从图片或PDF文件识别表格提取内容的简单库img2table |
您所在的位置:网站首页 › 怎么可以提取图片中的表格 › 从图片或PDF文件识别表格提取内容的简单库img2table |
从图片或PDF文件识别表格提取内容的简单库img2table
|
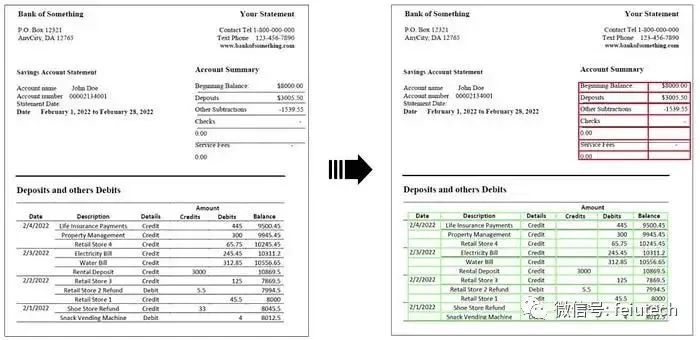
img2table是一个基于OpenCV 图像处理的用于 PDF 和图像的表识别和提取 Python库。由于其设计基于神经网络的解决方案,提供了一种实用且更轻便的替代方案,尤其是在 CPU 上使用时。 该库的特点: 识别图像和PDF文件中的表格,包括在表格单元级别的边界框。 通过支持OCR服务/工具(Tesseract、PaddleOCR、AWS Textract、Google Vision和Azure OCR目前支持)来提取表格内容。 处理复杂的表格结构,如合并单元格。 实现纠正图像的倾斜和旋转的方法。 提取的表格以一个简单的对象形式返回,包括一个Pandas DataFrame表示。 将提取的表格导出为Excel文件的选项,保留其原始结构。 支持的文件格式 图像 支持的图像格式,不支持多页图像。 PDF格式支持本机和扫描的 PDF 文件。 一、安装 pip install img2table#标准安装支持Tesseractpip install img2table[paddle]#用于Paddle OCRpip install img2table[easyocr]#用于 EasyOCRpip install img2table[gcp]#用于 Google Vision OCRpip install img2table[aws]#用于 AWS Textract OCRpip install img2table[azure]#用于 Azure 认知服务 OCR二、使用 图像文件实例化如下: from img2table.document import Image image = Image(src,detect_rotation=False) """说明参数src :str或bytes 或pathlib.Path或BytesIO,图片文件格式detect_rotation:bool,可选,默认False,检测并纠正图像的倾斜/旋转"""PDF文件 from img2table.document import PDF pdf = PDF(src, pages=[0, 2], detect_rotation=False, pdf_text_extraction=True) """参数说明src : str或bytes 或pathlib.Path或BytesIO,PDF文件格式pages : 列表, 可选, 默认None。要处理的 PDF 页面索引列表。如果为 None,则处理所有页面detect_rotation:bool,可选,默认False,检测并纠正从 PDF 中提取的图像的倾斜/旋转pdf_text_extraction:bool,可选,默认True,从原生 PDF 的 PDF 文件中提取文本"""三、OCR img2table为多个 OCR 服务和工具提供接口,以便解析表内容。 如果可能(即对于原生 PDF),将直接从文件中提取 PDF 文本,并且不会调用 OCR 服务/工具。以Tesseract为例 from img2table.ocr import TesseractOCR ocr = TesseractOCR(n_threads=1, lang="eng", psm=11, tessdata_dir="...")四、表提取 使用文档的方法可以从 PDF 页面/图像中一次提取多个表格。使用类方法extract_tables返回 from img2table.ocr import TesseractOCRfrom img2table.document import Image # Instantiation of OCRocr = TesseractOCR(n_threads=1, lang="eng") # Instantiation of document, either an image or a PDFdoc = Image(src) # Table extractionextracted_tables = doc.extract_tables(ocr=ocr, implicit_rows=False, borderless_tables=False, min_confidence=50)"""参数说明ocr :OCRInstance,可选,默认None用于解析文档文本的 OCR 实例。如果为 None,则不会提取单元格内容implicit_rows:bool,可选,默认False指示是否应标识隐式行的布尔值 - 检查相关示例borderless_tables:bool,可选,默认False指示是否在有边框表的顶部提取无边框表的布尔值。min_confidence:int、可选、默认50OCR 处理文本的最低置信度,从 0(最差)到 99(最好)""" ExtractedTable 类用于对从文档中提取的表进行建模。 属性bbox:BBox,表边界框title : str,提取的表标题content : OrderedDict,以行索引为键,以对象列表为值的字典TableCelldf : pd.DataFrame,表的 Pandas DataFrame 表示形式html : str,表格的 HTML 表示形式五、返回提取结果 图像 Image类的extract_tables方法返回ExtractedTable对象的列表。 output = [ExtractedTable(...), ExtractedTable(...), ...]PDF格式 PDF类的extract_tables方法返回一个OrderedDict对象,该对象将页面索引作为键和ExtractedTable对象的列表。 output = { 0: [ExtractedTable(...), ...], 1: [], ... last_page: [ExtractedTable(...), ...]}Excel 导出 从文档中提取的表格可以导出为 xlsx 文件。生成的文件由每个提取的表的一个工作表组成。 方法参数在方法中很常见。 from img2table.ocr import TesseractOCRfrom img2table.document import Image # Instantiation of OCRocr = TesseractOCR(n_threads=1, lang="eng") # Instantiation of document, either an image or a PDFdoc = Image(src) # Extraction of tables and creation of a xlsx file containing tablesdoc.to_xlsx(dest=dest, ocr=ocr, implicit_rows=False, borderless_tables=False, min_confidence=50)
github:https://github.com/xavctn/img2table |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |