【精选】MongoDB常用命令大全 |
您所在的位置:网站首页 › 宠物狗的衣服怎么做简单做法视频 › 【精选】MongoDB常用命令大全 |
【精选】MongoDB常用命令大全
|
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下,添加更多的节点,可以保证服务器性能。MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。 一、数据库相关1.连接 (1)完整 mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]](2)使用默认端口 mongodb://localhost(3)使用shell mongo
2.查询数据库 (1)查询所有数据库 show dbs
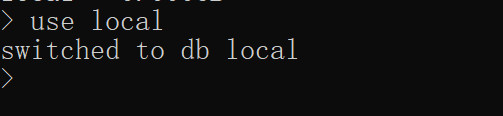
3.创建数据库 use database_name如果数据库不存在,则创建并切换到该数据库,存在则切换到该数据库 (1)已存在
(2)不存在
可以看到,创建的 test数据库并没有显示,需要插入数据才能显示
4.删除数据库 先切换到指定数据库,然后执行以下命令 db.dropDatabase()
1.创建集合 切换到指定数据库,然后执行如下命令 db.createCollection(name, options)说明: name 要创建的集合名称,可选参数,指定有关内存大小及索引的选项 options参数:capped如果为true则创建固定集合(有着固定大小的集合);size为固定集合指定一个最大值,如果capped为true需要指定该字段;max 指定固定集合中包含文档的最大数量
带参数的集合
插入文档会自动创建集合
2.查看所有集合 先切换到指定数据库,然后执行如下命令 show collections
3.删除集合 db.COLLECTION_NAME.drop()成功删除则返回true,否则返回false
1. 插入文档 使用insert()或insertOne()或insertMany()方法插入文档 db.COLLECTION_NAME.insert(document)
插入单条数据 db.collection.insertOne( , { writeConcern: } )
插入多条数据 db.collection.insertMany( [ , , ... ], { writeConcern: , ordered: } )document: 要写入的文档 writeConcern:写入策略,默认为1,即要求默认写操作,0是不要求 ordered:是否按照顺序写入,默认为true,按照顺序写入
2.查询文档 db.COLLECTION_NAME.find(query, projection) query :可选,使用查询操作符指定查询条件projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。pretty()以格式化方法显示文档
3.更新文档 使用update()和save()方法来更新集合中的文档 (1)update()方法 db.collection.update( , , { upsert: , multi: , writeConcern: } )参数说明: query : update的查询条件,类似sql update查询内where后面的。update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。writeConcern :可选,抛出异常的级别。
(2)save()方法 save() 方法通过传入的文档来替换已有文档,_id 主键存在就更新,不存在就插入。 db.collection.save( , { writeConcern: } )参数说明: document : 文档数据。writeConcern :可选,抛出异常的级别。
4.删除文档 db.collection.remove( , )参数说明: query :(可选)删除的文档的条件。justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
1.大于(>): $gt db.collection2.find({age : {$gt : 30}})
2.大于等于(>=): $gte db.collection2.find({age : {$gte : 30}})
3.小于(mongostat 2.mongotop 命令 mongotop也是mongodb下的一个内置工具,mongotop提供了一个方法,用来跟踪一个MongoDB的实例,查看哪些大量的时间花费在读取和写入数据。 mongotop提供每个集合的水平的统计数据。默认情况下,mongotop返回值的每一秒。 启动你的Mongod服务,进入到你安装的MongoDB目录下的bin目录, 然后输入mongotop命令,如下所示: D:\set up\mongodb\bin>mongotop 十四、MongoDB高级1.关系 MongoDB 中的关系可以是: 1:1 (1对1)1: N (1对多)N: 1 (多对1)N: N (多对多)下面以用户的地址为例 (1)嵌入式关系 缺点:如果用户和用户地址在不断增加,数据量不断变大,会影响读写性能 { "_id":ObjectId("52ffc33cd85242f436000001"), "contact": "987654321", "dob": "01-01-1991", "name": "Tom Benzamin", "address": [ { "building": "22 A, Indiana Apt", "pincode": 123456, "city": "Los Angeles", "state": "California" }, { "building": "170 A, Acropolis Apt", "pincode": 456789, "city": "Chicago", "state": "Illinois" }] }查询 db.users.findOne({"name":"Tom Benzamin"},{"address":1})(2)引用关系 { "_id":ObjectId("52ffc33cd85242f436000001"), "contact": "987654321", "dob": "01-01-1991", "name": "Tom Benzamin", "address_ids": [ ObjectId("52ffc4a5d85242602e000000"), ObjectId("52ffc4a5d85242602e000001") ] }这种方法需要两次查询,第一次查询用户地址的对象id(ObjectId),第二次通过查询的id获取用户的详细地址信息 var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1}) var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})2.查询分析 查询分析常用函数explain()和hint() (1)explain 操作提供了查询信息,使用索引及查询统计等。有利于我们对索引的优化。 创建gender和user_name的索引 db.users.ensureIndex({gender:1,user_name:1})使用explaing db.users.find({gender:"M"},{user_name:1,_id:0}).explain()返回结果如下: { "cursor" : "BtreeCursor gender_1_user_name_1", "isMultiKey" : false, "n" : 1, "nscannedObjects" : 0, "nscanned" : 1, "nscannedObjectsAllPlans" : 0, "nscannedAllPlans" : 1, "scanAndOrder" : false, "indexOnly" : true, "nYields" : 0, "nChunkSkips" : 0, "millis" : 0, "indexBounds" : { "gender" : [ [ "M", "M" ] ], "user_name" : [ [ { "$minElement" : 1 }, { "$maxElement" : 1 } ] ] } } indexOnly: 字段为 true ,表示我们使用了索引。cursor:因为这个查询使用了索引,MongoDB 中索引存储在B树结构中,所以这是也使用了 BtreeCursor 类型的游标。如果没有使用索引,游标的类型是 BasicCursor。这个键还会给出你所使用的索引的名称,你通过这个名称可以查看当前数据库下的system.indexes集合(系统自动创建,由于存储索引信息,这个稍微会提到)来得到索引的详细信息。n:当前查询返回的文档数量。nscanned/nscannedObjects:表明当前这次查询一共扫描了集合中多少个文档,我们的目的是,让这个数值和返回文档的数量越接近越好。millis:当前查询所需时间,毫秒数。indexBounds:当前查询具体使用的索引。(2)使用 hint() 可以使用 hint 来强制 MongoDB 使用一个指定的索引。这种方法某些情形下会提升性能。 一个有索引的 collection 并且执行一个多字段的查询(一些字段已经索引了)。 如下查询实例指定了使用 gender 和 user_name 索引字段来查询: db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1})可以使用 explain() 函数来分析以上查询: db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}).explain()3.原子操作 mongodb不支持事务,但是提供了许多原子操作,比如文档的保存,修改,删除等,都是原子操作。所谓原子操作就是要么这个文档保存到Mongodb,要么没有保存到Mongodb,不会出现查询到的文档没有保存完整的情况。原子操作命令如下: (1)$set 用来指定一个键并更新键值,若键不存在并创建。 { $set : { field : value } }(2)$unset 用来删除一个键。 { $unset : { field : 1} }(3)$inc 可以对文档的某个值为数字型(只能为满足要求的数字)的键进行增减的操作。 { $inc : { field : value } }(4)$push 把value追加到field里面去,field一定要是数组类型才行,如果field不存在,会新增一个数组类型加进去。 { $push : { field : value } }(5)$pushAll 同$push,只是一次可以追加多个值到一个数组字段内。 { $pushAll : { field : value_array } }(6)$pull 从数组field内删除一个等于value值。 { $pull : { field : _value } }(7)$addToSet 增加一个值到数组内,而且只有当这个值不在数组内才增加。 (8)$pop 删除数组的第一个或最后一个元素 { $pop : { field : 1 } }(9)$rename 修改字段名称 { $rename : { old_field_name : new_field_name } }(10)$bit 位操作,integer类型 {$bit : { field : {and : 5}}}4.高级索引 { "address": { "city": "Los Angeles", "state": "California", "pincode": "123" }, "tags": [ "music", "cricket", "blogs" ], "name": "Tom Benzamin" }(1)索引数组 假设我们基于标签来检索用户,为此我们需要对集合中的数组 tags 建立索引。在数组中创建索引,需要对数组中的每个字段依次建立索引。所以在我们为数组 tags 创建索引时,会为 music、cricket、blogs三个值建立单独的索引 创建数组索引 db.users.ensureIndex({"tags":1})检索集合的 tags 字段 db.users.find({tags:"cricket"})(2)索引子文档字段 假设我们需要通过city、state、pincode字段来检索文档,由于这些字段是子文档的字段,所以我们需要对子文档建立索引。 创建索引 db.users.ensureIndex({"address.city":1,"address.state":1,"address.pincode":1})检索数据 db.users.find({"address.city":"Los Angeles","address.state":"California","address.pincode":"123"})(3)索引最大范围 集合中索引不能超过64个索引名的长度不能超过128个字符一个复合索引最多可以有31个字段5.ObjectId ObjectId 是一个12字节 BSON 类型数据,有以下格式: 前4个字节表示时间戳接下来的3个字节是机器标识码紧接的两个字节由进程id组成(PID)最后三个字节是随机数。MongoDB中存储的文档必须有一个"_id"键。这个键的值可以是任何类型的,默认是个ObjectId对象。在一个集合里面,每个文档都有唯一的"_id"值,来确保集合里面每个文档都能被唯一标识。MongoDB采用ObjectId,而不是其他比较常规的做法(比如自动增加的主键)的主要原因,因为在多个 服务器上同步自动增加主键值既费力还费时。 (1)创建新的ObjectId newObjectId = ObjectId()(2)创建文档的时间戳 ObjectId("5349b4ddd2781d08c09890f4").getTimestamp()(3)ObjectId 转换为字符串 new ObjectId().str6.mapReduce Map-Reduce是一种计算模型,简单地说就是将大量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(Reduce)。 基本语法: db.collection.mapReduce( function() {emit(key,value);}, //map 函数 function(key,values) {return reduceFunction}, //reduce 函数 { out: collection, query: document, sort: document, limit: number } )使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value), 遍历 collection 中所有的记录, 将 key 与 value 传递给 Reduce 函数进行处理。 Map 函数必须调用 emit(key, value) 返回键值对。 参数说明: map :映射函数 (生成键值对序列,作为 reduce 函数参数)。reduce 统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。。out 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。query 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)sort 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制limit 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)返回结果参数说明: result:储存结果的collection的名字,这是个临时集合,MapReduce的连接关闭后自动就被删除了。timeMillis:执行花费的时间,毫秒为单位input:满足条件被发送到map函数的文档个数emit:在map函数中emit被调用的次数,也就是所有集合中的数据总量ouput:结果集合中的文档个数(count对调试非常有帮助)ok:是否成功,成功为1err:如果失败,这里可以有失败原因,不过从经验上来看,原因比较模糊,作用不大7.全文索引 全文检索对每一个词建立一个索引,指明该词在文章中出现的位置和次数,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。类似于通过字典中检索字表查字的过程 (1)创建全文索引 db.posts.ensureIndex({post_text:"text"})(2)使用全文索引 db.posts.find({$text:{$search:"mongodb"}})(3)删除索引 db.posts.dropIndex("post_text_text")8.正则表达式 使用 $regex 操作符来设置匹配字符串的正则表达式。 (1)使用正则表达式 db.posts.find({post_text:{$regex:"runoob"}})(2)不区分大小写 如果检索需要不区分大小写,我们可以设置 $options 为 $i。 9.GridFS GridFS 用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等)。 GridFS 也是文件存储的一种方式,但是它是存储在MonoDB的集合中。 GridFS 可以更好的存储大于16M的文件。 GridFS 会将大文件对象分割成多个小的chunk(文件片段),一般为256k/个,每个chunk将作为MongoDB的一个文档(document)被存储在chunks集合中。 GridFS 用两个集合来存储一个文件:fs.files与fs.chunks。 每个文件的实际内容被存在chunks(二进制数据)中,和文件有关的meta数据(filename,content_type,还有用户自定义的属性)将会被存在files集合中。 以下是简单的 fs.files 集合文档: { "filename": "test.txt", "chunkSize": NumberInt(261120), "uploadDate": ISODate("2014-04-13T11:32:33.557Z"), "md5": "7b762939321e146569b07f72c62cca4f", "length": NumberInt(646) }以下是简单的 fs.chunks 集合文档: { "files_id": ObjectId("534a75d19f54bfec8a2fe44b"), "n": NumberInt(0), "data": "Mongo Binary Data" } GridFS 添加文件现在我们使用 GridFS 的 put 命令来存储 mp3 文件。 调用 MongoDB 安装目录下bin的 mongofiles.exe工具。 打开命令提示符,进入到MongoDB的安装目录的bin目录中,找到mongofiles.exe,并输入下面的代码: mongofiles.exe -d gridfs put song.mp3-d gridfs 指定存储文件的数据库名称,如果不存在该数据库,MongoDB会自动创建。如果不存在该数据库,MongoDB会自动创建。Song.mp3 是音频文件名。 使用以下命令来查看数据库中文件的文档: db.fs.files.find()以上命令执行后返回以下文档数据: { _id: ObjectId('534a811bf8b4aa4d33fdf94d'), filename: "song.mp3", chunkSize: 261120, uploadDate: new Date(1397391643474), md5: "e4f53379c909f7bed2e9d631e15c1c41", length: 10401959 }我们可以看到 fs.chunks 集合中所有的区块,以下我们得到了文件的 _id 值,我们可以根据这个 _id 获取区块(chunk)的数据: db.fs.chunks.find({files_id:ObjectId('534a811bf8b4aa4d33fdf94d')})10.自动增长 sequence_value 字段是序列通过自动增长后的一个值。 db.counters.insert({_id:"productid",sequence_value:0}) |




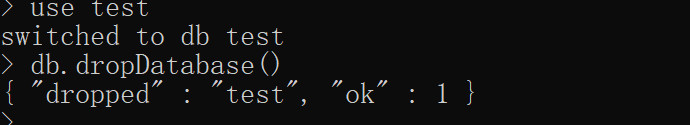




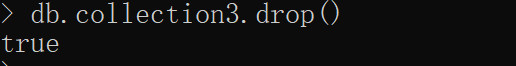









【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |