AHP(层次分析法)的全面讲解及python实现 |
您所在的位置:网站首页 › 层次分析法的三个层次 › AHP(层次分析法)的全面讲解及python实现 |
AHP(层次分析法)的全面讲解及python实现
|
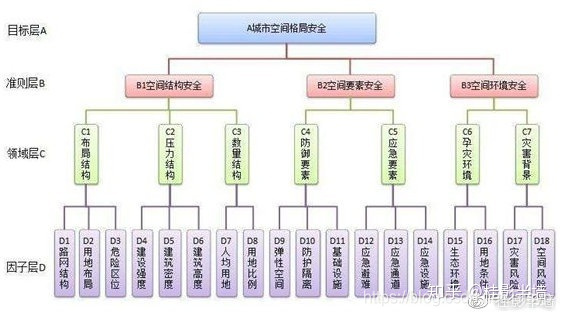
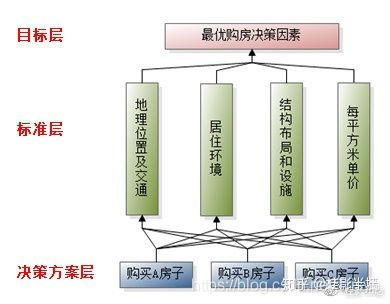
一、层次分析法的使用流程: 1. 建立层次结构模型 首先绘出层次结构图,正常三层是比较常见的:决策的目标、考虑的决策准则因素和决策对象。按它们之间的相互关系分为最高层、中间层和最低层(如下图是四层结构的)
2. 分层构造判断矩阵。多层次的评价指标体系结构一般比较复杂,各种评价指标的权重难以确定,通过两两比较评价因子的重要性来确定权重要比一次性确定所有因子的权重容易把握。该方法叫一致矩阵法,即:不把所有因素放在一起比较,而是两两相互比较。对比时采用相对尺度,以尽可能减少性质不同因素相互比较的困难,以提高准确度。
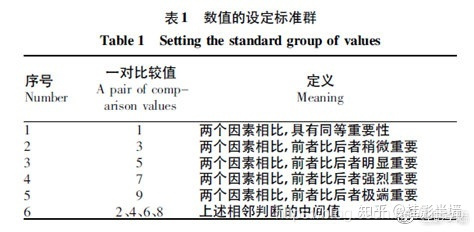
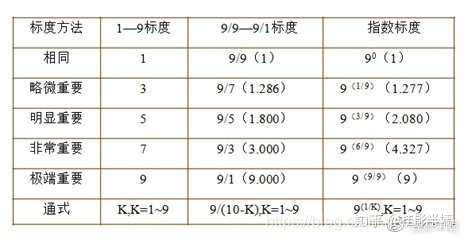
由专家对同一层次内N个指标的相对重要性(两两因素之间)进行打分。相对重要性的比例标度取1-9之间。同时,对各同级指标的重要性评价时,存在三种标度范畴(如下图),根据研究需要自行选择。
对于n个元素而言,可得两两比较判断矩阵A(正交矩阵): 满足: 3. 计算权重。将矩阵A的各行向量进行几何平均(方根法),然后进行归一化,即得到各评价指标权重和特征向量W。即权重向量
4. 一致性检验。若A是一致矩阵,那么A的最大特征值
对判断矩阵,通用的计算权向量方法有和法、根法、特征根法和最小平方法等方法,以和法为例: 1、矩阵按列归一化: 2、正规化后的元素按行相加: 3、将得到的行和向量进行归一化即得权重: 实际应用中,判断矩阵A一般不可能是一致矩阵,因此要进行一致性检验,检查该方法得到的权重向量是否有效。 计算一致性指标CI:
根据n值平均随机一致性指标RI,RI值可查表: n 1 2 3 4 5 6 7 8 9 10 RI 0 0 0.58 0.9 1.12 1.24 1.32 1.41 1.45 1.49 计算一致性比例CR: 当CR小于0.1时,一般认为判断矩阵的一致性是可以接受的。所谓一致性是指判断思维的逻辑一致性。如当甲比丙是强烈重要,而乙比丙是稍微重要时,显然甲一定比乙重要。这就是判断思维的逻辑一致性,否则判断就会有矛盾。 5. 层次排序。可分为层次单排序和层次总排序。所谓层次单排序是指,对于上一层某因素而言,本层次各因素的重要性的排序。层次总排序,确定某层所有因素对于总目标相对重要性的排序权值过程,称为层次总排序。这一过程是从最高层到最底层依次进行的。对于最高层而言,其层次单排序的结果也就是总排序的结果
二、层次分析法实例分析: 1. 建立层次结构模型 假设有m个候选方案,有n个准则。例如一位顾客决定要买一套新住宅,经过初步调查研究确定了三套候选的房子A、B、C,即 将影响购买新房的因素归纳为4个标准: 房子的地理位置及交通; 房子的居住环境; 房子结构、布局与设施; 房子的每平方米建筑面积地单价。 即有m=3个候选方案,n=4个评价指标,分别是地理位置及交通、居住环境、结构布局与设施、每平方米建筑面积地单价) 模型如下:
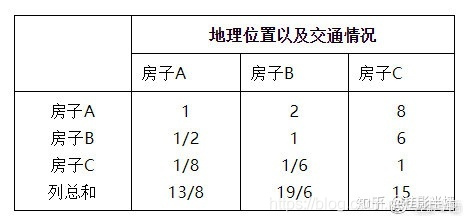
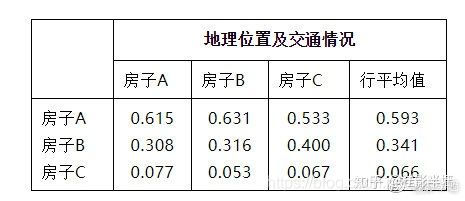
2. 构造判断矩阵 对同一层次内4个指标的相对重要性(两两因素之间)进行打分。经过专家的打分,每个标准的两两比较矩阵可给出,其中以地理位置以及交通情况对应的三个方案的判断矩阵为例,其值如下:
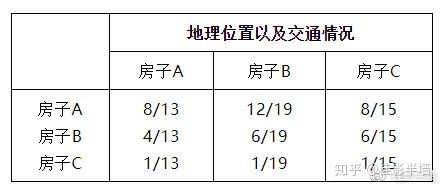
3. 计算权重 我们利用和法来将矩阵按列归一化得到:
再将正规化后的元素按行相加,将得到的行和向量进行归一化即得特征向量:
4. 一致性检验 判断矩阵乘以特征向量得到赋权和向量
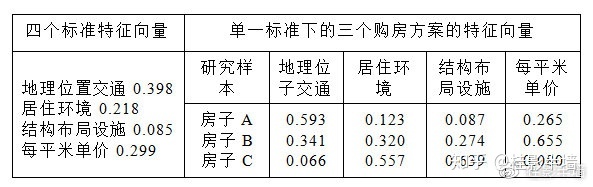
赋权和向量除以对应权重得到: 1.803 / 0.593 =3.040 1.034 / 0.341 =3.032 0.197 / 0.066 =2.985 计算出第二步结果中的平均值,记为 计算一致性指标CI: 计算一致性率CR: 用同样的方法我们可以得到其他三个标准对应三个购房方案的特征向量,以及购房决策四个标准的特征向量,这里就不重复写求解过程,假设最终得到所有特征向量如下:
5. 综合得分 方案 A:0.398*0.593+0.218*0.123+0.085*0.087+0.299*0.265=0.349 方案 B(最优):0.398*0.341+0.218*0.320+0.085*0.274+0.299*0.655=0.425 方案 C:0.398*0.066+0.218*0.557+0.085*0.639+0.299*0.080=0.226
三、python完整代码 注释:本代码数据与上述实例数值不完全匹配,但方法雷同 import numpy as npimport pandas as pdimport warningsclass AHP: def __init__(self, criteria, samples): self.RI = (0, 0, 0.58, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49) self.criteria = criteria self.samples = samples self.num_criteria = criteria.shape[0] self.num_project = samples[0].shape[0] def calculate_weights(self, input_matrix): input_matrix = np.array(input_matrix) n, n1 = input_matrix.shape assert n==n1, "the matrix is not orthogonal" for i in range(n): for j in range(n): if np.abs(input_matrix[i,j]*input_matrix[j,i]-1) > 1e-7: raise ValueError("the matrix is not symmetric") eigen_values, eigen_vectors = np.linalg.eig(input_matrix) max_eigen = np.max(eigen_values) max_index = np.argmax(eigen_values) eigen = eigen_vectors[:, max_index] eigen = eigen/eigen.sum() if n > 9: CR = None warnings.warn("can not judge the uniformity") else: CI = (max_eigen - n)/(n-1) CR = CI / self.RI[n-1] return max_eigen, CR, eigen def calculate_mean_weights(self,input_matrix): input_matrix = np.array(input_matrix) n, n1 = input_matrix.shape assert n == n1, "the matrix is not orthogonal" A_mean = [] for i in range(n): mean_value = input_matrix[:, i]/np.sum(input_matrix[:, i]) A_mean.append(mean_value) eigen = [] A_mean = np.array(A_mean) for i in range(n): eigen.append(np.sum(A_mean[:, i])/n) eigen = np.array(eigen) matrix_sum = np.dot(input_matrix, eigen) max_eigen = np.mean(matrix_sum/eigen) if n > 9: CR = None warnings.warn("can not judge the uniformity") else: CI = (max_eigen - n) / (n - 1) CR = CI / self.RI[n - 1] return max_eigen, CR, eigen def run(self, method="calculate_weights"): weight_func = eval(f"self.{method}") max_eigen, CR, criteria_eigen = weight_func(self.criteria) print('准则层:最大特征值{: |
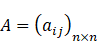
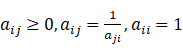
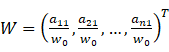 ,其中
,其中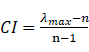 ,n为判断矩阵的阶数
,n为判断矩阵的阶数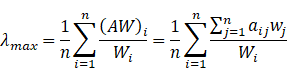
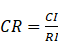 ,
,

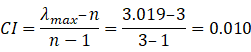
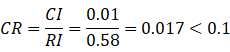
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |