【多模态】24、开放词汇学习到底是什么? |
您所在的位置:网站首页 › 开放大世界是啥意思 › 【多模态】24、开放词汇学习到底是什么? |
【多模态】24、开放词汇学习到底是什么?
|
文章目录
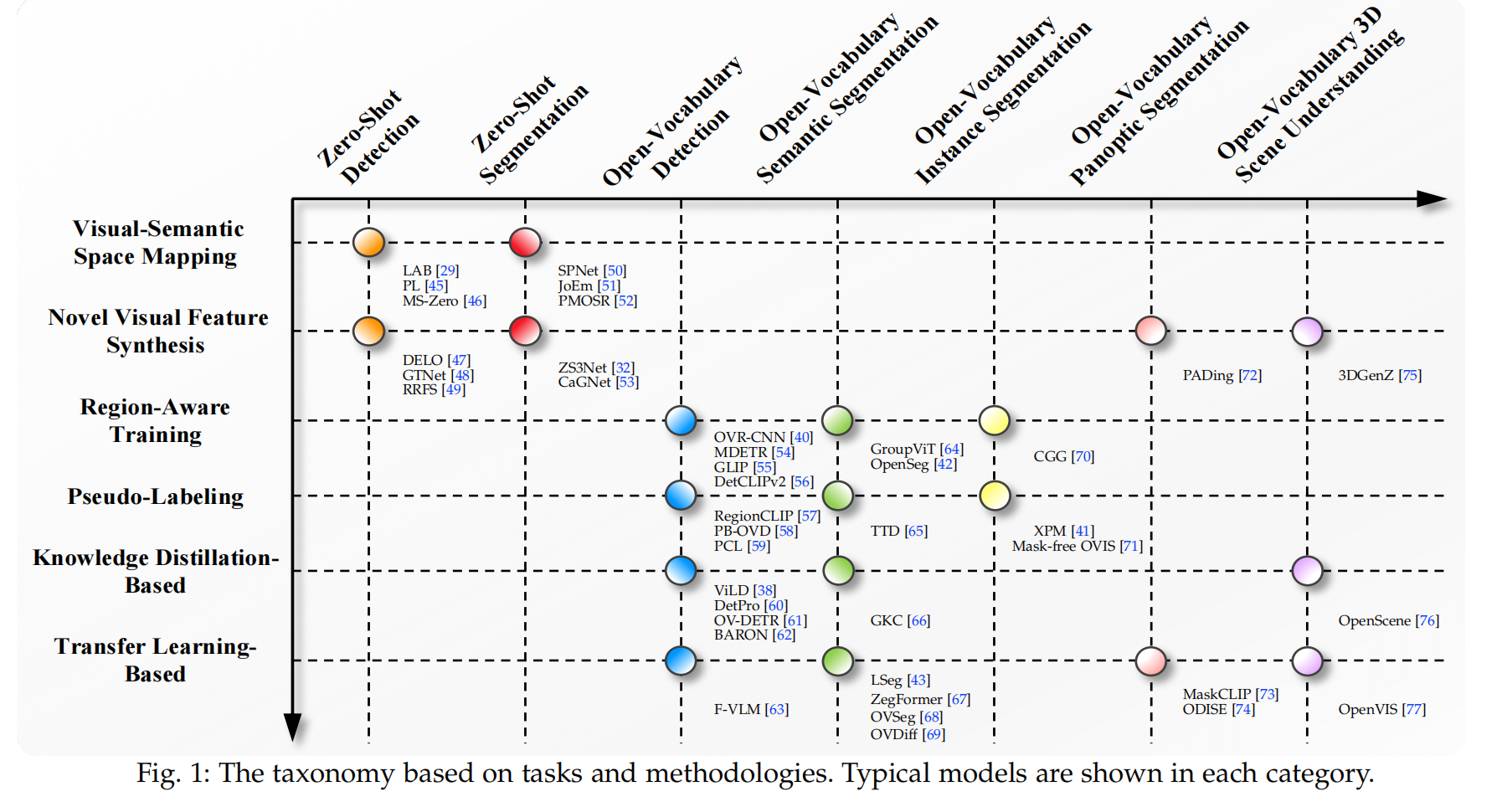
一、什么是开放词汇学习二、开放词汇学习的测评和数据集三、开放词汇目标检测3.1 Region-Aware Training3.2 Pseudo-Labeling3.3 Knowledge Distillation-Based3.4 Transfer Learning-Based3.5 总结3.6 效果
参考论文:A Survey on Open-Vocabulary Detection and Segmentation: Past, Present, and Future
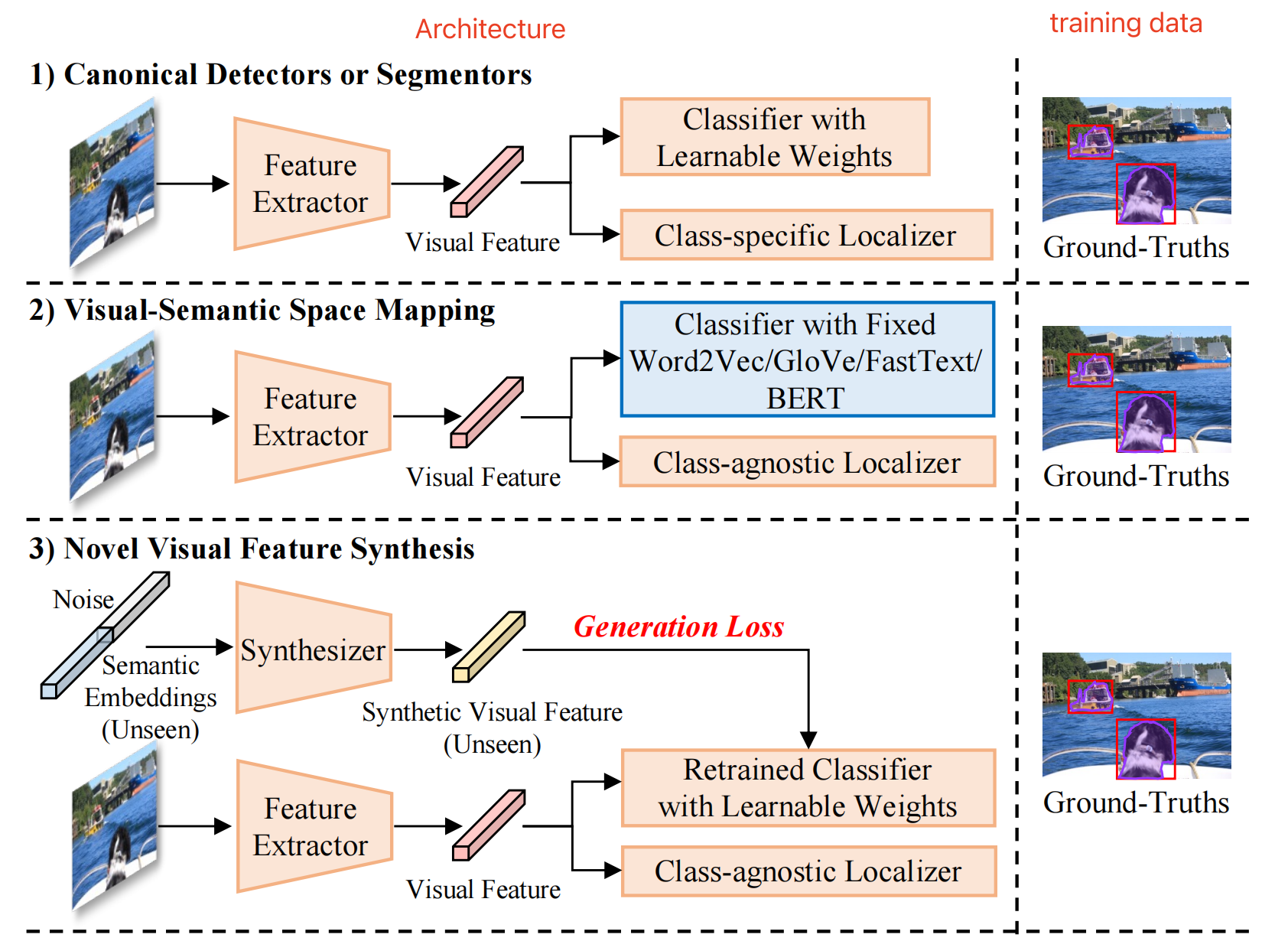
与开放词汇相对的就是封闭词汇,封闭词汇检测和分割等任务就是在固定的类别上来实现对目标的检测和分割 在探讨开放词汇学习之前,有必要提一下 zero-shot learning 在干一件什么事情 zero-shot 是零样本的意思,就是说在别的类别(base)上训练过的目标,可以直接识别没见过的类别(unseen),比如 zero-shot detection (ZSD) 和 zero-shot segmentation (ZSS) 这里有一个很严的限制:unseen 类别在训练中一定是不可见的!!! zero-shot 是怎么实现的呢: 使用一个固定的类别编码器来代替分类器,如 Word2Vec、BERT 等,能够通过这些固定的类别编码器从 base 类别扩展到对 unseen 类别的理解zero-shot 的问题: zero-shot 是很受限制的,因为 unseen 的类别在训练中是没有见过的,就算出现了也只是被当做背景,所以这些类别的 visual 信息和 text 信息也很难对齐,很难建立真正的联系,所以 zero-shot 在 unseen 类别上的表现也不是很好所以衍生出了开放词汇 open-vocabulary 这个任务 开放词汇也可以理解为条件较为宽松的 zero-shot,因为没有了在训练中一定要 unseen 的这个严格限制,因为预训练中会见过各种各种的目标,无法保证也不需要保证这些类别一定 unseen,因为预训练的目的就是要实现见多识广,才有利于在下游任务的泛化 开放词汇学习怎么实现的呢: 使用弱监督信号(image-caption、image-level label)或 vision-language models (如 CLIP)来解决 closed-set 问题来自 VML 的 text encoder 已经见过了非常多的 image 和 text,有很强了能力将它们对齐,因为在数以万计的数据中基本上包含了所有常见的目标和文本,所以其有很强的能力能实现将 unseen 的目标关联到对应的类别编码上(这里的 unseen 仅仅指的是目标检测数据中没有的类别,不能保证 image-caption 中没有见过)总的来说,zero-shot 和 open-vocabulary 是两个不同的问题,其关键的区分在于是否使用的弱监督信号(image-text pairs) 但其实 zero-shot(ZSD/ ZSS)可以分为如下两个不同的类型: visual-semantic space mapping:视觉-语义空间映射 因为视觉和语义是两个模态,所以无法直接在一个模态下挖掘两个空间的关联信息,所以需要将视觉映射到语义空间,或者把语义映射到视觉空间,或者影视到一个视觉-语义新空间来实现 具体的实现方法可以简单概括为:使用固定的语义编码器(BERT 等) + class-agnostic 定位器 novel visual feature synthesis:新视觉特征合成 由于缺少对 unseen 类别的标注,所以 unseen 类别的执行得分一般会被 seen 类别盖过,为了解决这种不平衡,一些方法使用额外的 generative model 来合成假的 unseen visual feature
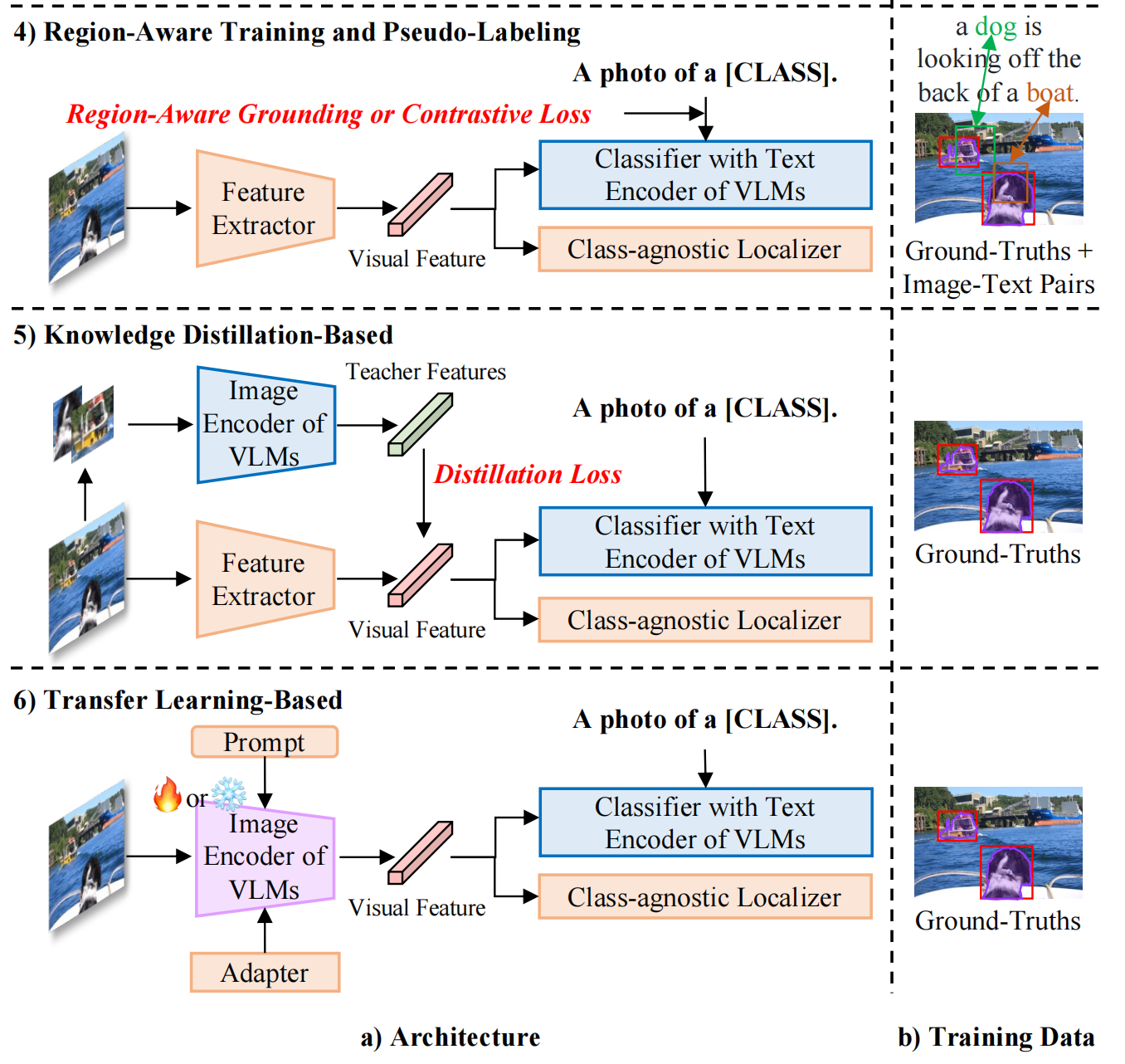
open-vocabulary 检测和分割方法目前可以大致分为如下四种: Region-Aware Training: 使用的数据:image-caption pairs,region-caption pairs 使用的模型:会使用 VLM 的 text encoder 来提取 text 的编码 目标:使用 image-caption pairs,提取 region-caption pairs,使用对比学习来将同一对儿的 region-caption 拉近,不同对儿的 region-caption 推远,region-aware loss 可以学习 region 和 text 之间的关系 Pseudo-Labeling: 使用的数据:会使用除 gt 外的 image-text pairs,即 region 伪标签数据,也就是使用 VLM 作为 teacher 模型来实现对 region 的 text 标签生成,来作为伪标签数据 目标:使用生成的 region-text 伪标签来作为 bbox 标签,训练模型对 region 和 text 的对齐能力 特点:不需要使用 VLM 的 image encoder Knowledge Distillation-Based VLM 模型(如 CLIP)已经经过了大量的 image-text pairs 训练,有了一定的图像-文本特征提取和对齐能力,所以这些方法就想借用预训练的 CLIP 模型的 image encoder,将其学习到的知识蒸馏到 student encoder 上 特点:不需要在 image-text 上训练,但需要 VLM 的 image encoder Transfer Learning-Based 由于蒸馏的方法需要将每个 RoI(图像层面)重复的经过 VLM image encoder 来进行特征提取,从而知道 student visual encoder 的学习,资源耗费很大 transfer learning 的方法使用下面几个不同的方法来实现: 冻结 VLM image encoder 作为特征提取器在下游任务上 fine-tuning VLM image encoder冻结 VLM 然后在 gt 上训练可学习的 visual prompt在 VLM 冻结的 image encoder 后接一个轻量级的 adapter
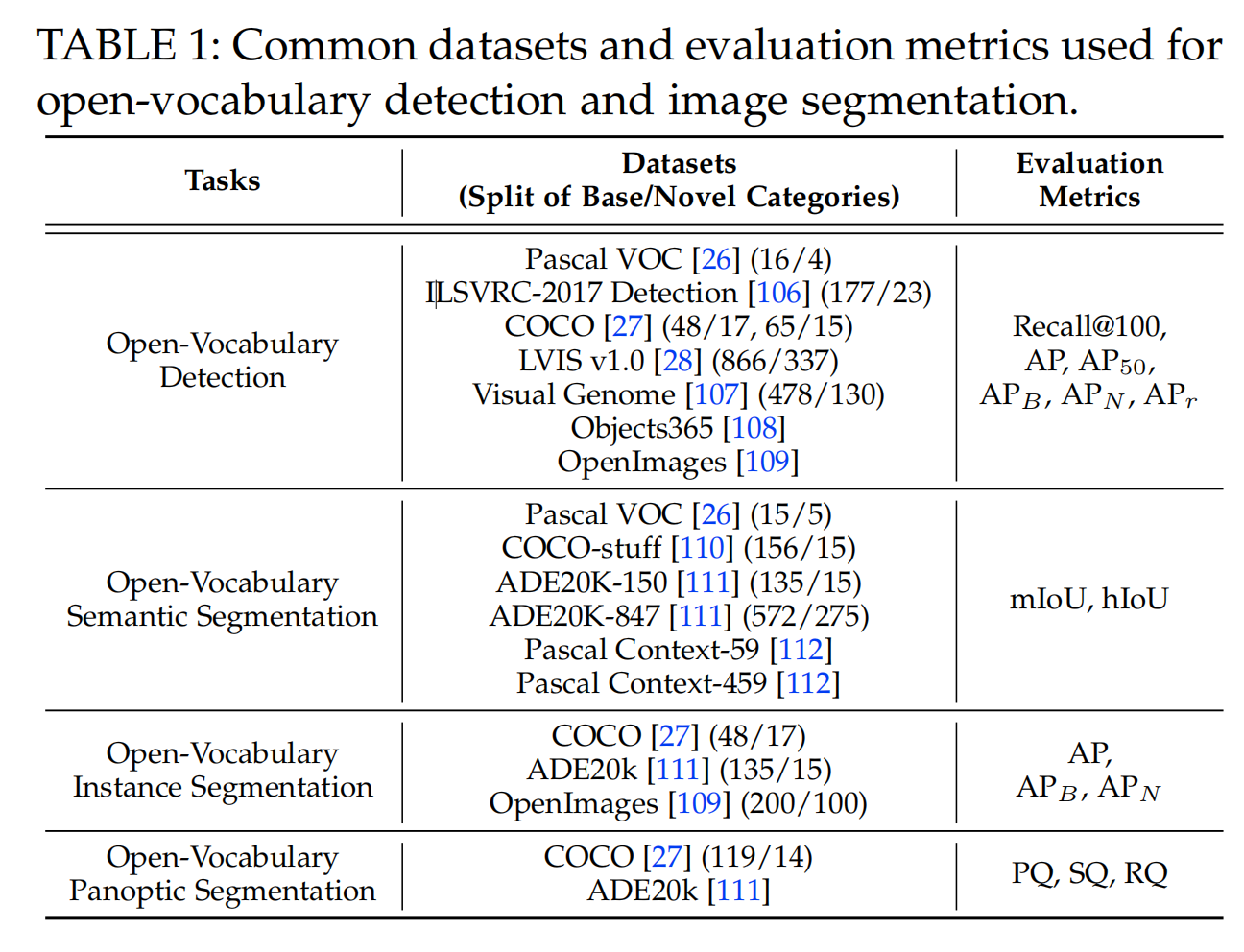
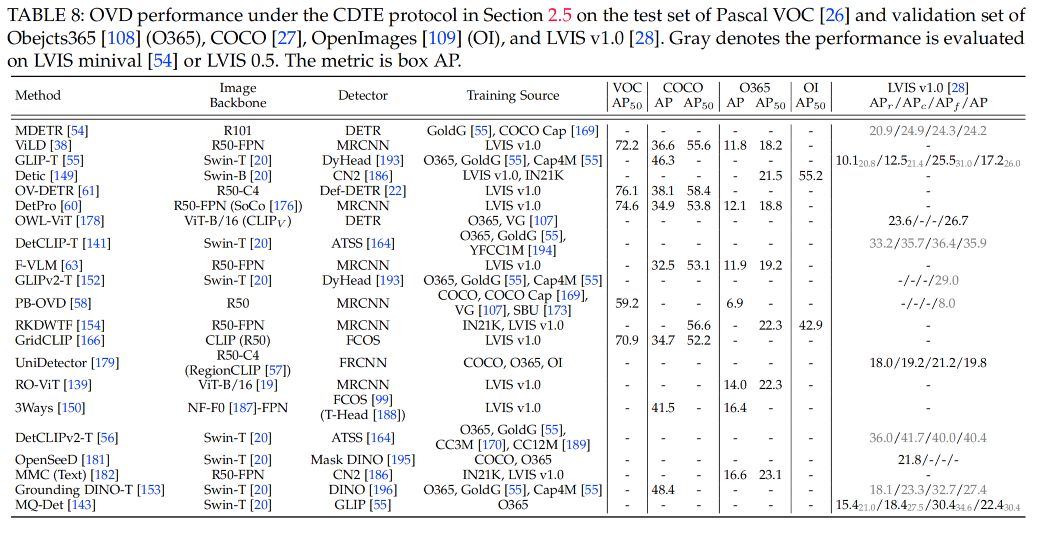
开放词汇检测或分割有三个测评方式: open-vocabulary evaluation (OVE),只在新类别上测试效果generalized open-vocabulary evaluation (gOVE), 同时在 base 类和新类上测试效果,这个更有挑战性,因为模型会更偏向于 base 类cross-dataset transfer evaluation (CDTE),模型在一个数据集上训练,在另一个数据集上测试,如在 LVIS 上训练,在 COCO 上测试测评指标: 目标检测和实例分割:box mAP 和 mask mAP,IoU 阈值为 0.5语义分割:mIoU,基础类和新类的 harmonic mean (HM) 是 hIoU全景分割:Panoptic quality (PQ), segmentation quality (SQ), recognition quality (RQ)
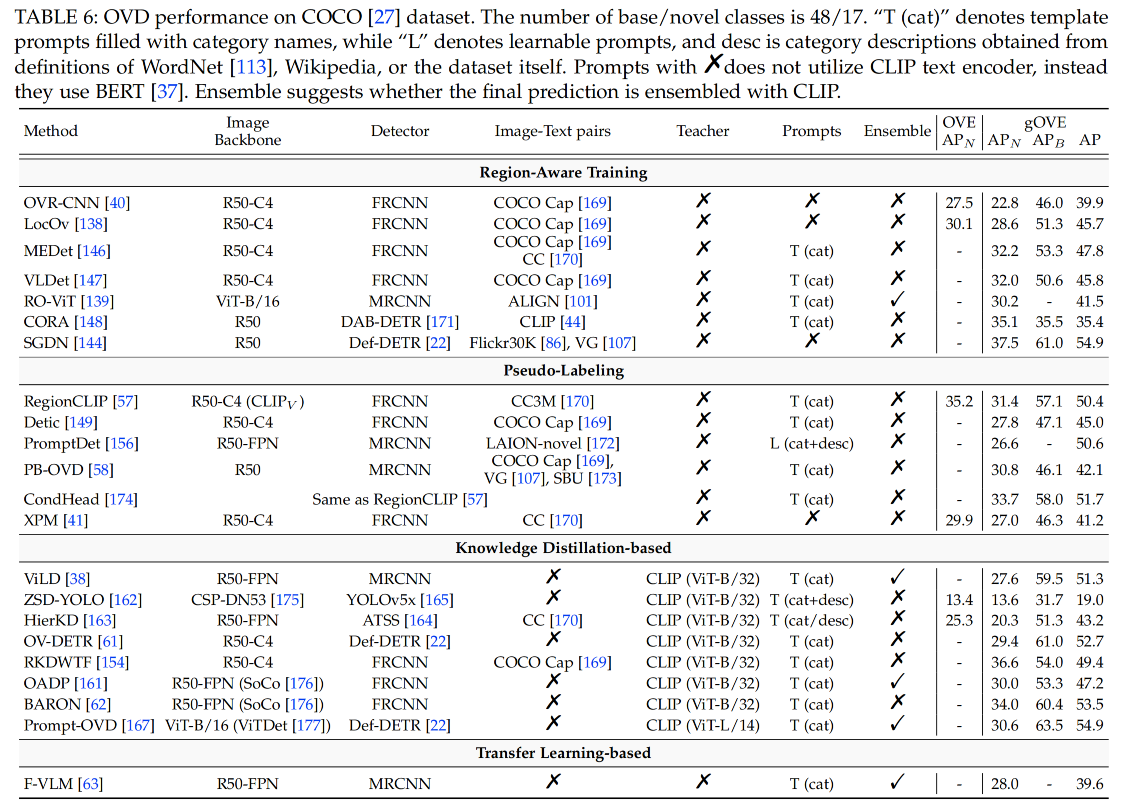
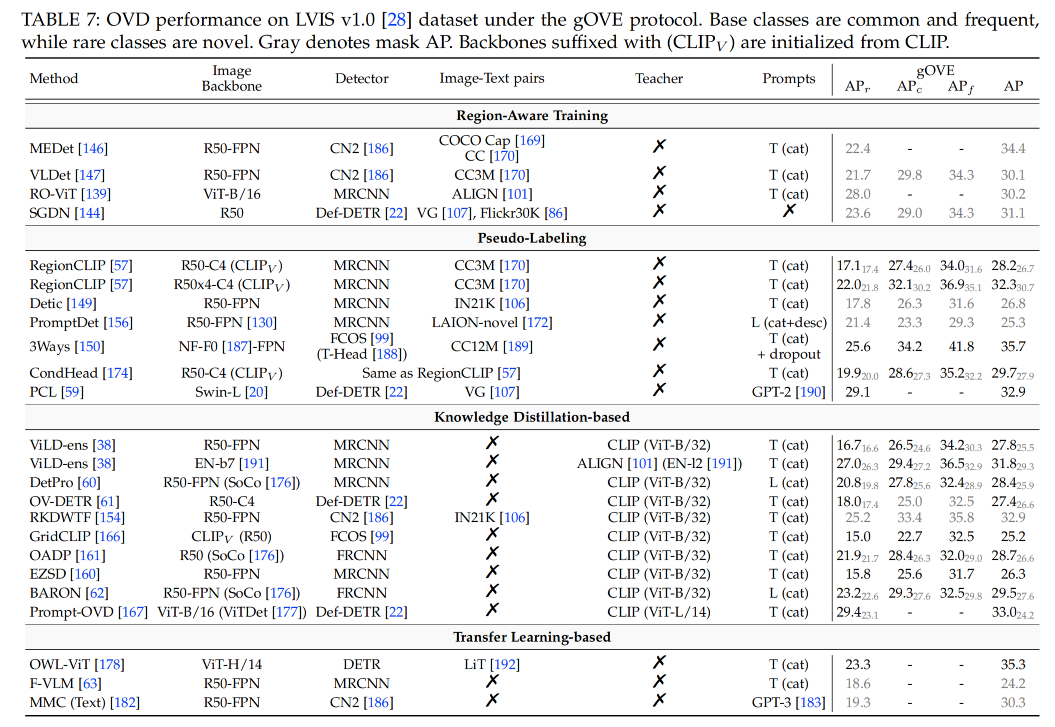
1、weakly-supervised grounding or contrastive loss 不借用任何视觉-语言基础模型(VMLs),而是使用 image-caption 数据来学习其映射关系,或借用 grounding 数据来扩充词汇丰富性 这类方法使用 image-text pairs 来建立带有噪声的 region-words 关联关系,训练期间会衡量每个 proposal 和 sentence 中的每个 word 的相关性,然后使用 grounding 或 contrastive loss 来将正样本对儿拉进,负样本对儿推远 OVR-CNN:首先建立了开放词汇检测的任务,之前的 ZSD 方法只会在 base 类上从头开始训练 visio-to-language(V2L)mapping layer,但这样会过拟合,所以[40] 提出在预训练时候使用丰富的数据来训练 V2L 模块。OVR-CNN 是从 zero-shot 过渡到开放词汇检测的第一篇工作,提出了使用大量的 image-caption 来学习文本和图像的映射关系,即学习 V2L,来建立一个粗糙的 region-text 的关联性,然后使用预训练后的 ResNet 和 V2L 来初始化检测器,固定 V2L ,训练 ResNet LocOv:follow OVR-CNN 的思想,在对比学习 loss 的基础上增加了辅助 image-text matching loss 和 masked language modeling loss(MLM) RO-ViT:随机 crop 并 resize positional embedding,使用 focal loss 而非 softmax 来提升负样本的权重,而且使用了更好的 proposal network OLN DetCLIP:构建了一个很丰富的 concept dictionary,来实现并行的 concept formulation,避免了不必要的类别之间关系 2、Ground-Truth Region-word Correspondence 这类方法主要使用 visual grounding 数据集中的 gt region-word pairs 来扩充 vocabulary,而不会借用预训练好的 VLMs MDETR 结合了 Flickr30K [86], Visual Genome (VG) [107], ReferItGame [85], and RefCOCO/+/g 组成了数据集,包含 1.3M 个真实对齐的 region-text pairs GLIP 也使用了 MDETR 中提到的数据集 MAVL 使用多尺度 deformable attention 和 late fusion 来提升 MDETR 的效果 MQ-Det 对 GLIP 中的 language queries 进行数据增强 SGDN 同样使用 Flickr30K 和 VG 数据集,但使用了额外的 scene graph 中的目标关联来提升分类、定位新类别目标的效果 3、其他 MEDet 通过 concept augmentation 来在线挖掘 region-word 的关系 VLDet 将 region-word 对齐的问题重构成了 set-matching 问题,可以通过 off-the-shelf Hungarian algorithm 来实现 image-caption pair 的自动学习 CORA 使用可学习的 prompt 来增强 region features,让其能更好的和 CLIP visual-semantic 空间对齐 当前 CORA+ 是 OVD 的 SOTA 3.2 Pseudo-Labeling借用经过预训练的 VLMs 的 image encoder 或 text encoder 来构建 region-word 伪标签,用于模型训练 使用伪标签的方法就是会使用额外的生成标签来参与训练,生成伪标签的方法主要使用预训练的 VLM 来生成,然后使用生成的伪标签来训练检测器 可以分为如下三种: pseudo region-caption pairsregion-word pairspseudo captions1、pseudo region-caption pairs 这类的方法是建立整个 caption 和一个 image region 的伪相关关系 允许一个 region/word 和多个 words/regions 联系起来 2、Pseudo region-word pairs 只允许一个 region/word 和一个 word/region 关联起来 RegionCLIP 使用 CLIP 来生成更细粒度的 pseudo region-word pairs 来预训练 image encoder,但是 CLIP 得分最高的 proposals 可能定位效果很差 VL-PLM 将 CLIP score 和 objectness score 联合起来使用来缓解 RegionCLIP 的问题 GLIP 将目标检测构建成 phrase grounding 任务,并且联合两种数据集来训练模型。使用检测数据训练一个 teacher 模型用于对网络数据生成伪标签,但由于只在检测数据上训练过,所以可能会漏掉一些没见过的新目标 GroundingDINO 将 GLIP 的检测器更新成了最优的 DINO 检测器,提高了检测效果 PromptDet 另辟蹊径,没有生成 pseudo labels,而是迭代的学习 region prompts,并且将 web images 分成了两组,能够主导获得更准确的 pseudo boxes 3、pseudo captions [59] 提出生成另外一种的 pseudo label:使用自然语言来描述目标,而非 bbox。其使用了一个 image caption model 来为每个目标生成描述,然后输入 CLIP 的 text encoder,对周围环境和类别属性做编码。 3.3 Knowledge Distillation-Based将经过预训练的 VLMs 的 image encoder 的知识蒸馏到新的 region encoder 上,新的 region encoder 是要训练的 基于蒸馏的方法就是使用了 teacher-student 的结构,可以分为如下两个大类: 单独蒸馏每个 region联合蒸馏所有 regions1、Distilling Region Embeddings Individually 1.1 Distilling Knowledge into Two-Stage Detectors ViLD 是首个提出使用蒸馏的方法,将 CLIP 的知识蒸馏到 Faster-RCNN 上去的方法,其证明了只使用基础类别训练的 RPN 生成的 region proposal 可以扩展到新类。 ViLD-text:将基础类别的名称进行 prompt 标准化,然后送入 CLIP text encoder,得到每个类别的 text embeddingViLD-image:使用 RPN 网络来进行 proposal 提取,将 proposal 对应的原图区域抠出来送入 CLIP 作为 teacher embedding,来指导 ViLD-image 的学习,在测试的时候是不使用 CLIP image encoder 的1.2 Distilling Knowledge into One-Stage Detectors OV-DETR 是基于 DETR 的开放词汇目标检测器 Prompt-OVD 2、 Distilling Region Embeddings Collectively 预训练的 CLIP image encoder 是在图像级别使用 caption 训练的,所以会隐含目标之间的关系 前面的方法都是对单个 RoI 区域进行整理,没有利用不同目标之间的空间关系 BARON (inspired by MaskCLIP) 对齐 bag-of-regions 的 embedding 来学习从 teacher 得到的知识,对于每个 proposal 都会提取其周围的区域来形成 bag-of-regions 3.4 Transfer Learning-Based将经过预训练的 VLMs 的 image encoder 或 text encoder 的知识迁移需要训练的 encoder 上(迁移就是使用 weight 来初始化),并且端到端重新训练 不同于上面蒸馏的方法使用 VLM 时是直接使用 VLM 的 image encoder 作为图像特征抽取器,不参与训练 OWL-ViT 移除了最后的 token pooling layer,替换成了轻量级的检测头,然后端到端的训练检测数据 UniDetector 同样会训练整个模型,使用 RegionCLIP 的 image backbone 来初始化自己的 image backbone,UniDetector 使用了很多不同源和不同标注空间的数据 F-VLM 没有训练整个模型,而是冻结了 CLIP image encoder 来作为 image backbone 来提取图像特征,只训练了检测头 还有一些方法只使用 CLIP 的 text encoder,没有使用其 image encoder OpenSeeD 统一了开放词汇检测、语义分割、实例分割、全景分割到一个网络结构中,提出将前景、背景的解码进行解耦 3.5 总结region-aware 和 pseudo-labeling 的方法大都使用冗余且带噪声的 image-text pairs,这不可避免的会带来负面效果,至今还无法很好的解决 distillation-based 和 transfer-learning based 方法,没有完全释放 VLM 的隐藏信息,预训练时一般使用 224x224 大小分辨率,但 proposal 包含的空间信息有限,且一般也不是正方形的,CLIP 的预处理(短边 224,center crop)会带来外观扭曲且加重 gap 此外,对 CLIP 的 fine-tuning 会导致对新类别性能的下降,并且在推理的时候边端使用 CLIP 也不太现实 3.6 效果
|
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |