基于freemarker(mht)方式导出带图片的富文本word |
您所在的位置:网站首页 › 富文本转成word中的一部分 › 基于freemarker(mht)方式导出带图片的富文本word |
基于freemarker(mht)方式导出带图片的富文本word
|
需求
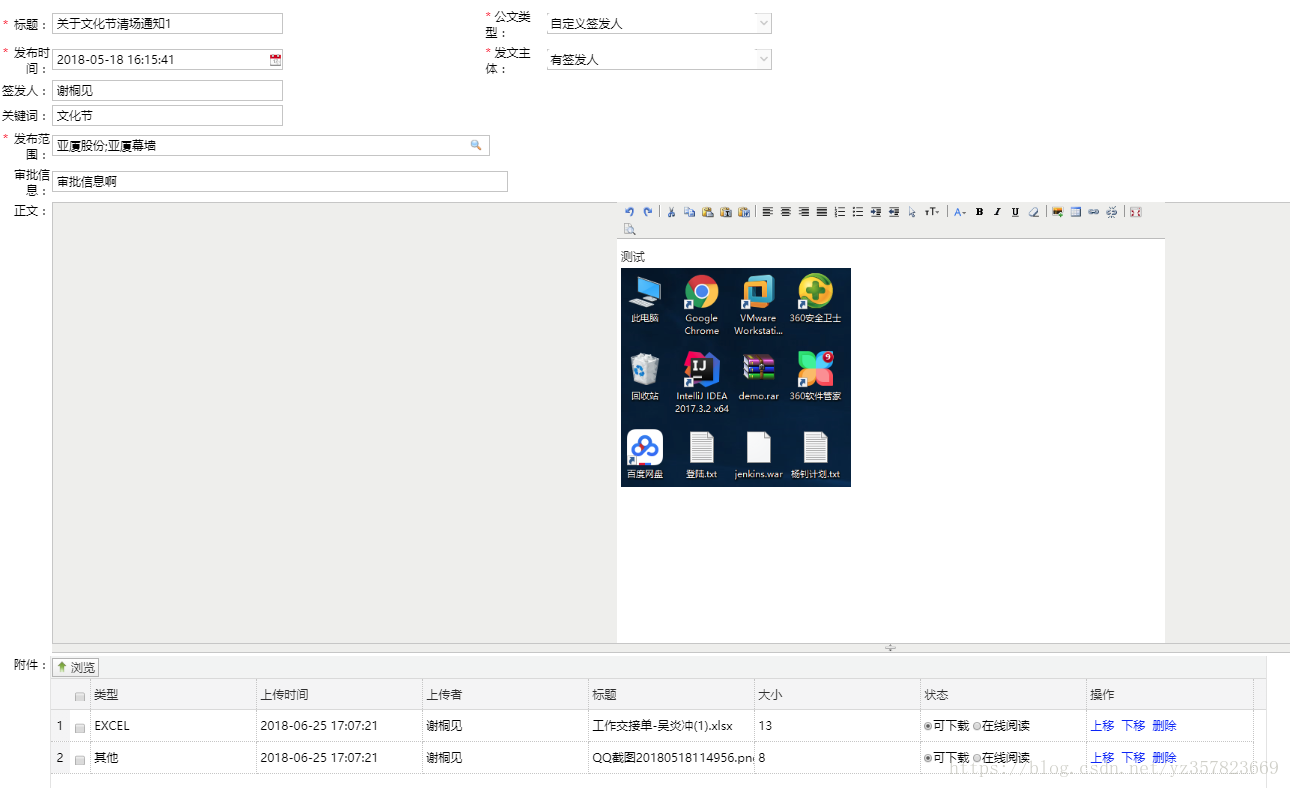
批量将包含富文本的页面(含图片)导出为word的压缩包,并将每个页面的附件一同下载,下载的文件夹路径格式我就不展示了,具体页面如下 本次导出采用基于freemarker的word导出。大体上都是freemarker+xml方式。但是这种方式无法导出富文本,因为富文本字段包含html标签,他无法处理html元素(数据库字段存的值就是包含元素标签的)。导出后样式如下, 经过我两天的琢磨与采坑,终于实现了功能,鉴于网上相关文章比较少并且记录学习的目的,写此博客并感谢恩人 哈哈~~~ (步骤我会写的细点图也会多点,当时看恩人的博客 看的我一愣一愣的) 基于freemarker方式导出包含富文本以及图片的word其实基于freemarker方式的主要思想都是 在word中创建数据填充模板,并转化为另一个中间格式(xml,mht)并重命名为ftl, 所以我们的重点就是制作模板 1.首先第一步创建word文档(不要使用wps)其中content 就是包含富文本的字段名称 接下来我们另存为mht 文件(注意:如果后期的ftl文件有乱码,我们此时要word设置为utf-8编码) 打开我们的mht文件并处理(建议用sublime或者idea): 2.1处理模板字段首先我们在mht文件中找到我们word中的表达式,例如publishTime 并他们修改为${publishTime!""} 因为mht文件有时候会自动换行,会在单词中间加上= 号 或者在{ 等符号与单词之间加上一些mht文件的样式,我们都要删掉 2.2处理富文本图片我们首先找到 ${imagesBase64String!""} ------=_NextPart_01D40A22.6DCACC80 Content-Location: file:///C:/D1745AB2/test2.files/header.htm Content-Transfer-Encoding: quoted-printable Content-Type: text/html; charset="utf-8"在中间加入${imagesBase64String!""} 作为占位符,并记录下file:///C:/D1745AB2/test2.files/header.htm 内容(后续会用到) 接下来找到 ${imagesXmlHrefString!""} ------=_NextPart_01D40A22.6DCACC80--加入${imagesXmlHrefString!""} 并记录下01D40A22.6DCACC80 后面会用到 2.3接下来我们修改编码全文检索gb2312把他改成utf-8,同时需要加上3D前缀,对应着格式来改 一般就这两种: 和Content-Type: text/html; charset=3D"utf-8"然后将后缀名保存为ftl 就可以了 3.使用工具类处理模板 if("content".equals(key)){//处理富文本 RichHtmlHandler handler = new RichHtmlHandler(val.toString()); handler.setDocSrcLocationPrex("file:///C:/D1745AB2");//用到前面mht文件中的值 handler.setDocSrcParent("test2.files");//用到前面mht文件中的值 handler.setNextPartId("01D40A22.6DCACC80");//用到前面mht文件中的值 handler.setShapeidPrex("_x56fe__x7247__x0020"); handler.setSpidPrex("_x0000_i"); handler.setTypeid("#_x0000_t75"); handler.handledHtml(false); String bodyBlock = handler.getHandledDocBodyBlock(); System.out.println("bodyBlock:\n"+bodyBlock); String handledBase64Block = ""; if (handler.getDocBase64BlockResults() != null && handler.getDocBase64BlockResults().size() > 0) { for (String item : handler.getDocBase64BlockResults()) { handledBase64Block += item + "\n"; } } if(StringUtils.isBlank(handledBase64Block)){ handledBase64Block = ""; } res.put("imagesBase64String", handledBase64Block); String xmlimaHref = ""; if (handler.getXmlImgRefs() != null && handler.getXmlImgRefs().size() > 0) { for (String item : handler.getXmlImgRefs()) { xmlimaHref += item + "\n"; } } if(StringUtils.isBlank(xmlimaHref)){ xmlimaHref = ""; } res.put("imagesXmlHrefString", xmlimaHref); res.put("content", bodyBlock); }然后通过提供的三个工具类RichHtmlHandler WordHtmlGeneratorHelper WordImageConvertor 就可以了 包含富文本图片的word导出基本就可以了,接下来是我们批量导出word并带出附件并下载为压缩包功能 我们的大致步骤 遍历数据源,下载导出word到项目的临时文件夹如果有附件则下载附件,并存放相应临时文件夹将整个文件夹压缩下载压缩包并删除临时文件涉及的知识点主要有 freemarker+mht导出含图片富文本word文件遍历压缩导出压缩包,URL下载附件文件名特殊字符处理删除临时文件访问项目Resouce中的文件(模板位置),访问项目所在路径(针对多系统部署临时文件路径问题)下面展示整个流程的导出方法,涉及的具体工具类请看源码 /** * 基于freemarker导出包含富文本的word * @param ids * @param sessionId * @param typeId * @param nameSpace * @param newsNoticeService * @param newsFileService * @param response * @param readProperty * @param basePath * @param newsNoticeProcessService * @param newsPublishRangeService */ public static void ExportNoticeWord(String ids, String sessionId, String typeId, String nameSpace, INewsNoticeService newsNoticeService, INewsFileService newsFileService, HttpServletResponse response, ReadProperty readProperty, String basePath, INewsNoticeProcessService newsNoticeProcessService, INewsPublishRangeService newsPublishRangeService){ try { //basePath = request.getSession().getServletContext().getRealPath("/assets/exportTemp/"); Configuration configuration = new Configuration(); configuration.setDefaultEncoding("UTF-8"); String idArr[] = ids.split(","); String singlrNoticeName = ""; for(int i=0;i |
 关于xml方式的导出以及包含图片的导出网上教程很多,这里我们就不多介绍了 所以xml这种方法不可取,最终在网上找到了这两篇文章恩人1 恩人2
关于xml方式的导出以及包含图片的导出网上教程很多,这里我们就不多介绍了 所以xml这种方法不可取,最终在网上找到了这两篇文章恩人1 恩人2

【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |