如何用二分类学习器解决多分类问题 |
您所在的位置:网站首页 › 常用解决问题的策略 › 如何用二分类学习器解决多分类问题 |
如何用二分类学习器解决多分类问题
|
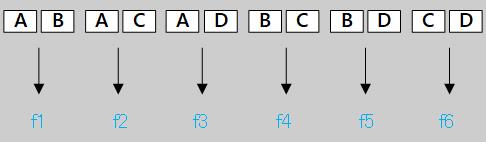
使用二分类学习器解决多分类问题的基本思路是“拆解法”,也就是将多分类任务拆分成多个二分类任务求解。这里主要介绍如何对多分类任务进行拆分,以及对拆分的多个分类器进行集成。 主要有三种拆分策略:“一对一”(One vs One,简称OvO)、“一对其余”(One vs Rest,简称OvR)和“多对多”(Many vs Many,简称MvM). 一、“一对一”(OvO)假设要对N个类别进行分类。OvO将这N个类别两两配对,所以一共产生 例:对四个类别进行分类,A、B、C、D。 训练阶段产生6个分类器:
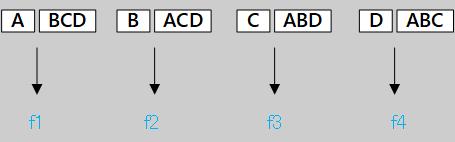
测试阶段,若测试的结果为: f1(x) = A、f2(x) = C、f3(x) = A、f4(x) = C、f5(x) = D、f6(x) = C 有3个分类器的结果都为C,所以就把C作为最终的结果。可以看出一对一训练的分类器多,所以训练的速度会比较慢。 二、“一对其余”(OvR)OvR是每次将一个类的样例作为正例、所有其他类的样例作为反例来训练N个分类器。在测试时: 若仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果;若有多个分类器预测为正类,则通常考虑各个分类器的预测置信度,选择置信度最大的类别标记作为最终结果。同样还是以上面的问题为例,产生4个分类器:
测试阶段: f1(x) = -1、f2(x) = -1、f3(x) = +1、f4(x) = -1 所以x属于C类。 比较OvR和OvO: 可以发现,OvR训练的是N个分类器,而OvO训练的是 对于预测性能取决于数据的分布,在多数情形下差别不大. 三、“多对多”(MvM)MvM是每次将若干个类作为正类,若干个其他类作为反类。可以看出MvM是OvR和OvO更一般的形式。 对于MvM正、反类的构造一种常用的技术是“纠错输出码”(Error Correcting Output Codes,简称ECOC).主要分为两步: 编码:对N个类别做M次划分,每次划分将一部分类别划分为正类,一部分类别划分为反类,从而形成一个二分类训练集;这样一共产生M个训练集,可训练出M个分类器。解码:测试时,M个分类器分别对测试样本x进行预测,这样预测的结果就形成了一个编码。将这个编码与每个类别各自的编码进行比较,找到距离最短的类别作为最终分类的结果。还是以上面问题为例,假定M=5。训练结果如下:
测试阶段: f1(x) = -1、f2(x) = -1、f3(x) = +1、f4(x) = -1、f5(x) = +1 所以测试样本的编码为(-1,-1,+1,-1,+1),到A、B、C、D对应编码的欧式距离为 之所以称为纠错输出码,是因为在测试阶段,即使某个分类器预测错了,但是距离可能还是最小的。例如上面的测试样本正确的编码为(-1,+1,+1,-1,+1)也就是f2出错,但是还是能产生正确的分类C。 一般来说,对于同一个学习任务,ECOC编码越长,纠错能力越强。但是,这意味着所需要的分类器就越多,开销就越大;另一方面,对有限类别数,可能的组合数目是有限的,码长超过一定的范围后就失去了意义。 参考资料:周志华老师《机器学习》 |

【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |