【机器学习】机器学习之多元线性回归 |
您所在的位置:网站首页 › 建立二元线性回归模型的步骤包括 › 【机器学习】机器学习之多元线性回归 |
【机器学习】机器学习之多元线性回归
|
目录
一、多元线性回归基础理论二、案例分析三、数据预处理1.错误数据清洗2.非数值型数据转换
四、使用Excel实现回归1.回归实现2.回归分析
五、使用代码实现回归1. 数据预处理2. 使用Statsmodels建立多元线性回归模型3. 使用Sklearn库建立多元线性回归模型4. 模型优化
六、总结七、参考
一、多元线性回归基础理论
在研究现实问题时,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释因变量的变化,这就是多元回归。当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元性回归。线性回归的数学模型为: f ( x i ) = ω T x i + b f(\pmb x_i)=\pmb \omega^T \pmb x_i + b f(xxxi)=ωωωTxxxi+b 当数据集D中的样本 x i \pmb x_i xxxi 由多个属性进行描述,此时称为“多元线性回归” 二、案例分析 市场房价的走向受到多种因素的影响,通过对影响市场房价的多种因素进行分析,有助于对未来房价的走势进行较为准确的评估。 通过对某段时间某地区的已售房价数据进行线性回归分析,探索影响房价高低的主要因素,并对这些影响因素的影响程度进行分析,利用分析得到的数据,对未来房价的趋势和走向进行预测。 本文探究街区(neighborhood),房屋面积(area),卧室数bedrooms,浴室数bathrooms,房屋风格(style)与 房价(price)的关系已经影响大小。 在原始数据中,发现有房屋数据存在 没有卧室,没有浴室或房屋面积不合理等疑似错误数据,因此,首先将对数据进行适当的清洗。 1.选择表头,并启用筛选 在原始数据中,neighborhood和style为非数值型数据。需要转换成数值型数据才能够进行回归分析。 对于neighborhood,将原数据的A、B、C替换为1、2、3。 对于style,将原数据的ranch、victorian、lodge替换为100、200、300。 将房价(price)作为因变量,表格中的其他变量作为自变量,使用Excel对表中的数据进行回归分析。 回归统计子表分析 Multiple R:相关系数R,用来衡量自变量x与y之间的相关程度的大小。本次数据集回归分析得到的 R R R =0.788,表明x和y之间的关系为高度相关。 R Square:决定系数 R 2 R^2 R2 R 2 = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 R^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2} R2=1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2 反映因变量的全部变异能通过回归关系被自变量解释的比例。可以通俗地理解为使用均值作为误差基准,看预测误差是否大于或者小于均值基准误差。本次数据集回归分析得到的 R 2 R^2 R2 = 0.622,说明自变量能解释因变量的62.2% 子表三分析 自变量含义Coefficients(系数)X Variable 1街区(neighborhood)9109.90116615722X Variable 2房屋面积(area)345.419642269034X Variable 3卧室数bedrooms-1645.8747033071X Variable 4浴室数bathrooms7907.17380048446X Variable 5房屋风格(style)-45.2479173151558根据表三中的Coefficients值,据此便可以估算得出回归方程为: y = 9109.9 x 1 + 345.41 x 2 − 1645.87 x 3 + 7907.17 x 4 − 45.24 x 5 − 5926.57 y = 9109.9x_1 + 345.41x_2 - 1645.87x_3 + 7907.17x_4 - 45.24x_5 - 5926.57 y=9109.9x1+345.41x2−1645.87x3+7907.17x4−45.24x5−5926.57 但根据Coefficients估算出的回归方程可能存在较大的误差。更为重要的是P-value值,由表中P-value的值可以发现,自变量房屋面积 x 2 x_2 x2的P值远小于显著性水平0.05,因此房屋面积(area)与房价(price)相关。卧室数(bedrooms)和浴室数(bathrooms)的P值远大于显著性水平0.05,说明这卧室数(bedrooms)和浴室数(bathrooms)与房价(price)相关性较弱,甚至不存在线性相关关系。 五、使用代码实现回归 1. 数据预处理 首先查看数据的基础信息 import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt#导入数据 df = pd.read_csv("house_prices.csv") #读取数据的基础信息 df.info()
如果数据行没有重复,则对应False,否则对应True。 此处返回False,说明数据中不存在重复数据。 如果有重复数据,则使用drop_duplicates()函数删除重复数据 缺失值识别与处理 # 判断各变量中是否存在缺失值 df.isnull().any(axis = 0) # 各变量中缺失值的数量 df.isnull().sum(axis = 0) # 各变量中缺失值的比例 df.isnull().sum(axis = 0)/df.shape[0]
进行异常检测‘ #对数据进行异常值检测 outlier, upper, lower = outlier_test(data=df, column='price', method='z') outlier.info(); outlier.sample(5)
刚才的探索我们发现,style 与 neighborhood 的类别都是三类,如果只是两类的话我们可以进行卡方检验,所以这里我们使用方差分析。 ## 利用回归模型中的方差分析 ## 只有 statsmodels 有方差分析库 ## 从线性回归结果中提取方差分析结果 import statsmodels.api as sm from statsmodels.formula.api import ols # ols 为建立线性回归模型的统计学库 from statsmodels.stats.anova import anova_lm样本量和置信水平 α_level 的注意点(置信水平 α 的选择经验) 样本量 α-level ≤ 100 10% 100 < n ≤ 500 5% 500 < n ≤ 1000 1% n > 2000 千分之一 样本量过大,α-level 就没什么意义了。 数据量很大时,p 值就没用了,样本量通常不超过 5000, 为了证明两变量间的关系是稳定的,样本量要控制好。 # 从数据集样本中随机选择 600 条,如果希望分层抽样,可参考文章: df = df.copy().sample(600) # C 表示告诉 Python 这是分类变量,否则 Python 会当成连续变量使用 ## 这里直接使用方差分析对所有分类变量进行检验 ## 下面几行代码便是使用统计学库进行方差分析的标准姿势 lm = ols('price ~ C(neighborhood) + C(style)', data=df).fit() anova_lm(lm) # Residual 行表示模型不能解释的组内的,其他的是能解释的组间的 # df: 自由度(n-1)- 分类变量中的类别个数减1 # sum_sq: 总平方和(SSM),residual行的 sum_eq: SSE # mean_sq: msm, residual行的 mean_sq: mse # F:F 统计量,查看卡方分布表即可 # PR(>F): P 值
反复刷新几次,发现都很显著,所以这两个变量也挺值得放入模型中 2. 使用Statsmodels建立多元线性回归模型此处直接使用最小二乘法建立线性回归模型 from statsmodels.formula.api import ols #最小二乘法建立线性回归模型 lm = ols('price ~ area + bedrooms + bathrooms', data=df).fit() lm.summary()
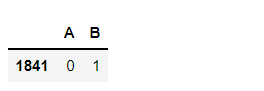
基于Sklearn的线性回归模型的精准度高于基于Statsmodels的线性回归模型。 4. 模型优化由于模型精度较低,这里通过添加虚拟变量与使用方差膨胀因子检测多元共线性的方式来提升模型精度。 # 设置虚拟变量 # 以名义变量 neighborhood 街区为例 nominal_data = df['neighborhood'] # 设置虚拟变量 dummies = pd.get_dummies(nominal_data) dummies.sample() # pandas 会自动帮你命名 # 每个名义变量生成的虚拟变量中,需要各丢弃一个,这里以丢弃C为例 dummies.drop(columns=['C'], inplace=True) dummies.sample()
多元线性回归其实就是把简单线性回归进行多元的推广,其中的输入 x x x由单一特征变为含有n个特征的向量。在多元线性回归中,仅仅认为各个特征和预测值之间是简单的加权求和关系。这个假设在很多时候很牵强,导致精确度往往不尽人意,但确实也在一些应用中性能不错。 相较于Excel进行数据清洗与处理,Pandas库提供的数据清洗处理的能力更为出色,同时Python能够更灵活的对模型进行优化,提升精度。 通过使用统计分析Statsmodels库与Sklearn中线性回归linear_model库对同样的问题进行回归分析,两种方法各有优劣,使用统计分析Statsmodels库时,可以发现并没有将非数值型的数据进行转换就可以直接进行回归分析,但同时模型的精度也大打折扣。而在使用Excel和linear_model进行回归时,必须将非数值型数据转换为数值型数据。 七、参考基于多元线性回归的房价预测 机器学习算法(8)之多元线性回归分析理论详解 机器学习理论(三)多元线性回归 |


 2.选择筛选条件,点击确定(此处选择bedrooms大于0的数据)
2.选择筛选条件,点击确定(此处选择bedrooms大于0的数据)  此时可以看到已经将bedrooms 等于0的数据清洗掉。
此时可以看到已经将bedrooms 等于0的数据清洗掉。  同理,将bathrooms 等于0的数据清洗掉。
同理,将bathrooms 等于0的数据清洗掉。  再将area小于200的数据清洗掉。
再将area小于200的数据清洗掉。  清洗完成。
清洗完成。 替换成功,现在可以进行回归分析了。
替换成功,现在可以进行回归分析了。
 df.info():返回表格的一些基本信息,主要介绍数据集各列的数据类型,是否为空值,内存占用情况 RangeIndex: # 行数,5414行 Data columns (total 7 columns): #列数,7列 non-null: 意思为非空的数据 dtypes: int64(5), object(2) :数据类型
df.info():返回表格的一些基本信息,主要介绍数据集各列的数据类型,是否为空值,内存占用情况 RangeIndex: # 行数,5414行 Data columns (total 7 columns): #列数,7列 non-null: 意思为非空的数据 dtypes: int64(5), object(2) :数据类型 发现数据中不存在缺失值
发现数据中不存在缺失值 丢弃异常值
丢弃异常值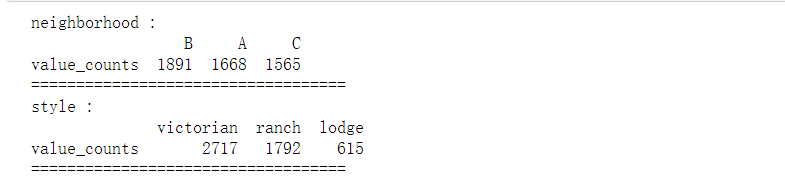 绘出热力图
绘出热力图 通过热力图可以看出 area,bedrooms,bathrooms等变量与房屋价格 price 的关系都还比较强,所以值得放入模型,但分类变量 style与 neighborhood 两者与 price 的关系未知。
通过热力图可以看出 area,bedrooms,bathrooms等变量与房屋价格 price 的关系都还比较强,所以值得放入模型,但分类变量 style与 neighborhood 两者与 price 的关系未知。
 模型拟合效果不理想,
R
2
=
0.54
R^2 =0.54
R2=0.54,模型需要进一步优化。
模型拟合效果不理想,
R
2
=
0.54
R^2 =0.54
R2=0.54,模型需要进一步优化。

 将结果与原数据集进行拼接
将结果与原数据集进行拼接 再次建模
再次建模 此时,
R
2
=
0.92
R^2 =0.92
R2=0.92,由于模型精度较为理想。
此时,
R
2
=
0.92
R^2 =0.92
R2=0.92,由于模型精度较为理想。【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |