|
一、参数估计简介 很多情况下,我们只有有限的样本集,而类条件概率密度函数p(x|ωi)和先验概率P(ωi)是未知的,需要根据已有样本进行参数估计,然后将估计值当作真实值来使用。 由给定样本集求解随机变量的分布密度函数问题是统计机器学习和概率统计学的基本问题之一。解决该问题的方法包括参数估计和非参数估计两大类: 1.参数估计方法 已知概率密度函数的形式而函数的有关参数未知,通过估计参数来估计概率密度函数的方法。有两种主要参数估计法:确定性参数估计方法是把参数看作确定而未知的, 典型方法为最大似然估计。随机参数估计方法是把未知参数当作具有某种分布的随机变量, 典型方法为贝叶斯估计。 2.非参数估计 非参数估计就是在概率密度函数形式未知条件下, 直接利用样本来推断概率密度函数。常见的非参数估计方法有核密度估计(KDE)和kN-近邻估计。和参数估计不同,非参数估计并不加入任何先验知识,而是根据数据本身的特点、性质来拟合样本集的概率分布,这样就能比参数估计方法得出更好的模型。核密度估计(KDE, Kernel Density Estimation)方法又称为Parzen窗估计(Parzen Window Estimation)或Parzen-Rosenblatt窗估计,该方法无需求解概率密度函数的参数,而用一组标准函数的叠加表示概率密度函数。简单来说,核密度估计其实是对直方图的一个自然拓展。 二、核密度估计公式及其计算  下面结合核密度估计公式(2),给出一个简单计算示例以说明核函数的使用,后面将讨论一些典型的核函数。 下面结合核密度估计公式(2),给出一个简单计算示例以说明核函数的使用,后面将讨论一些典型的核函数。  关于核密度估计(Parzen窗估计)方法的更多理论知识可参阅文献[1-3]。 三、核密度估计Python实践 这里使用Anaconda Jupyter Notebook及流行的Sklearn机器学习库实现核密度估计的计算。 1.导入库 在程序中导入库: 关于核密度估计(Parzen窗估计)方法的更多理论知识可参阅文献[1-3]。 三、核密度估计Python实践 这里使用Anaconda Jupyter Notebook及流行的Sklearn机器学习库实现核密度估计的计算。 1.导入库 在程序中导入库:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KernelDensity
from sklearn.model_selection import GridSearchCV
其中GridSearchCV库的作用就是自动调参,只要把参数输进去,它就能够返回最优模型参数的组合。 2.合成数据 为了进行核密度估计,现使用两种不同类型分布产生一个合成数据集:一种是非对称对数正态分布(使用rand.lognormal方法),另一种是高斯分布/或正态分布(使用rand.normal方法)。下面定义名为generate_data的函数,该函数将返回2000个数据点。
def generate_data(seed=17):
# Fix the seed to reproduce the results
rand = np.random.RandomState(seed)
x = []
dat = rand.lognormal(0, 0.3, 1000)
x = np.concatenate((x, dat))
dat = rand.normal(3, 1, 1000)
x = np.concatenate((x, dat))
return x
以下程序段将样本点存储在训练集x_train张量中,我们可以画出这些点的散点图或者画出这些点的直方图(见图1)。
x_train = generate_data()[:, np.newaxis]
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 5))
plt.subplot(121)
plt.scatter(np.arange(len(x_train)), x_train, c='green')
plt.xlabel('Sample no.')
plt.ylabel('Value')
plt.title('Scatter plot')
plt.subplot(122)
plt.hist(x_train, bins=50)
plt.title('Histogram')
fig.subplots_adjust(wspace=.3)
plt.show()
 图1 3.使用Sklearn进行核密度估计 为了找到被估计密度函数的形状,我们可以生成一组彼此等距的点并估计各点的核密度。生成测试点的语句如下: 图1 3.使用Sklearn进行核密度估计 为了找到被估计密度函数的形状,我们可以生成一组彼此等距的点并估计各点的核密度。生成测试点的语句如下:
x_test = np.linspace(-1, 7, 2000)[:, np.newaxis]
现创建一个KernelDensity对象model,并使用fit()方法判定各样本得分的程序段如下:
model = KernelDensity()
model.fit(x_train)
log_dens = model.score_samples(x_test)
在Python中,使用Sklearn进行核密度估计其实十分简单,直接调用KernelDensity()方法就可以了。KernelDensity()方法的主要参数有三个:bandwidth是带宽,即核密度估计公式中的h;algorithm是加速邻近点的搜索算法如KD-Tree算法等;kernel是要选择的核函数(见下表)。 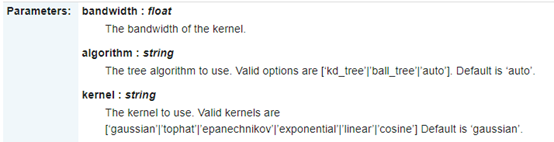 这里的KernelDensity()方法使用了默认参数,即kernel=gaussian、bandwidth=1、Ball_Tree。 下面两条语句绘制各样本点的密度分值,概率密度分布形状见图2所示。 这里的KernelDensity()方法使用了默认参数,即kernel=gaussian、bandwidth=1、Ball_Tree。 下面两条语句绘制各样本点的密度分值,概率密度分布形状见图2所示。  图2 4. 理解带宽参数 前面的核密度函数估计程序段输出结果不是十分理想,主要原因是采用了(bandwidth=1)默认参数。下面程序段使用了不同带宽进行实验,以便观察带宽对密度估计的影响(见图3)。 图2 4. 理解带宽参数 前面的核密度函数估计程序段输出结果不是十分理想,主要原因是采用了(bandwidth=1)默认参数。下面程序段使用了不同带宽进行实验,以便观察带宽对密度估计的影响(见图3)。
bandwidths = [0.01, 0.05, 0.1, 0.5, 1, 4]
fig, ax = plt.subplots(nrows=2, ncols=3, figsize=(10, 7))
plt_ind = np.arange(6) + 231
for b, ind in zip(bandwidths, plt_ind):
kde_model = KernelDensity(kernel='gaussian', bandwidth=b)
kde_model.fit(x_train)
score = kde_model.score_samples(x_test)
plt.subplot(ind)
plt.fill(x_test, np.exp(score), c='cyan')
plt.title("h="+str(b))
fig.subplots_adjust(hspace=0.5, wspace=.3)
plt.show()
 图3 从图3可以清晰地看到,增加带宽能得到更加平滑的估计。极小带宽值会产生尖峰和抖动的曲线,而极高带宽会产生忽略重要细节的光滑曲线。因此,为带宽参数选择适当的数值尤为重要。 5. 调整带宽参数 GridSearchCV(Cross-Validated Grid-Search,交叉验证网格搜索)允许通过多折交叉验证对带宽参数进行调优并返回参数值,其默认的交叉验证参数是三折交叉验证。该方法格式及常用参数说明如下: class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’) ●estimator:选择使用的分类器,并且传入除需要确定最佳的参数之外的其他参数。 ●param_grid:需要最优化的参数的取值,值为字典或者列表,键命名必须为模型本身的参数名称。 ●scoring:模型评价标准,默认None;或者如scoring=‘roc_auc’,根据所选模型不同,评价准则不同,其他常见的还有’f1’,‘accuracy’,‘recall’, , ‘average_precision’;这里的字符串(函数名)或是可调用对象需要其函数签名形如scorer(estimator, X, y),如果是默认None,则使用estimator的误差估计函数。 ●cv=None,交叉验证参数,指定fold数量,默认None,使用三折交叉验证;也可以是yield训练/测试数据的生成器。 我们还可以给GridSearchCV()方法设置不同的带宽参数值。 图3 从图3可以清晰地看到,增加带宽能得到更加平滑的估计。极小带宽值会产生尖峰和抖动的曲线,而极高带宽会产生忽略重要细节的光滑曲线。因此,为带宽参数选择适当的数值尤为重要。 5. 调整带宽参数 GridSearchCV(Cross-Validated Grid-Search,交叉验证网格搜索)允许通过多折交叉验证对带宽参数进行调优并返回参数值,其默认的交叉验证参数是三折交叉验证。该方法格式及常用参数说明如下: class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’) ●estimator:选择使用的分类器,并且传入除需要确定最佳的参数之外的其他参数。 ●param_grid:需要最优化的参数的取值,值为字典或者列表,键命名必须为模型本身的参数名称。 ●scoring:模型评价标准,默认None;或者如scoring=‘roc_auc’,根据所选模型不同,评价准则不同,其他常见的还有’f1’,‘accuracy’,‘recall’, , ‘average_precision’;这里的字符串(函数名)或是可调用对象需要其函数签名形如scorer(estimator, X, y),如果是默认None,则使用estimator的误差估计函数。 ●cv=None,交叉验证参数,指定fold数量,默认None,使用三折交叉验证;也可以是yield训练/测试数据的生成器。 我们还可以给GridSearchCV()方法设置不同的带宽参数值。
bandwidth = np.arange(0.05, 2, .05)
kde = KernelDensity(kernel='gaussian')
grid = GridSearchCV(kde, {'bandwidth': bandwidth})
grid.fit(x_train)
最佳模型可通过GridSearchCV类对象的best_estimator_字段进行搜索。以下程序段是采用Gauss核的最佳核密度估计并显示出最佳带宽值(见图4)。
kde = grid.best_estimator_
log_dens = kde.score_samples(x_test)
plt.fill(x_test, np.exp(log_dens), c='cyan')
plt.title('Optimal estimate with Gaussian kernel')
plt.show()
print("optimal bandwidth: " + "{:.2f}".format(kde.bandwidth))
 图4 从图4可以看出,带宽值=0.15时的核密度估计似乎能更好地拟合样本数据,图4的左半部符合对数正态分布,图4的右半部很好地拟合了正态分布。 6. Sklearn机器学习库提供的典型密度估计核函数 Skitlearn机器学习库提供的密度估计核函数如下: 图4 从图4可以看出,带宽值=0.15时的核密度估计似乎能更好地拟合样本数据,图4的左半部符合对数正态分布,图4的右半部很好地拟合了正态分布。 6. Sklearn机器学习库提供的典型密度估计核函数 Skitlearn机器学习库提供的密度估计核函数如下:  了解核函数的最直接方式是为其画像(绘制图形)。首先,我们可用一个样本点来构建模型;接着,估计该样本点附近所有点的密度,并沿y轴绘制密度。以下程序段用来绘制6个典型核函数的图形(见图5)。 了解核函数的最直接方式是为其画像(绘制图形)。首先,我们可用一个样本点来构建模型;接着,估计该样本点附近所有点的密度,并沿y轴绘制密度。以下程序段用来绘制6个典型核函数的图形(见图5)。
kernels = ['cosine', 'epanechnikov', 'exponential', 'gaussian', 'linear', 'tophat']
fig, ax = plt.subplots(nrows=2, ncols=3, figsize=(10, 7))
plt_ind = np.arange(6) + 231
for k, ind in zip(kernels, plt_ind):
kde_model = KernelDensity(kernel=k)
kde_model.fit([[0]])
score = kde_model.score_samples(np.arange(-2, 2, 0.1)[:, None])
plt.subplot(ind)
plt.fill(np.arange(-2, 2, 0.1)[:, None], np.exp(score), c='blue')
plt.title(k)
fig.subplots_adjust(hspace=0.5, wspace=.3)
plt.show()
 7. 实验不同的核函数 下面程序段采用了不同的核函数进行实验,以观察使用不同核函数和合成数据来估计概率密度函数。可以与前面一样使用GridSearchCV()来寻找最佳带宽值。但是,对于余弦、线性和Tophat核函数会因一些-inf评分,可能导致GridSearchCV()函数执行时发出运行时警告,一种解决方案是为GridSearchCV()编写自定义评分函数。在下面程序段中,自定义评分函数my_scores()中忽略了测试点-inf评分而返回平均值。当然,采用该方案并非是处理-inf评分的最佳策略,我们也可根据已有样本数据采取其他的策略。 7. 实验不同的核函数 下面程序段采用了不同的核函数进行实验,以观察使用不同核函数和合成数据来估计概率密度函数。可以与前面一样使用GridSearchCV()来寻找最佳带宽值。但是,对于余弦、线性和Tophat核函数会因一些-inf评分,可能导致GridSearchCV()函数执行时发出运行时警告,一种解决方案是为GridSearchCV()编写自定义评分函数。在下面程序段中,自定义评分函数my_scores()中忽略了测试点-inf评分而返回平均值。当然,采用该方案并非是处理-inf评分的最佳策略,我们也可根据已有样本数据采取其他的策略。
def my_scores(estimator, X):
scores = estimator.score_samples(X)
# Remove -inf
scores = scores[scores != float('-inf')]
# Return the mean values
return np.mean(scores)
kernels = ['cosine', 'epanechnikov', 'exponential', 'gaussian', 'linear', 'tophat']
fig, ax = plt.subplots(nrows=2, ncols=3, figsize=(10, 7))
plt_ind = np.arange(6) + 231
h_vals = np.arange(0.05, 1, .1)
for k, ind in zip(kernels, plt_ind):
grid = GridSearchCV(KernelDensity(kernel=k),
{'bandwidth': h_vals},
scoring=my_scores)
grid.fit(x_train)
kde = grid.best_estimator_
log_dens = kde.score_samples(x_test)
plt.subplot(ind)
plt.fill(x_test, np.exp(log_dens), c='cyan')
plt.title(k + " h=" + "{:.2f}".format(kde.bandwidth))
fig.subplots_adjust(hspace=.5, wspace=.3)
plt.show()
 图6 采用不同核函数进行密度估计的实验结果见图6所示。 8. 最终的优化模型 前面介绍了采用不同核函数进行密度估计。下面程序段再对GridSearchCV()函数进行一些设置,这样不仅能发现最佳带宽,还能寻找到所使用样本数据的最佳核函数。 图6 采用不同核函数进行密度估计的实验结果见图6所示。 8. 最终的优化模型 前面介绍了采用不同核函数进行密度估计。下面程序段再对GridSearchCV()函数进行一些设置,这样不仅能发现最佳带宽,还能寻找到所使用样本数据的最佳核函数。
grid = GridSearchCV(KernelDensity(),
{'bandwidth': h_vals, 'kernel': kernels},
scoring=my_scores)
grid.fit(x_train)
best_kde = grid.best_estimator_
log_dens = best_kde.score_samples(x_test)
plt.fill(x_test, np.exp(log_dens), c='cyan')
plt.title("Best Kernel: " + best_kde.kernel+" h="+"{:.2f}".format(best_kde.bandwidth))
plt.show()
 图7 以上程序段绘制了最终的核密度估计图,以及相应的最佳带宽及核函数参数,见图7所示。 本文介绍了采用Sklearn库对一维合成数据进行核密度估计的方法并给出了Python程序实现示例,这些示例也可推广到未知分布来源的多维数据核密度估计应用实践中。 图7 以上程序段绘制了最终的核密度估计图,以及相应的最佳带宽及核函数参数,见图7所示。 本文介绍了采用Sklearn库对一维合成数据进行核密度估计的方法并给出了Python程序实现示例,这些示例也可推广到未知分布来源的多维数据核密度估计应用实践中。
参考文献: 1.Trevor Hastie et al. The Elements of Statistical Learning (2nd Edition), Springer. 2.李弼程等. 模式识别原理与应用, 西电版. 3.齐敏等. 模式识别导论, 清华版. 4.https://stackabuse.com 5.https://www.zhihu.com/question/27301358 6.https://en.wikipedia.org/wiki/Kernel_density_estimation
发布日期:2021年03月24日
|