基于CNN模型的手写字符识别的分析与实现过程 |
您所在的位置:网站首页 › 手写识别的原理是什么 › 基于CNN模型的手写字符识别的分析与实现过程 |
基于CNN模型的手写字符识别的分析与实现过程
|
目录 1.前言 2.使用的工具介绍 2.1.TensorboardX 2.2.Netron 3.搭建CNN神经网络 3.1 CNN结构 3.1.1卷积层 3.1.2池化层 3.1.3全连接层 3.2构建CNN与代码实现 3.3CNN结构模型数据流可视化 3.3.1tensorboardx可视化 3.3.2Netron可视化模型 4.特征提取可视化 5.分析 6.总结 1.前言MNIST是一个手写体数字的图片数据集,该数据集来由美国国家标准与技术研究所(National Institute of Standards and Technology (NIST))发起整理,一共统计了来自250个不同的人手写数字图片,其中50%是高中生,50%来自人口普查局的工作人员。该数据集的收集目的是希望通过算法,实现对手写数字的识别。被广泛地应用于机器学习和深度学习领域,用来测试算法的效果,例如线性分类器(Linear Classifiers)、K-近邻算法(K-Nearest Neighbors)、支持向量机(SVMs)、神经网络(Neural Nets)、卷积神经网络(Convolutional nets)等等。 1998年,Yan LeCun 等人发表了论文《Gradient-Based Learning Applied to Document Recognition》,首次提出了LeNet-5 网络,利用上述数据集实现了手写字体的识别。本篇博客也根据LeNet5网络结构进行理解后,搭建最原始的神经网络。 2.使用的工具介绍 2.1.TensorboardXTensorboardx 是 TensorFlow 的一个附加工具,可以记录训练过程的数字、图像等内容,类似于tensoboard,在机器视觉的可视化中使用起来很方便。具体使用参照这里 2.2.NetronNetron支持主流各种框架的模型结构可视化工作,支持windows,Linux,mac系统,使用起来很方便,直接去GitHub中下载exe文件就可以使用,然后将训练的模型保存为.pth等文件,在软件中打开文件即可。效果如下
当然也是可以直接通过pip install netron进行安装。 3.搭建CNN神经网络 3.1 CNN结构 此模型的结构是卷积层--池化层--卷积层--池化层--全连接层 3.1.1卷积层卷积层(Convolutional layer)由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。 主要的工作原理就是通过n*n大小的kernel对每张图片的每各通道进行扫描,每次都是选取n*n大小的数据跟kernel上的数据进行运算,得出一个值,而后继续一定,直到扫描完所有数据。 3.1.2池化层池化层是夹在连续卷积层中间的,用于压缩数据和参数的量,减小过拟合。简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。 下采样层也叫池化层,其具体操作与卷积层的操作基本相同,只不过下采样的卷积核为只取对应位置的最大值、平均值等(最大池化、平均池化),即矩阵之间的运算规律不一样,并且不经过反向传播的修改。如图
2*2的kernel对4*4的数据进行扫描,每次移动两步,那么算出来的值也就是一个2*2大小的数据。 因此池化层的作用就是保证特征不变,因为每次都还是会采样,保留重要的特征,其次就是特征降维,当特征量太多,我们会选择将一些没有用的特征丢掉,只保留有用的特征。 3.1.3全连接层全连接层的 作用就是分类,具体描述在我上一篇博客,并且还附有代码。 3.2构建CNN与代码实现导入数据,并且查看数据,MINIST数据集包含train和test数据集,我们直接用train和test一个做训练集一个做测试集。 batch_size = 512 train_loader = torch.utils.data.DataLoader( torchvision.datasets.MNIST('mnist_data', train=True, download=True, transform=torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize( (0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader( torchvision.datasets.MNIST('mnist_data/', train=False, download=True, transform=torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize( (0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=False)这个时候文件夹会出现MNIST数据集文件,我们会发现,得到的并不是一系列图片,而是 .idx1-ubyte和.idx3-ubyte 格式的文件。这是一种IDX数据格式。如下图
查看输入tensor的shape(后面定义网络会用到),并且将数据集可视化,matplotlib.pyplot库支持直接对这些数据可视化。 x, y = next(iter(train_loader)) print(x.shape, y.shape, x.min(), x.max()) fig, axis = plt.subplots(4, 6, figsize=(15, 10)) images, labels = next(iter(train_loader)) for i, ax in enumerate(axis.flat): with torch.no_grad(): image, label = images[i], labels[i] ax.imshow(image.view(28, 28), cmap='binary') ax.set(title=format(label)) plt.show()
定义网络,根据卷积层--池化层--卷积层--池化层--全连接层连接方式定义, 每个网络都是继承nn.Module的, 对于第一次卷积层参数,由于输入数据集torch.Size([100, 1, 28, 28]),输入数据集通道为1,所以第一次卷积层kernel个数为1,kernel大小就定为5*5比较合适, 第二层的池化层需要将特征缩减为原来的一半,所以stride定为2, 第三层卷积层,由于上一层通道数为6,于是kernel个数为6,其他参数前文的网络结构图一致即可, 第四层跟第二层池化层同理 下一层全连接层输入的大小需要算一下,直接去主函数调用Cnn(),用torch.Size([b, 1, 28, 28])的tensor输入看输出的tensor的shape大小,得16*4*4,输入全连接层,最后输出10大小tensor即可。nn.Linear(in, out),参数表示输入维度,输出维度,是一个降维的过程,最终降到了维度为10 nn.ReLU(inplace=True),激活函数,数值小于某个值则变为0,舍弃,inplace=True变为0的值直接覆 盖,节省空间 class Cnn(nn.Module): def __init__(self): super(Cnn,self).__init__() self.conv_unit=nn.Sequential( nn.Conv2d(1,6,kernel_size=5,stride=1,padding=0), nn.AvgPool2d(kernel_size=2,stride=2,padding=0), nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0), nn.AvgPool2d(kernel_size=2, stride=2, padding=0), ) #fc unit self.fc_unit = nn.Sequential( nn.Linear(16*4*4,120), nn.ReLU(inplace=True), nn.Linear(120,84), nn.ReLU(inplace=True), nn.Linear(84,10) ) def forward(self,x): #param x:[512,1,28,28] batchsz = x.size(0) #[512,1,28,28]->[512,16,4,4] x=self.conv_unit(x) #[512,1,28,28]->[512,16*4*4] x=x.view(batchsz,16*4*4) #[512,16*4*4]->[512,10] logits = self.fc_unit(x) # #[512,10] # pred = F.softmax(logits,dim=1) # loss = self.criteon(logits,y) return logits初始化网络,并且打印出模型基本结构 model=Cnn() criteon = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=1e-3) print(model)
训练网络,并保存训练中的loss以及acc等 optimizer.zero_grad() 清空过往梯度; loss.backward() 反向传播,计算当前梯度; optimizer.step() 根据梯度更新网络参数 train_loss = [] Acc=[] for epoch in range(50): model.train() running_loss=0 for batchidx, (x, label) in enumerate(train_loader): # [b, 3, 32, 32] # [b] logits = model(x) # logits: [b, 10] # label: [b] # loss: tensor scalar loss = criteon(logits, label) # backprop optimizer.zero_grad() loss.backward() optimizer.step() running_loss += loss.item() train_loss.append(running_loss/len(train_loader)) print('epoch:',epoch+1, 'loss:', loss.item()) model.eval() with torch.no_grad(): # test total_correct = 0 total_num = 0 for x, label in test_loader: # [b, 3, 32, 32] # [b] # [b, 10] logits = model(x) # [b] pred = logits.argmax(dim=1) # [b] vs [b] => scalar tensor correct = torch.eq(pred, label).float().sum().item() total_correct += correct total_num += x.size(0) # print(correct) acc = total_correct / total_num Acc.append(total_correct / total_num) print('test acc:', acc)最后输出,test acc: 0.9549 可视化train的loss以及test的acc plt.plot(train_loss, label='Loss') plt.plot(Acc, label='Acc')
准确率不高,而且loss函数下降不平滑,改进网络 nn.BatchNorm2d(6),进行数据的归一化处理 class Cnn(nn.Module): def __init__(self): super(Cnn,self).__init__() self.conv_unit=nn.Sequential( nn.Conv2d(1,6,kernel_size=5,stride=1,padding=0), nn.BatchNorm2d(6), nn.ReLU(), nn.AvgPool2d(kernel_size=2,stride=2,padding=0), nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0), nn.BatchNorm2d(16), nn.ReLU(), nn.AvgPool2d(kernel_size=2, stride=2, padding=0), ) #fc unit self.fc_unit = nn.Sequential( nn.Linear(16*4*4,120), nn.ReLU(inplace=True), nn.Linear(120,84), nn.ReLU(inplace=True), nn.Linear(84,10) ) def forward(self,x): #param x:[512,1,28,28] batchsz = x.size(0) #[512,1,28,28]->[512,16,4,4] x=self.conv_unit(x) #[512,1,28,28]->[512,16*4*4] x=x.view(batchsz,16*4*4) #[512,16*4*4]->[512,10] logits = self.fc_unit(x) # #[512,10] # pred = F.softmax(logits,dim=1) # loss = self.criteon(logits,y) return logits再次训练,可视化
最后准确率epoch=15时,test acc: 0.9844,准确率提升了不少 3.3CNN结构模型数据流可视化 3.3.1tensorboardx可视化add_graph对结构模型可视化 writer = SummaryWriter('runs/cnn_mnist') dummy_input = torch.rand(512, 1, 28, 28) writer.add_graph(model,(dummy_input,)) writer.close()
可见在卷积层中有参数weight和bias,他们都与图片的shape有关,网络模型就是之前参照前文图片结构,如下
将保存的.pth文件用netron打开
每个神经层的shape都可以看见,还可以查看具体训练时的数据
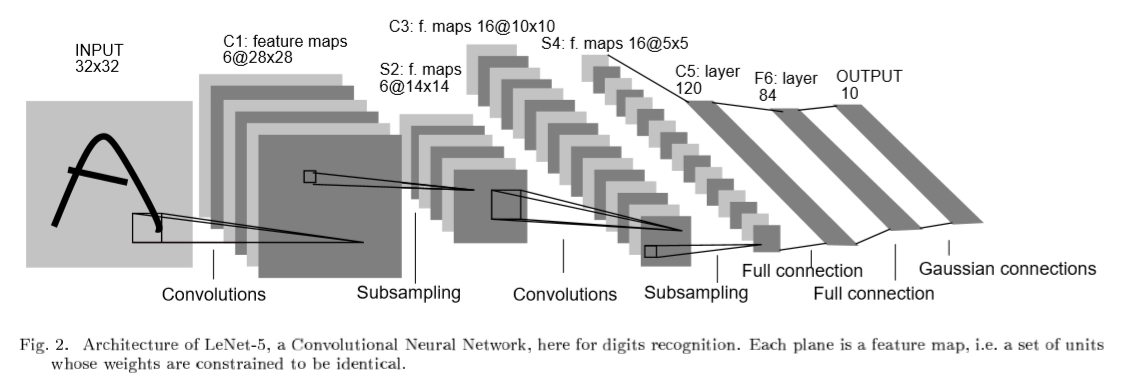
4.特征提取可视化 使用tensorboardx对每一层卷积的特征图进行可视化 writer = SummaryWriter('runs/cnn_mnist',comment='feature map') for i, data in enumerate(train_loader, 0): # 获取训练数据 inputs, labels = data x = inputs[1].unsqueeze(0) # x 在这里呀 break img_grid = vutils.make_grid(x, normalize=True, scale_each=True, nrow=2) model.eval() for name, layer in model._modules.items(): # 为fc层预处理x x = x.view(x.size(0), -1) if "fc" in name else x print(x.size()) x = layer(x) print(format(name)) # 查看卷积层的特征图 if 'layer' in name or 'conv' in name: x1 = x.transpose(0, 1) # C,B, H, W ---> B,C, H, W img_grid = vutils.make_grid(x1, normalize=True, scale_each=True, nrow=4) # normalize进行归一化处理 writer.add_image(format(name), img_grid, global_step=0)数字5第一次卷积
数字5第二次卷积
数字0第一次卷积
数字0第二次卷积
数字3第一次卷积
数字3第二次卷积
数字3的第二次卷积过后特征具有数字2 和1的特征(数字3这个模型只训练了几个epoch,可能是准确率不高),但是也可以反映特征被细化过后有些特征是会跟其他数字的特征一样 不同的数字第一次卷积,输出的通道为6,每个特征还是具有标识性,但是第一次卷积16个通道过后特征值就变得不那么具有标识性,也就是特征值被细化,于是可以可以从理论上得出在一定的神经深度下,堆叠网络层数是可以提高准确率的。 5.分析本次demo可以归纳为建模,调参,可视化,优化, 将已经分类好的数据[x,y]通过像素的方式输入到有预设参数的模型中,模型根据输入的数据,不停的优化自身的参数,类似线性函数不断拟合w和b一样,最终建立具有最优参数的模型。神经网络以及这些数据都是很抽象的,在学习深度学习中可视化跟建模一样重要。 模型也就是神经网络,里面的卷积层细化特征,而池化层是取样,取出有用的特征值,进而降维,再是用全连接层对特征值进行分类,其间包括归一化,激活函数等优化操作,之所以正确率会提高,主要是因为前向传播以及反向传播,不断的更新参数,而梯度的更新,归根揭底就是梯度下降算法。 在解决实际问题时,我们需要做的就是选取一个合理的模型,预设合理的参数,采用各种优化处理,最终达到想要的效果。 6.总结由于本人实力以及经验有限,有些理解有错,过后会加以改正,也希望看到的人跟我交流。 本次demo让我更加深刻的学习到了神经网络以及深度学习的原理,锻炼了实际操作的能力,确实期间遇到了不少的问题,刚开始的参数设置,可视化loss和acc,model,处理过拟合,都学到了不少东西,知道了优化器的不同会大幅度影响试验的结果,知道了表达实验结果最好的办法是可视化,熟悉了可视化的一些工具,知道dropout 正则化,更新学习率等方法来降低过拟合,合理更改模型结构有助于正确率的提高。 但是我对于深度学习的理解是完全不够的,思想方面也是有待提高,经验也不足,在可视化以及分析问题的时候花了不少时间,过后应该努力的改正思考问题的方式以及分析问题解决问题的速度,并且应该都和其他人交流意见别人的思想,每个人都有不同的思想,可能会让你很快解决一些问题。 |














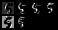



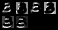

【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |