爬虫项目之豆瓣电影排行榜前10页 |
您所在的位置:网站首页 › 排名前十的电音 › 爬虫项目之豆瓣电影排行榜前10页 |
爬虫项目之豆瓣电影排行榜前10页
|
目录 一、学习资源: 二、知识点介绍 1、urlib库的基本使用 2、使用实例 ①获取网页源码 ②从服务器下载网页、图片、视频 3、UA介绍 ①简介 ②实例 三、项目详细讲解 1、分析 2、步骤 (1)请求对象定制 (2)获取响应数据 (3)下载数据 3、整体思路 四、项目源码 一、学习资源:尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例)_哔哩哔哩_bilibili大家记得一键三连【点赞、投币、收藏】感谢支持~本教程适合想掌握爬虫技术的学习者,以企业主流版本Python 3.7来讲解,内容包括:Python基础、Urllib、解析(xpath、jsonpath、beautiful)、requests、selenium、Scrapy框架等。针对零基础的同学可以从头学起,有Python基础的同学建议直接从第52集开始学习爬虫部分视频。教程中示例多种网站的爬取, 这位老师讲的很有激情,并知识点和逻辑清晰,强烈推荐 二、知识点介绍 1、urlib库的基本使用 2、使用实例
①获取网页源码
2、使用实例
①获取网页源码
①首先要获取url,但是因为要获取前十页的数据,url是一个变量,通过对网页的检查可以发现网页的url有规律,其起始页为(page-1)*20,其每页20个数据。 ②然后将data解析为unicode编码的数据,然后再和起始链接组合成为新的链接 解决了url的问题之后,请求对象的定制就变得简单了,就是把之前的内容进行了封装
相应的获取响应数据也是把之前的代码进行封装 (3)下载数据将获取到的网页数据写入文件即可 文件内容:
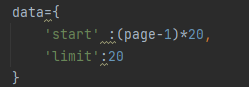
①通过一个主程序入口进入,也就是main函数 ②输入起始页码和结束页码 ③通过循环遍历的方式去获取数据,此处采用for循环,range函数是左闭右开的,所以结束的位置要加1才能到达效果 ④请求对象定制,用函数实现其功能(create_request),定义函数时不知道其返回值和传递值,可以不写,然后再根据需要去添加。定义函数时发现需要所处页面的值,则传入加上page。 ⑤获取相应数据,用函数实现其功能(get_content),同样的,定义函数时不知道其返回值和传递值则先不写,然后再根据需要去添加。定义函数是发现需要上一个的对象,则create_request需要返回一个对象(request),把create_request()函数完善 ⑥下载数据,存储到文件中,用函数实现其功能(down_load),同样的,定义函数时不知道其返回值和传递值则先不写,然后再根据需要去添加。定义函数时发现需要网页数据,则get_content需要返回内容,完善get_content函数()。 四、项目源码 # coding=utf-8 import urllib.request #https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20 #https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20 #https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=40&limit=20 #page 1 2 3 4 #start 0 20 40 60 #start=(page-1)*20 #下载豆瓣电影前十页的数据 #(1)请求对象的定制 #(2)获取响应的数据 #(3)下载数据 import urllib.parse import urllib.request #(1)请求对象的定制 def create_request(page): base_url='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&' data={ 'start' :(page-1)*20, 'limit':20 } data = urllib.parse.urlencode(data)#解析data将data变为unicode编码 url = base_url + data headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36" } request = urllib.request.Request(url=url,headers=headers) return request #(2)获取响应的数据 def get_content(request): response = urllib.request.urlopen(request) content = response.read().decode('utf-8') return content #(3)下载数据 def down_load(page,content): with open('douban_' + str(page) +'.json','w',encoding='utf-8') as fp: fp.write(content) #程序入口 if __name__ == '__main__': start_page = int(input('请输入起始页码')) end_page = int(input('请输入结束的页面')) for page in range(start_page,end_page+1) :#左闭右开 #每一页都有自己的请求对象的定制 request = create_request(page) #获取响应的数据 content = get_content(request) #下载 down_load(page,content) |
 https://www.bilibili.com/video/BV1Db4y1m7Ho?p=86
https://www.bilibili.com/video/BV1Db4y1m7Ho?p=86

 之所以用UA是因为一些网站为了防止用爬虫去爬取网页信息所设置的一个检查机制,服务器要识别客户的操作系统及版本等数据,但是用正常的爬虫去爬取就不包含这些信息,所以要进行对象定制,让服务器以为我们是真的从浏览器中访问的。
之所以用UA是因为一些网站为了防止用爬虫去爬取网页信息所设置的一个检查机制,服务器要识别客户的操作系统及版本等数据,但是用正常的爬虫去爬取就不包含这些信息,所以要进行对象定制,让服务器以为我们是真的从浏览器中访问的。




【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |