PaddleOCR |
您所在的位置:网站首页 › 怎样知道文件夹里有多少张图片和文字 › PaddleOCR |
PaddleOCR
|
简介
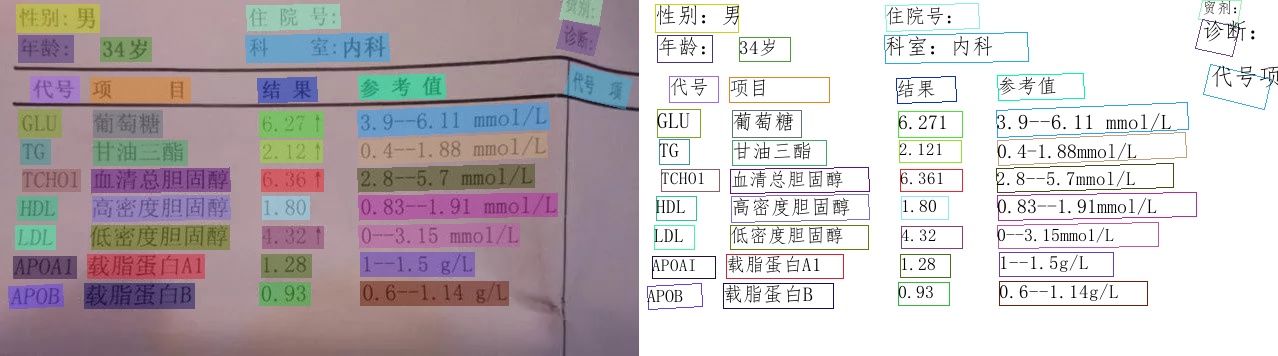
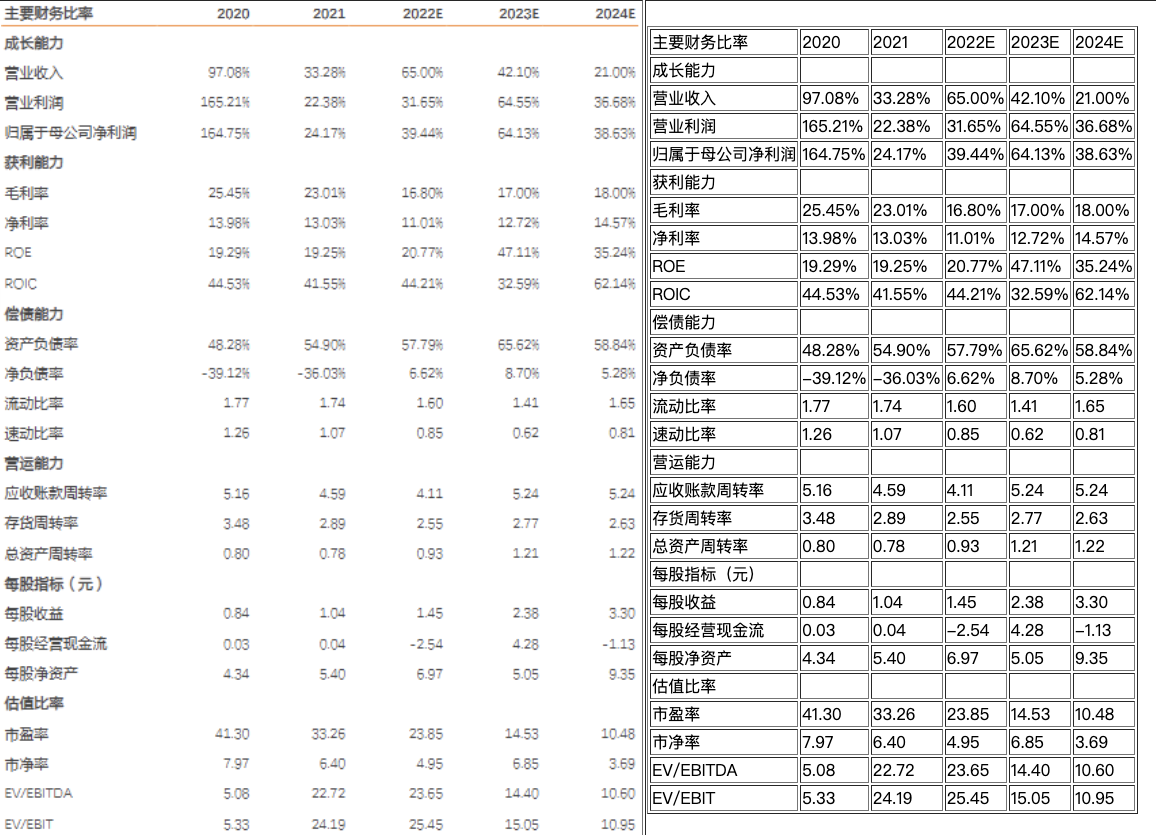
基于飞桨的OCR工具库,该项目名叫 PaddleOCR,是 Paddle 的一个分支;PaddleOCR 基于深度学习技术实现的, 所以使用时需要训练好的权重文件,但这个不需要我们担心,因为官方提供的有。包含总模型仅8.6M的超轻量级中文OCR,单模型支持中英文数字组合识别、竖排文本识别、长文本识别。同时支持多种文本检测、文本识别的训练算法。 官网地址: Gitee:PaddlePaddle: 源于产业实践的开源深度学习平台,飞桨致力于让深度学习技术的创新与应用更简单 (gitee.com) 经测试 PaddleOCR 识别效果非常优秀,下面两张图片是从官网介绍中截取的几张图片 PP-OCRv3 中文模型
PP-OCRv3 英文模型
PP-OCRv3 多语言模型
PP-Structure 文档分析
关于 PaddleOCR 模型 ,有以下几个特点 PaddleOCR 从 2020.5.14 发布,项目迭代到现在,功能一直处于在不断完善的过程;在 PaddleOCR 识别中,会依次完成三种任务:检测、方向分类及文本识别;关于预训练权重,PaddleOCR 官网根据提供权重文件大小分为两类: 一类为轻量级,(检测+分类+识别)三类权重加起来大小一共才 9.4 M,适用于手机端和服务器部署;另一类(检测+分类+识别)三类权重内存加起来一共 143.4 MB ,适用于服务器部署;无论模型是否轻量级,识别效果都能与商业效果相比,在本期教程中将选用轻量级权重用于测试;支持多语言识别,目前能够支持 80 多种语言;除了能对中文、英语、数字识别之外,还能应对字体倾斜、文本中含有小数点字符等复杂情况提供有丰富的 OCR 领域相关工具供我们使用,方便我们制作自己的数据集、用于训练 半自动数据标注工具;数据合成工具; PaddleOCR 使用简单介绍完之后,下面将手把手教大家怎么去使用 PaddleOCR, 本文主要介绍PaddleOCR wheel包对PP-OCR系列模型的快速使用 1 环境介绍介绍一下本次所用的测试环境 os:Win10;Python:3.7.11; 2 安装PaddlePaddle pip3 install --upgrade pip 如果您没有基础的Python运行环境,请参考运行环境准备。 python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple 您的机器是CPU,请运行以下命令安装 python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple 3 克隆 PaddleOCR 仓库下面用(1)或者(2),二选一 (1)用 git clone 命令或者 Download 把项目仓库直接下载到本地 git clone https://github.com/PaddlePaddle/PaddleOCR(2)安装PaddleOCR whl包(使用这个命令后面可跳过第5步) pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本 对于Windows环境用户:直接通过pip安装的shapely库可能出现[winRrror 126] 找不到指定模块的问题。建议从这里下载shapely安装包完成安装。这里我用的是 git 命令 4 安装PaddleOCR 第三方依赖包命令行进入 PaddleOCR 文件夹下 cd PaddleOCR安装第三方依赖项 pip3 install -r requirements.txt这一步骤如果报错的话,建议把改项目放置在一个虚拟环境中再进行安装,如果用虚拟环境的话,记得还需要安装一下 PaddlePaddle 包 python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple 5 下载权重文件权重链接地址分别贴在下方,需依次下载到本地;检测权重 https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar方向分类权重 https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar识别权重 https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar下载到本地之后分别进行解压,创建一个 inference 文件夹,把前面解压后的三个文件夹放入 inference 中,再把 inference 文件夹放入 PaddleOCR 中,最终树形目录结构效果如下:
以上环境配置好之后,就可以使用 PaddleOCR 进行识别了,在PaddleOCR 项目环境下打开终端,根据自己情况,输入下面三种类型中的一种即可完成文本识别 1,使用 gpu,识别单张图片 python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True2,使用 gpu ,识别多张图片 python3 tools/infer/predict_system.py --image_dir="./doc/imgs/" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True3,不使用gpu,识别单张图片 python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False里面有两个参数需要自己配置一下,参数说明: image_dir -> 为需要识别图片路径或文件夹;det_model_dir -> 存放识别后图片路径或文件夹;结果是一个list,每个item包含了文本框,文字和识别置信度 [[[28.0, 37.0], [302.0, 39.0], [302.0, 72.0], [27.0, 70.0]], ('纯臻营养护发素', 0.9658738374710083)] ...... 7 Python脚本使用通过Python脚本使用PaddleOCR whl包,whl包会自动下载ppocr轻量级模型作为默认模型。 检测+方向分类器+识别全流程 from paddleocr import PaddleOCR, draw_ocr # Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换 # 例如`ch`, `en`, `fr`, `german`, `korean`, `japan` ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory img_path = './imgs/11.jpg' result = ocr.ocr(img_path, cls=True) for idx in range(len(result)): res = result[idx] for line in res: print(line) # 显示结果 # 如果本地没有simfang.ttf,可以在doc/fonts目录下下载 from PIL import Image result = result[0] image = Image.open(img_path).convert('RGB') boxes = [line[0] for line in result] txts = [line[1][0] for line in result] scores = [line[1][1] for line in result] im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf') im_show = Image.fromarray(im_show) im_show.save('result.jpg')结果是一个list,每个item包含了文本框,文字和识别置信度 结果可视化
Paddle-OCR 属于Paddle 框架其中的一个应用,Paddle 除了 OCR 之外还有许多其它好玩的模型,关键开发者提供有训练好的预权重文件、降低了使用门槛。 下期讲一下表格识别 ppstructure 算法 参考:PaddleOCR,一款文本识别效果不输于商用的Python库! - 知乎 (zhihu.com) |






【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |