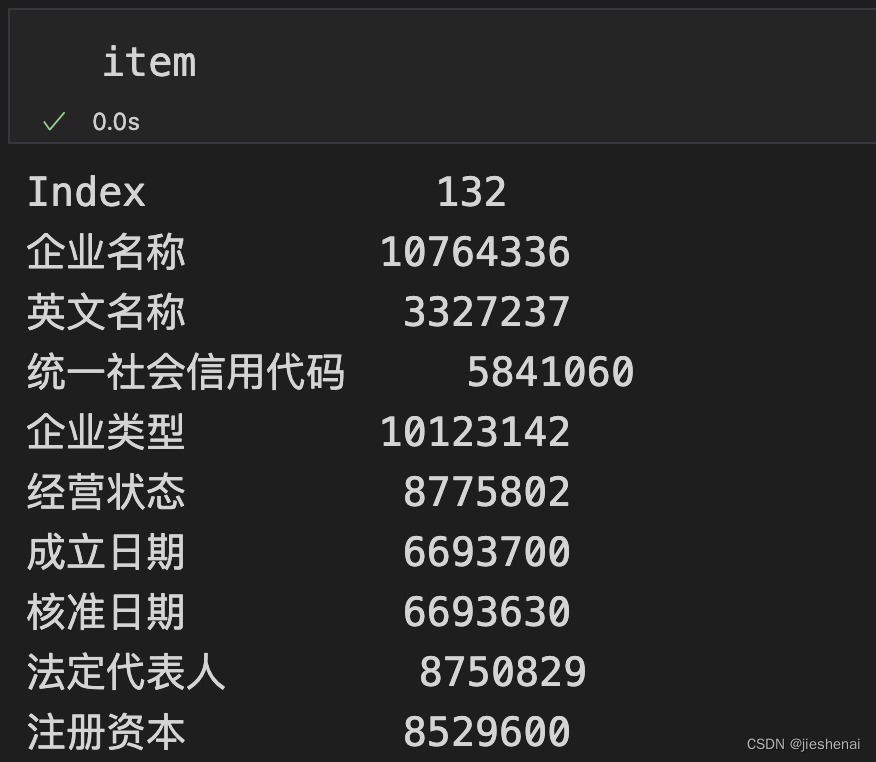
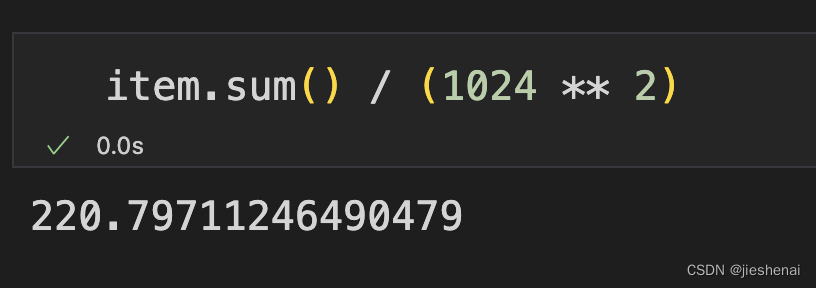
 只读取两个属性列,内存占用只有33MB。
只读取两个属性列,内存占用只有33MB。 上图验证了,总共处理了1e5条数据,分成了100块进行读取。
上图验证了,总共处理了1e5条数据,分成了100块进行读取。【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |