当当网销售数据的爬取与可视化分析 |
您所在的位置:网站首页 › 当当网图书销售排行榜 › 当当网销售数据的爬取与可视化分析 |
当当网销售数据的爬取与可视化分析
|
一、课题背景和意义 1.选题背景 伴随着互联网的兴起和网络技术的快速发展,越来越多的人能够接触并使用网络导致近几年来电子阅读设备,如智能手机、kindle等的兴起导致线上读书人数激增。纸质书籍曾经与我们的工作和生活息息相关、密不可分,但电子阅读设备给人们的生活所带来的变化不可比拟,线上阅读逐渐成为趋势。 电子书阅读给人们阅读方式、认知模式与思维习惯带来了改变,疫情期间,电子书阅读的快速增长,也再次引发人们对相关问题的思考。电子书与纸质书各有什么优势,二者能否长期共存,这些问题都有待探讨。 《2019年度中国数字阅读报告》数据显示,当年中国数字阅读行业市场整体规模达到288.8亿元,增长率为13.5%,总体用户规模达4.7亿,反映出读者对数字阅读的认可度与欢迎度日益提升。海量线上资源让电子书阅读有了“底气”。疫情期间,各图书馆、出版机构、网络阅读平台上线开放大量电子书资源,让人们看到“云阅读”的广阔前景。国家图书馆宣布无论有无读者卡,读者均可在闭馆期间远程访问图书、期刊、报纸、论文、古籍等多种类型的数字资源;商务印书馆向社会免费开放1300余种电子书资源和“汉译名著名家视频导读”26种共125集视频;人民文学出版社免费开放“人文读书声”有声店铺中的资源,并联合阅文、掌阅、京东、当当等数字平台免费提供电子书。今年4月,“2020年中国数字阅读云上大会”上发布的数据显示,战疫期间,各大主要数字阅读平台累计免费提供作品超100万本,音频超40万个。 在互联网的推动之下,电商平台飞速发展,图书线上销售占比提高,当当、抖音、京东、淘宝等电商平台中都设计图书消费板块。在此背景之下爬取并分析当当网图书销售数据能够帮助大众了解当下人们对于图书的喜好程度以及当下图书的热门卖点。 2.研究现状 自1993年初 Matthew Gray’s Wandered 在麻省理工学院开发出有史记载的第一个网络爬虫以来,爬虫技术历经20多年的发展,技术已日趋多样。但是同时随着爬虫的不断壮大发展,各大网站反爬虫的机制也在不断完善。对于当当网来说,网络当中很多绕过当当网爬虫检测的方法也大多已经失效。因此找到一种稳定的爬取方法是有必要的。同时当下网络中针对当当网商品详情页面爬取的资料也很少,大多数人也只是爬取了搜索之后的基本信息。因此本设计将会更加详细的爬取当当网图书的销售数据。 其次,尽管目前爬虫的发展形势一片火热,数据分析也正处于时代的浪潮之上,针对当当网图书销售数据这一方面,对于这部分数据的爬取与分析也并不是十分的详尽,而能够将二者结合在一起的讨论的实际上并不是很多。因此将当当网手机的销售数据的爬取与分析放在一起讨论虽然无法做到尽善尽美,但实际在一定程度上做到了对目前当当图书信息的爬取与数据分析两个方面知识与实际操作的更新、补充与整合。 3.课题意义 在如今这个数据信息充斥着我们生活的各个角落的时代,若将数据的爬取与分析分开来看,这二者都有无数前人做出了数不胜数的研究,网络中也有各种各样的文献与教程。但是,实际在现实生活中却很少有人能够将这二者结合运用起来帮助消费者做出决策,帮助商家做出更合理的进货与标价。 综上所述,当当网销售数据的爬取与可视化分析的意义包括以下方面: (1)帮助消费者清楚的了解市场中图书的销售情况。 (2)帮助消费者了解市场中销量领先的图书类型。 (3)帮助消费者更好的根据预算以及当下当当网图书销售情况选购图书。 (3)帮助商家根据图书售卖情况了解目前市面上热门图书类型。 二、设计内容 当当网图书数据的爬取与可视化分析大体分为四个方面: (1)数据爬取: 使用Python的requests模块编写网络爬虫,爬取的目标选取当当网历史销售排行,爬取的时间范围是2018年至2021年。首选在当当网销售排行榜界面下将所有上榜的图书链接爬取到本地,再一次将所有链接遍历爬取,将可用的信息存入本地数据库,以便下一步分析使用。 (2)数据清洗: 根据爬取数据的类型,将各类数据的格式进行修正,删除重复数据,修补缺失数据,最终得到可以直接用于分析使用的数据,并保存到本地数据库中。 (3)数据分析: 从合并的数据集中提取所需数据形成子表格进行分析。将数据以及分析结果用PyEcharts绘制图像实现可视化。 (4)Django框架集成可视化结果:使用Django Web框架集成可视化结果,便于查看当当网图书销售的统计数据和销售数据的分析结果。 三、设计方案 (一)设计流程 当当网图书销售数据的爬取与可视化大体分为三个阶段: 1. 需求分析 (1)技术需求:使用Python作为爬虫语言的原因是在于Python拥有强大的网络功能。使用requests库和ip代理池绕过当当网的反爬机制。使用Pyecharts对数据进行可视化展示。 (2)数据内容:分析所需数据包含图书的排名、图书的封面、图书名字、图书价格、图书的评论数量、图书类型、图书作者、图书出版社等。 (3)数据爬取量:由于存在重复商家和图书,因此只针对历年图书销售排行榜上的图书进行爬取。 (4)数据可视化分析结果:充分利用已爬取的图书销售数据,分析当下图书销售的趋势。 2. 数据爬取、数据分析与可视化展示 (1)分析网页:从网页中找出自己所需数据的位置,分析子网页,找出不同子网页之间的不同点,便于之后深爬。 (2)网页爬取:使用requests第三方库结合ip代理池爬取各个图书详情页。使用lxml解析网页获取所需数据。 (3)数据保存:将数据保存在本地mysql数据库中以便后续分析使用。 (4)数据清洗:去除重复数据,对缺失值进行填充,将数据格式统一化。 (5)数据可视化:使用PyEcharts 绘制饼状图、柱状图、词云图等一系列可视化图像实现数据可视化。 (6)Django框架集成:使用Django Web框架对可视化数据进行整合,便于查看。 3.系统测试和异常处理 程序运行过程中难免会出现错误,使用try,except等方法捕获异常,并使程序在出现异常时能够继续正常运行,必要时通过人为制造错误情况测试系统对错误操作、错误报文的反应,检查程序中的屏幕或页面是否给出了清晰且充分的提示或约束。 当当网图书销售数据爬取流程图如图1所示
图1 当当网图书销售数据爬取流程 (二)设计条件与开发环境 1.已具备开发该系统所需的专业知识、Python编程能力和数据可视化技术、项目设计能力和开发经验。 2.使用Windows下的PyCharm作为爬虫开发平台。 3.编程语言:Python,JavaScript。 4.相关包与函数库:requests,lxml,retry,,pymysql,re,time,Django,PyEcharts等。 四、预期成果 1.“当当网销售数据的爬取与可视化分析”软件一套。 2.符合规范的《毕业设计说明书》。 进度安排2021.01.08-2021.02.20:搜集整理资料,系统需求调研 2021.02.21-2021.03.09:制订设计方案,撰写开题报告 2021.03.10-2021.03.24:爬取所需数据、进行数据预处理和数据分析 2021.03.25-2021.04.13:Web页面及框架的设计,实现Web展示 2021.04.14-2021.05.19:测试与完善,撰写毕业设计说明书初稿 2021.04.20-2021.05.23:完善说明书,查重检测 2021.05.24-2021.05.28:撰写答辩稿,制作答辩PPT 2021.05.29-2021.05.30:毕业答辩 2021.05.31-2021.06.07:刻录材料光盘,提交签名版毕业设计说明书 六、参考文献 [1] 温佐承, 贾雪. 基于Python的网络爬取[J]. 电脑编程技巧与维护, 2020,(12): 23-24+32. [2] 欧阳元东. 基于Python的网站数据爬取与分析的技术实现策略[J]. 电脑知识与技术, 2020,16(13): 262-263. [3] 李玉香, 王孟玉, 涂宇晰. 基于python的网络爬虫技术研究[J]. 信息技术与信息化, 2019(12): 143-145. [4] 张昊. “电商造节”中的微观价格行为及竞争效应[J]. 财贸经济, 2018, 39(11): 128-144. [5] 陈嘉发. Python数据可视化的应用研究[J]. 福建电脑, 2019, 35(05): 114-116. [6] 叶文. Python语言基于网络学习的数据分析及可视化初探[J]. 轻工科技, 2020, 36(05): 57-58. [7] 冯艳茹. Python语言在大数据分析中的应用[J]. 电脑知识与技术, 2020, 16(24): 72-73+80. [8] 尤天琪, 冯思毓, 周陈雯淑, 等. 电商数据的爬取及价格模型的建立[J]. 信息与电脑(理论版), 2019, 31(17): 138-140+143. [9] 迪米特里斯·考奇斯-劳卡斯. 精通Python爬虫框架Scrapy[M]. 北京: 人民邮电出版社, 2018. [10]黑马程序员. JavaScript前端开发案例教程[M]. 北京: 人民邮电出版社, 2018. [11]王娟, 华东, 罗建平. Python编程基础与数据分析[M]. 南京: 南京大学出版社, 2019. [12]蔡沂. Web前端开发简明教程[M]. 北京: 人民邮电出版社, 2017. [13]李培. 基于Python的网络爬虫与反爬虫技术研究[J]. 计算机与数字工程, 2019, 47(06): 1415-1420+1496. [14]许景贤, 林锦程, 程雨萌. Selenium框架的反爬虫程序设计与实现[J]. 福建电脑, 2021, 37(01): 26-29. [15]翟普. python网络爬虫爬取策略对比分析[J]. 电脑知识与技术, 2020, 16(01): 29-30+34. [16]常逢佳, 李宗花, 文静, 等. 基于Python的招聘数据爬虫设计与实现[J]. 软件导刊, 2019, 18(12): 130-133. [17]关丽梅. Python中用多线程爬取网页图像的好处[J]. 信息与电脑(理论版), 2020, 32(22): 63-65. [18]杨登, 袁芳. 基于Python爬虫的数据分析[J]. 中国新通信, 2020, 22(18): 76-77. [19]Ashwin Pajankar. Practical Python Data Visualization [M]. Berkeley Apress, 2021
|


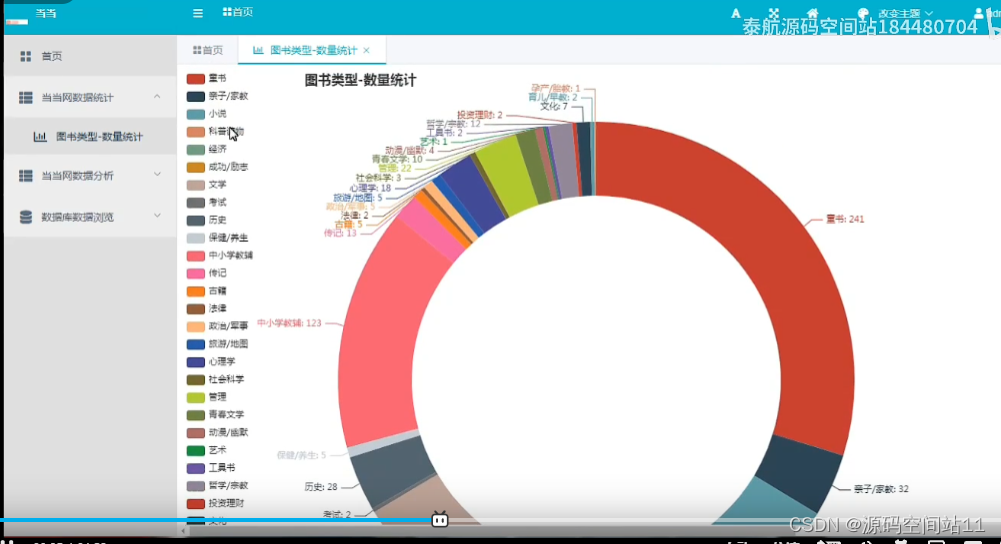 【计算机毕设之基于Django的当当网爬虫数据分析系统】 https://www.bilibili.com/video/BV1DL4y1u7Y2/?share_source=copy_web&vd_source=3d18b0a7b9486f50fe7f4dea4c24e2a4
【计算机毕设之基于Django的当当网爬虫数据分析系统】 https://www.bilibili.com/video/BV1DL4y1u7Y2/?share_source=copy_web&vd_source=3d18b0a7b9486f50fe7f4dea4c24e2a4
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |