【目标跟踪】 |
您所在的位置:网站首页 › 孪生网络算法是什么 › 【目标跟踪】 |
【目标跟踪】
|
Visual Object Tracking with Discriminative Filters and Siamese Networks: A Survey and Outlook 本文选取了 90 多个 DCF 和 Siamese 跟踪器进行系统和全面的回顾。首先,介绍了 DCF 和 Siamese 跟踪核心公式的背景理论。 然后,区分和全面回顾了这两种跟踪范式中共享的和各自特定的挑战。 此外,深入分析了 DCF 和 Siamese 跟踪器在 9 个 benchmark 上的性能,涵盖了视觉跟踪的不同方面的实验:数据集、评估指标、性能和速度比较。 在此分析的基础上,提出了对视觉跟踪开放挑战的建议。 两种模型都有一个共同的目标,即学习一个准确的目标外观模型,能够有效地从背景中区分出目标物体。尽管在解决上述目的方面出现了不同的潜在范式,但深度学习的出现给这两种范式带来了一些重要的相似之处和共同的挑战。 相同的挑战包括: 特征表达 从预训练网络中提取深度特征表示是两种范式共同的趋势。然而,深度网络架构和特征层次结构的选择仍然是一个开放的问题;目标状态估计 两种范式的核心公式只解决了如何估计目标对象的平移,但都没有提供一个显式的方法来估计完整的目标状态(边界框参数);离线训练 最初只有 Siamese 跟踪器可以端到端离线训练,但最近的 DCF 也可以利用大规模离线学习,将其与高效、可微的在线学习模块集成,以实现鲁棒和准确的跟踪。各自特定的问题包括: 边界效应 DCF 通常利用训练样本的周期性循环位移来学习在线分类器,这引入了不良的边界效应,严重降低了目标模型的质量;优化问题 DCF 的损失函数优化是一个挑战,特别是在岭回归中加入了空间或时间正则化等目标约束条件时变得更加困难;模型在线自适应 当目标外观发生变化时,模型需要能够应对这些变化。DCF 可以通过损失函数更新外观模型,但 Siamese 跟踪器并没有固有的在线模型更新机制。因此,在线适应性是 Siamese 跟踪器的一个重要问题。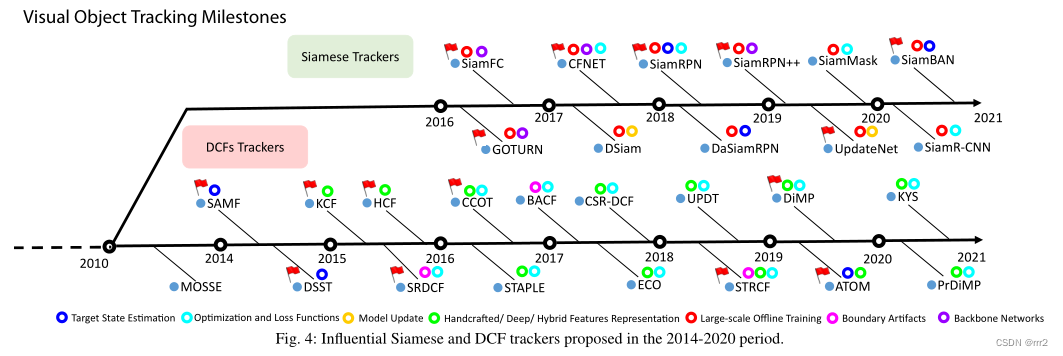 DCF
DCF
DCF是一种有监督的线性回归技术。DCF 成功的关键是通过循环移动训练样本实现稠密采样,这允许在学习和应用相关滤波器时使用快速傅里叶变换 (FFT),大幅提升计算效率。 通过利用傅里叶变换的特性,DCF 在线学习相关滤波器,有效地最小化岭回归误差来定位连续帧中的目标对象。 为了估计下一帧的目标位置,将学习的滤波器应用到感兴趣的区域,其中最大响应的位置估计目标位置,然后以迭代的方式更新滤波器。 早期的 DCF 如 MOOSE 和 CSK 均采用单通道的灰度特征,从 KCF 之后基本都是应用多通道特征,所以这里直接列出多通道的形式,关于单通道的详细推导可以查看原论文。多通道 DCF 优化目标如下: KCF https://blog.csdn.net/u011285477/article/details/53861850 DCF 框架中存在的问题包括特征表达、边界效应、损失优化和目标状态估计,下面分别进行讨论。 特征表达Handcrafted Features 手工特征包括:灰度 / RGB/LAB 等颜色强度特征,Color Names (CN) 特征以及 HOG 特征。 由于其速度和有效性,这些特性已经成为手工方法中的首选。此外,HOG 特征也被有效地与 CN 特征结合起来,以利用形状和颜色信息。 Deep Features 随着 CNN 的发展,许多 DCF 方法将高维非线性的卷积特征用于跟踪,如 HCF、HDT、CCOT、ECO、ASRCF 和 RPCF 等。它们均使用在 ImageNet 上离线预训练的特征,虽然是用于分类任务的特征,但这种深度表示方法适用于广泛的视觉任务。 一些流行的预训练深度网络,如 VGG-19、imagenet-vgg-m-2048、VGG-16、ResNet50 和 googlenet 被用来提取深度特征表示。其中浅层特征包含高分辨率的低层信息,这对精确定位目标非常重要。更深层的特征对复杂的形变具有较高的不变性,可以提高跟踪鲁棒性,同时在很大程度上不受小的平移和尺度变化的影响。 因此,在 DCF 框架中融合浅卷积层和深卷积层的精确策略一直是人们感兴趣的话题。CCOT 中提出了 DCF 框架的连续域公式,实现了多分辨率特征的融合。ECO 研究降低 CCOT 计算成本的策略,并降低过拟合的风险。其他跟踪器如 HDT、HCFTs、MCCT、MCPF、MCPF、LMCF、STRCF、TRACA、DRT、UPDT 和 GFS-DCF 使用后期融合策略集成深度特征。该策略是在每个单独的特征表示上训练一个分类器,然后聚合特征响应图。 End-to-End Features Learning 上述方法依赖离线预训练,而后续研究关注如何在跟踪数据集上端到端优化 DCF 框架,这样可以学到任务特定的深度特征表示来改善跟踪性能。CFNet 以离线方式对相关滤波器进行端到端学习,CREST 和 ACFN 也采用了相同的在线策略。最近,ATOM 额外加入了端到端的尺度估计分支,DiMP 和 PrDiMP 则改进了经典的 DCF 模型,提升了判别能力。 最近DCF跟踪器(ATOM, DiMP, PrDiMP)中端到端特征学习的趋势导致了在多个基准上的优秀跟踪性能,为探索 DCF 范式中更复杂的端到端特征学习铺平了道路。 边界效应DCF 的循环位移操作引入了对跟踪不利的边界效应。具体来说,由于循环位移,训练样本中的负样本并不是真实的背景内容,而是一个较小图像块的不断位移合成的重复。因此,模型在训练过程中看到的背景样本较少,严重限制了其判别能力。 此外,由于周期性重复所造成的失真,预测的目标分数只在图像块的中心附近是准确的,搜索区域的大小因此受到限制。尽管可以通过窗口函数相乘来对其进行预处理。然而,这种技术并不试图解决上述问题,而只是为了消除边界区域的不连续性。针对这一问题,许多方法在 DCF 的目标公式中加入了各种目标特定的空间、时空和平滑约束。 空间正则化 SRDCF 提出了一种空间正则化来控制滤波器的空间扩展,以缓解边界问题,公式如下: 约束优化 SRDCF 的目的是惩罚目标区域外的滤波系数,而 Kiani 等人提出引入硬约束(BACF)。该策略强制滤波系数w 在目标区域外为零。优化公式可以通过引入二进制掩码 P 来表示: 隐式方法 GFS-DCF 提出了一种联合特征选择模型,该模型同时学习三个正则化项:空间正则化用于特征选择,通道正则化用于特征通道选择,低秩时间正则化项用于增强滤波权值的平滑性。Mueller 等人提出 CACF 对每个目标 patch 的上下文信息进行正则化。在每一帧中,CACF 对几个上下文补丁进行采样,作为负样本。 空域形式 最近,ATOM 和 DiMP 采用低分辨率(16 倍降采样)的深度特征,可以以小尺寸卷积核()的形式在空间域中直接学习滤波器。这种方法完全绕开了边界效应,因为不需要周期性地扩展训练样本。 基于正则化的 (SRDCF, STRCF) 和基于约束的 (CFLB/BACF) 方法都取得了巨大成功,并被广泛应用于跟踪器中。最近的深度学习方法 (ATOM/DiMP) 通过直接在空域中优化滤波器,已经完全避开了边界效应问题。因此,虽然傅里叶域对高分辨率特征的计算具有吸引力,但在使用强大的低分辨率深度特征时,高效的空域优化方法在在线学习中占优。因此,目前基于 DCF 的 SOTA 方法研究采用了空域优化的形式,不需要额外的策略来缓解边界效应。 优化问题标准的 DCF 优化利用循环矩阵在傅里叶域可对角化的性质来求解岭回归的闭式解。这套方法无法处理有额外正则项或约束条件的优化问题,下面总结几种有效的模型优化方法。 Gauss-Seidel Method 代表方法:DeepSRDCF,采用 Gauss-Seidel 迭代速度非常慢,大概只有每秒几帧。 Conjugate Gradient Based Method 共轭梯度最早用于 CCOT,可作用于任意一组满秩的正规方程 。它通过寻找共轭方向 和最优步长 来更新滤波器 。该算法在有限次迭代次数中收敛到解,但在实际应用中,算法在固定次数的迭代后或当误差降低到令人满意的水平时停止。CG 在处理 D 维特征时,复杂度从 Gauss-Seidel 的二次复杂度 降为线性的 ,因此可以用于高维的深度特征优化。 针对非线性最小二乘问题,Gauss-Newton 法也被用于许多跟踪器,包括 ECO、ATOM 和 UPDT。该方法对误差使用泰勒级数展开,找到一个二次逼近的目标。由此产生的二次问题可以用迭代方法处理,例如上面描述的 CG 方法。在 ECO 和 ATOM 中,采用 Gauss-Newton 结合 CG 对滤波器 和降维矩阵进行联合优化。DiMP 使用 Gauss-Newton 和 Steepest Descent 迭代来学习滤波器。优化步骤本身是可微分的,这进一步支持端到端的学习。PrDiMP 进一步使用更一般的牛顿近似来处理凸且非线性 KL 散度目标函数。 Alternating Direction Method of Multipliers (ADMM) Method ADMM 方法近年来被广泛应用于 DCF 中,特别是引入额外正则项的优化上。ADMM 将大的全局问题分解为多个较小、较容易求解的局部子问题,并通过协调子问题的解而得到大的全局问题的解。基于 ADMM 的优化方法为每个子问题提供了闭式解,并且在非常少的迭代内收敛。BACF、DRT、AutoTrack、ARCF 和 RPCF 等跟踪器都采用 ADMM 来实现高效的求解。 目标状态估计Multiple Resolution Scale Search Method 多尺度金字塔搜索是最简单粗暴的方法,首先按不同的比例因子调整图像大小,然后在每个尺度进行估计,选择分数最大的位置和尺度作为最终结果。在一定程度上可以提升尺度估计的准确性,但是多尺度采样带来较大的计算负担,且只能等比例缩放边界框。 Discriminative Scale Space Search Method 即 DSST 为代表的方法,将目标状态估计分两步进行。由于两帧之间的尺度变化通常较小或中等,首先通过在当前的尺度估计上应用通常的平移滤波器来找到目标平移。然后,在尺度维度上应用单独的一维滤波器来更新目标尺寸。好处有两方面:1)通过减小搜索空间来提高计算效率;2)对尺度滤波器进行训练,区分不同尺度下目标的外观,从而得到更准确的估计。后续的 fDSST 跟踪器通过应用 PCA 和子网格插值 [27] 降低了 DSST 的计算开销。 Deep Bounding Box Regression Method 上述方法依赖于比例因子参数和在线精确相关滤波器响应,没有以离线方式利用强大的深度特征表示。此外,这些在线方法不执行任何边界框回归。因此,这些方法在尺度突然变化的情况下表现出性能下降。精确估计目标边框是一项复杂的任务,需要高层次的先验知识,不能被建模为一个简单的图像变换 (例如统一的图像缩放)。 边界框回归在目标检测中有广泛的应用,ATOM 就借鉴了检测中的IOUNet来进行状态估计。考虑到检测网络具有 class-specific 的特性,不适合 target-specific 的跟踪任务,Martin 设计了一个调制网络嵌入参考帧中的目标外观信息从而得到 target-specific 的 IOU 预测。在跟踪过程中,通过简单地最大化每帧的预测 IOU 来找到目标框。结果表明,与传统的多尺度搜索方法相比,该方法的性能有了显著提高。后续的 DiMP, PrDiMP 和 KYS 都采用了这种策略,其中 PrDiMP 使用基于能量的模型来预测边界框的非归一化概率密度,而不是预测 IOU,通过最小化 KL 散度和高斯标签来训练的。 基于分割的 DCF目标分割为跟踪提供了可靠的目标观测,解决了旋转目标框、遮挡、变形、缩放等跟踪问题。Bertinetto 等人使用了一种基于颜色直方图的分割方法来改进在不同光照变化、运动模糊和目标变形下的跟踪。Lukezic 等人提出了一种使用基于颜色的分割方法来正则化滤波学习的空间可靠性图。Kart 等人将 CSR-DCF 跟踪器扩展到基于颜色和深度分割的 RGB-D 跟踪,深度线索提供了更可靠的分割图。Lukezic 等人提出了一种 single shot 分割跟踪器来解决联合框架内的 VOT 和 VOS 问题,采用两种判别模型进行编码,用于联合跟踪和分割任务。最近,Robinson 等人利用 ATOM 的快速优化方案,将一种功能强大的判别模型用于视频对象分割任务。Bhat 等人也使用了目标模型区分能力来实现更鲁棒的视频对象分割。 SIAMESE TRACKERS
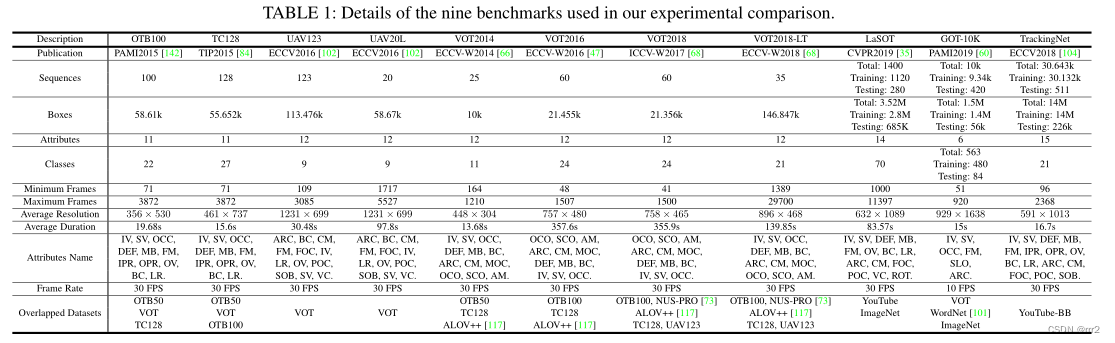
Training Pipeline 以 SiamFC 为例,输入一对训练图像 (x, z),x 表示感兴趣的对象(第一帧裁剪的图像块)和 z 表示后续帧的搜索图像区域。将这些图像对输入 CNN 中,以获得两个特征图,然后使用互相关进行匹配: 训练目标是使得响应图g的最大值与目标位置相对应,因此采用 logistic loss: 其中v是预测值,c={-1,1} 是标签。 同期的其他一些工作,如:SINT 使用欧式距离作为相似度量,而不是互相关;GOTURN 预测的是边框回归的结果;CFNET 将相关滤波器作为匹配函数中的一个独立模块加入到 x 中,使该网络更浅更高效。 Testing Pipeline 测试过程就是利用学到的匹配函数度量 x 在 z 上每个匹配区域的相似度,用得分最高的位置预测目标的新位置。最初的 SiamFC 只是将每一帧与目标的初始外观进行比较,并在 GPU 上以 140FPS 的速度实时跟踪。Siamese 跟踪器在推理和离线学习中都具有极高的计算效率,并且跟踪性能卓越,因此在跟踪社区中受到了很多关注。 问题经典的 在准确性和效率上都优于 DCF 跟踪器。然而,Siamese 在 backbone 提取网络、离线训练时需要大量的标注图像对、缺乏在线适应性、损失函数、目标状态估计等方面也存在一定的局限性。下面将讨论这些问题并概述近年来发展的解决方案。 Backbone 结构早期的 Siamese 跟踪器均使用 AlexNet 作为特征提取,包括 SiamFC, GOTURN, SINT, FlowTrack, MemTrack, EAST 和 SiamRPN。然而,这些跟踪器在性能上仍然有限,因为 AlexNet 是一个相对较浅的网络,并没有产生非常强的特征表示。直接替换更深的网络并不能取得性能上的提升。 为了解决这一问题,SiamRPN++ 研究发现,在 SNs 中,**网络中的 padding 使得学习到的特征表示不满足空间平移不变性约束。**因此,提出了一种有效的采样技术来满足这种空间不变性约束。利用强大的深层 ResNet 架构,许多 Siamese 跟踪器的性能得到了改善。Zhang 等人也研究了同样的问题,并提出了 SiamDW,其中浅骨干 AlexNet 被包括 Inception、VGG-19 和 ResNet 在内的深网络所取代。研究发现,除了 padding 外,感受野和网络步长也是深层网络不能直接替代浅层网络的主要原因。有了这些基础,最近的跟踪器包括 SiamCAR、Ocean 和 SiamBAN 等都使用了更深的网络结构。 由于 ResNet 的简单性和强大的性能,ResNet 已经成为 Siamese 跟踪的首选方案。然而,Transformer 的最新进展预计将在未来几年对跟踪社区产生重大影响。 离线训练当前流行的跟踪训练数据集包括:ImageNet ILSVRC2014、ILSVRC2015、COCO、YouTube-BB、YouTube-VOS、LaSOT、GOT-10k 和 TrackingNet。这些数据集充分覆盖了大量的语义,并且不关注特定的对象,否则在 Siamese 训练中,调优后的网络参数会过拟合到特定的对象类别。 与 DCF 范式不同,标准的 Siamese 范式不能利用跟踪过程中的已知干扰物。因此,当与目标本身相似的物体出现时,Siamese 跟踪器通常不能很好地处理。早期的方法只在训练过程中对同一视频中的训练图像进行采样,这种抽样策略不关注具有语义相似干扰物的情况。为了解决这个问题,Zhu 等人在 DaSiamRPN 中引入了难负样本挖掘技术,通过在训练过程中引入更多的语义负样本对来克服数据不平衡。构建的负样本对由相同和不同类别的标记目标组成。该技术通过更多地关注细粒度表示,帮助 DaSiamRPN 克服漂移。Voigtlaender (SiamRCNN) 等人利用嵌入网络和最近邻近似提出了另一种难负样本挖掘技术。对于每个真实目标框,使用预训练网络为相似的目标外观提取嵌入向量。 然后使用索引结构估计近似最近邻,并使用它们估计嵌入空间中目标对象的最近邻。 近年来,利用更多的训练数据和设计数据挖掘技术的趋势在多个基准上显示出了良好的跟踪性能。 在线模型更新在 SiamFC 中,目标模板在第一帧中初始化,然后在视频的剩余部分中保持固定。跟踪器不进行任何模型更新,因此其性能完全依赖于 SN 的泛化能力。然而当外观变化很大时,不更新模型往往导致跟踪失败。下面将介绍模型更新方向的潜在解决方案。 Moving Average Update Method 最简单的线性更新策略,使用固定学习率的对模板滑动平均更新。虽然它提供了一种集成新信息的简单方法,但由于恒定的更新速率和简单的线性模板组合,导致跟踪器无法从漂移中恢复。 Learning Dynamic SN Method DSiam 设计了两个动态变换矩阵,包括目标外观变化和背景抑制。这两个矩阵都在傅里叶域中用闭式解进行求解。DSiam 提供了有效的在线学习,但它忽略了历史目标变化,这对于更平滑地适应模板非常重要。 Dynamic Memory Network Method MemTrack 可以动态写入和读取以前的模板,以应对目标外观的变化。使用 LSTM 作为存储器控制器,输入是搜索特征图,输出存储器读写过程的控制信号。这种方法使跟踪器能够记忆长期目标外观。然而,该算法只关注目标特征,忽略了背景杂波中的鉴别信息,在目标变化剧烈的情况下,会导致精度下降。 Gradient-Guided Method Li 等人提出了 GradNet,对梯度信息进行编码,通过前向和后向操作更新目标模板。跟踪器利用梯度信息更新当前帧中的模板,然后加入自适应过程,简化基于梯度的优化过程。与上述方法不同的是,该方法充分利用了反向传播梯度中的判别信息,而不是仅仅集成之前的模板。这样可以提高算法性能,但代价是以反向传播的方式计算梯度引入了计算负担。 UpdateNet Method UpdateNet 利用一个 CNN 整合了初始模板、历史累计模板、以及当前帧模板,进行自适应更新。基于现有模板与累积模板的差异,可以适应现有框架的具体更新要求。 此外,在每帧中还考虑了初始模板,提供了高度可靠的信息,增加了对模型漂移的鲁棒性。结果表明,与 SiamFC 和 DaSiamRPN 相比,该方法具有优异的性能。 虽然已经提出了许多模型更新的技术,但简单地不使用更新仍然是一种鲁棒且流行的选择。在这个方向上的进一步研究需要开发简单的、通用的、端到端可训练的技术,从而进一步提高 Siamese 跟踪的鲁棒性。 损失函数损失函数主要包括分类和回归两种任务。 Logistic Loss 如上述公式 16-17 所示,早期方法均采用逻辑损失,包括 SiamFC, DSiam, RASNET, SA-SIAM, CFNET, SiamDW 和 GradNet。该训练方法利用图像对上的成对关系,在正样本对上相似性分数最大化,在负样本对上相似性分数最小化。 Contrastive Loss SINT 采用了 contrastive loss,而 GOTURN 采用了预测和真实目标框之间的 L1 loss。 Cross Entropy Loss SNs 中的分类分支借鉴了目标检测中常用的交叉熵损失。SiamRPN 最早将检测思想引入 SNs 并使用了交叉熵损失。后续在其基础上,SiamRPN++, SiamAttn, Ocean, CLNET, SPM, C-RPN 均使用交叉熵损失用于训练分类分支。 Regression Loss 回归损失使用较多的为 smooth L1 loss (SiamRPN, SiamRPN++, SiamAttn, CLNET, SPM, C-RPN) 和 IOU loss (SiamBAN, Ocean, SiamFC++)。 Multi-Task Loss 对于分类分支和回归分支的联合训练,需要多任务损失。如交叉熵 + smooth L1 loss 或交叉熵 + IOU loss。 Regularized Linear Regression 为了将相关滤波作为一个单独的层加入 SNs,需要使用公式 9-10 的线性回归损失。将岭回归问题通过闭式解的形式解决,并以端到端方式嵌入整个训练框架,代表方法有:CFNET, TADT, RTINET, DSiam, FlowTrack, UDT, UDT++。 目前,关于损失函数的研究还没有普遍的共识。相反,最近的 SOTA 方法采用了不同的替代方法。在上述方法中,交叉熵损失仍然是最近的跟踪器一个普遍的选择 目标状态估计与 DCF 类似,SNs 也面临尺度变化的挑战。相似函数只能学习图像之间深层结构关系,没有考虑尺度变化问题。下面将讨论这一方面的发展。 Multiple Resolution Scale Search Method 最早期的方法仍然是简单粗暴的多尺度搜索,如如 RASNET、SA-Siam、StructSiam、UDT、UDT++、TADT、GradeNet、RTINET、FlowTrack。 Deep Anchor-based Bounding Box Regression Method 基于锚框的边框回归利用目标检测中的 RPN 网络来预测具有多种尺度和宽高比的 proposal。RPN 是一个全卷积网络,它同时预测每个位置的分类分数和边框回归。RPN 以端到端方式进行训练,以生成高质量的 proposal。最早运用 RPN 的跟踪器是 SiamRPN,包括一个分类分支和回归分支,相比传统方法取得了显著的进步。之后的 DaSiamRPN, SiamRPN++, SiamDW , SPLT, C-RPN, SiamAttn, CSA, SPM 等也建立在相同的概念上。 Deep Anchor-free Bounding Box Regression Method 上述基于锚框的方法需要启发式知识精心设计锚箱,引入了许多超参数和计算复杂度。因此目标检测中提出了无锚框的方法,避免了设计与锚框相关的超参数,更加灵活通用。无锚框方法分为 keypoint-based 和 center-based 两种,前者首先定位预定义的关键点,然后在目标上执行边框回归;后者则预测目标中心正样本区域到边界的四个距离。无锚检测器能够消除与锚框相关的超参数,性能与基于锚框的检测器相似,具有更强的泛化能力。典型的无锚框孪生跟踪算法包括 SiamBAN, Ocean, SiamCAR 等。 目标检测技术在目标状态估计方面取得了显著的进展。最近使用 RPN 和无锚框回归结构的趋势表明,可以在端到端范例中进一步探索这些技术 跟踪数据集为了提供一个标准和公平的目标跟踪器性能评估,许多 benchmarks 被提出。除了短期跟踪外,一些最近的数据集提供了短期和长期跟踪序列。公开的基准数据集包含各种跟踪挑战,包括尺度变化 (SV),出视野 (OV),形变 (DEF),低分辨率 (LR),光照变化 (IV),平面外旋转 (OPR),遮挡 (OCC),背景杂波 (BC),快速运动 (FM),平面内旋转 (IPR),运动模糊 (MB)、部分遮挡 (POC)、摄像机突然运动 (CM)、长宽比变化 (ARC)、全遮挡 (FOC)、视点变化 (VC)、相似物体 (SOB)、物体颜色变化 (OCC)、绝对运动 (SOB)、目标旋转 (ROT)、场景复杂度 (SCO)、快速摄像机运动 (FCM)、低分辨率物体 (LRO)、运动变化 (MOC)。表 1 给出了我们在实验比较中使用的每个数据集的描述。接下来,简要描述每个跟踪数据集。 OTB100 22 个对象类别的 100 个视频组成,与 OTB50 相同的 11 个跟踪属性。OTB100 数据集的平均分辨率为 356 × 530,视频长度在 71 - 3872 帧之间。 TC128 TC128 用于评价颜色对视觉跟踪的影响。它包含 27 个对象类别的 128 个完整标注的彩色视频序列。在 128 个序列中,有 78 个序列不同于 OTB100,而剩下的 50 个序列在两个数据集中是共同的。TC128 也包含 11 个跟踪属性,类似于 OTB100 (表 1),平均分辨率为 461 × 737,最小帧数 71 帧,最大帧数 3872 帧。 UAV123 UAV 是低空无人机捕获的真实和合成高清视频序列,分为两个子集,UAV123 和 UAV20L。UAV123 包含 9 种对象类别的 123 个短序列,最小帧数 109 帧,最大帧数 3085 帧。UAV20L 由飞行模拟器生成的 5 个对象类的 20 个长视频组成。这些序列包含最小 1717 帧和最大 5527 帧。两个数据集子集都包含 1231 × 699 的平均分辨率,并带有 12 个跟踪属性。 VOT2016 包含 60 个序列,每个序列每帧都由不同的属性标注,包括 OCC、IV、MOC、ARC、SCO 和 FCM。序列的平均分辨率为 757×480,最小帧数为 48,最大帧数为 1507。 VOT2018 该数据集由短期和长期挑战组成。VOT2018 ShortTerm (VOT2018-st) 挑战由 24 个对象类别的 60 个序列组成。短期挑战序列的平均分辨率为 758 × 465,最小帧数为 41 帧,最大帧数为 1500 帧。长期分割由 35 个长期序列组成。序列的长期平均分辨率为 896 × 468,最小帧数为 1389,最大帧数为 29700。 VOT2020 由五个子集组成,我们使用 VOT2020 短期 (VOT2020-st) 数据集来评估跟踪器的性能。VOT2020-ST 与 VOT2018-ST 在视频数量、类数量和属性数量方面相同。区别在于标注由 mask 编码,并且重新定义了 A,R,EAO。可以参考我之前写的 VOT2020 测评指标。 TrackingNet 由 60643 个序列和超过 1400 万个密集的包围框注释组成。它涵盖了 27 个不同的对象类。序列也由 15 个跟踪属性表示。数据集被划分为训练、验证和测试部分。训练集包含 30643 个序列,而测试集包含 511 个视频。在测试集中,序列的平均分辨率为 591 × 1013,最小帧数为 96,最大帧数为 2368,帧数为 30fps。 LaSOT 由 1120 个训练序列 (2.8M 帧) 和 280 个测试序列 (685K 帧) 组成。在每一帧中,所有序列都用边界框标注。对象类别是从 ImageNet 中选择的,包含 70 个不同的对象类别,每个类别包含 20 个目标序列。根据 ARC、BC、FCM、DEF、POC、ROT 和 VC 等 14 个属性对序列进行分类。序列的平均分辨率为 632 × 1089。此外,该数据集包含非常长的序列,范围在 1000 到 11,397 帧之间。 GOT -10K 由 WordNet 语义层次结构中的 10,000 个视频组成。目的是为开发具有丰富运动轨迹的类无关跟踪器提供统一的训练和测试平台。这些序列被分类为 563 类运动物体、6 种跟踪属性和 87 类运动,以覆盖现实世界中尽可能多的具有挑战性的模式。GOT-10K 分为训练、验证和测试三部分。训练集包含 9340 个序列,480 个物体类别;测试集包含 420 个视频,83 个物体类别,每个序列平均长度为 127 帧。在测试集中,序列的平均分辨率为 929 × 1638,最小帧数为 51,最大帧数为 920,帧数为 10fps。 Precision Plot 精度曲线基于中心位置误差,中心位置误差定义为目标物体的预测中心与真实目标框中心之间的平均欧氏距离。距离精度,定义为目标物体的中心定位误差在 T 像素范围内的帧数所占的百分比。通过绘制阈值范围内的距离精度来生成精度曲线,使用 T=20 的精度对跟踪器进行排名。 Success Plot 精度只度量跟踪器的定位性能,对于测量目标尺度变化不准确。因此考虑用 IOU 来衡量这一指标,成功率是预测 IOU 大于阈值 T 的百分比。通过将 IOU 阈值从 0 改变到 1 来生成成功率曲线,使用曲线下的面积对跟踪器进行排名。 Normalized Precision Plot 由于距离精度对目标尺度敏感,因此引入归一化精度,它计算相对于目标大小的误差,而不是考虑绝对距离。然后在 0 到 0.5 的范围内绘制相对误差曲线,这条曲线下的面积称为归一化精度,用于对跟踪器进行排序。 Average Overlap 度量预测和真实框的重叠率的平均值。 和 阈值为 0.50 和 0.75 时的成功率。 在 OTB100、TC128、UAV123 和 LaSOT 数据集上,使用 One pass 评估标准,从精度和成功率方面衡量跟踪性能。这些数据集上的跟踪器是通过在第一帧上初始化并让它运行到序列的末尾来计算的。 在 VOT 系列中,跟踪器一旦偏离目标就会被重置。VOT 评估协议根据准确性 (A),鲁棒性 ® 和期望平均重叠 (EAO) 对跟踪器进行比较。A 是成功跟踪期间预测和真值的平均重叠。R 表示跟踪器在跟踪过程中丢失目标 (失败) 的次数。一旦跟踪器丢失目标对象,复位机制将在某些帧后启动。EAO 是一种估计跟踪器期望在与给定数据集具有相同视觉特性的大量短期序列上获得的平均重叠。 速度比较KCF 和 STAPLE 追踪器的速度明显最好,而 DeepSRDCF 和 HCF 等借助离线深度学习特征的跟踪器速度较慢。 DISCUSSION AND CONCLUSIONSImportance of end-to-end tracking framework 端到端训练不管对 DCF 还是 Siamese 跟踪都非常管用。随着大规模训练数据集的引入,这在过去几年才成为可能。 Importance of robust target modeling 虽然基于 Siamese 的方法在许多领域都表现出色,但基于端到端 DCF 的方法在挑战长期跟踪场景 (如 LaSOT) 方面仍然显示出优势。这说明了通过在网络结构中嵌入判别学习模块来实现鲁棒在线目标外观建模的重要性。这些方法有效地整合了背景外观线索,并且在使用在线学习的跟踪过程中易于更新。 Target state estimation 基于 Siamese 的方法通过利用目标检测技术,推动了更精确的边框回归的进步。最近的基于单阶段 (无锚框) 的方法,如 Ocean,实现了简单、准确和高效的边框回归。此外,这些策略是通用的,可以很容易地集成到任何视觉跟踪架构中。 Role of segmentation 分割可以提供更精确的像素级预测,此外,分割还可以改善跟踪本身的潜力,例如辅助目标模型更新。因此,未来的工作应着眼于将准确的分割集成到跟踪框架中。 Backbone architectures ResNet 在视觉跟踪中仍然是最常用的特征提取方法,但在计算资源受限的平台 ResNet 的计算成本仍然较高。因此未来研究移动平台的高效 backbone 仍然是一个有趣的方向。 Estimating geometry 将 DCF 和 Siamese 方法往 3D 方向扩展。 Role of Transformers Transformer 最近在各种视觉任务上都取得了成功,也被应用到了跟踪。未来还需要做更多的工作来进一步分析 Transformer 的有效性,以及它与 DCF 和 Siamese 的联系。 Future directions 1)与分割结合;2)与 SLAM 结合;3)与多目标跟踪结合。 |
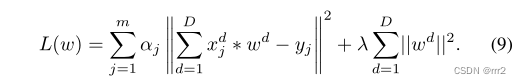 其中 d表示特征维度, m是样本个数, x,y分别对应训练样本和标签,w 表示是滤波器参数。通过利用 FFT 转到频域求解:
其中 d表示特征维度, m是样本个数, x,y分别对应训练样本和标签,w 表示是滤波器参数。通过利用 FFT 转到频域求解: 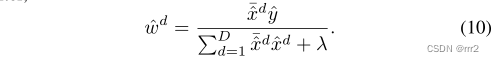
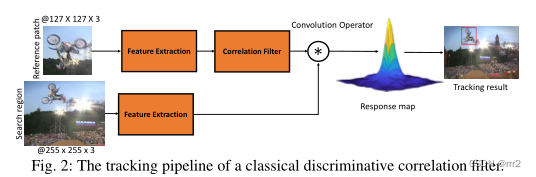 DCF 跟踪流程如图 2 所示,首先在第一帧学习滤波器w ,然后在后续帧进行检测,并更新滤波器参数。第 m 帧的检测公式计算如下:
DCF 跟踪流程如图 2 所示,首先在第一帧学习滤波器w ,然后在后续帧进行检测,并更新滤波器参数。第 m 帧的检测公式计算如下: 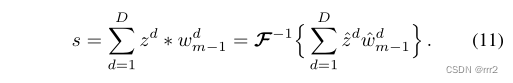 其中 z为根据上一帧的检测结果裁剪的 patch, w_m-1 为从初始帧一直递归更新到上一帧的滤波器,二者通过卷积运算得到每个位置的目标分数 s。其中 s中响应最大的位置为当前检测的目标位置,并在此位置裁剪新的 patch 用于更新滤波器参数。
其中 z为根据上一帧的检测结果裁剪的 patch, w_m-1 为从初始帧一直递归更新到上一帧的滤波器,二者通过卷积运算得到每个位置的目标分数 s。其中 s中响应最大的位置为当前检测的目标位置,并在此位置裁剪新的 patch 用于更新滤波器参数。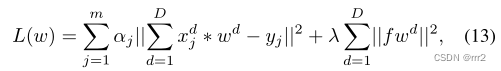 其中空间权重函数f>0 ,在背景像素处取大值,在目标区域内取小值,对背景滤波系数进行惩罚。这样可以在一个更大的搜索图像上学到一个聚焦于目标区域的紧凑型滤波器。空间正则化策略已被应用于各种跟踪器中,包括 ARCF、ASRCF 和 AutoTrack。为了提高 SRDCF 的效率,Li 等人提出了 STRCF,它只使用单一的训练样本,而引入了时间正则化项来整合历史信息。
其中空间权重函数f>0 ,在背景像素处取大值,在目标区域内取小值,对背景滤波系数进行惩罚。这样可以在一个更大的搜索图像上学到一个聚焦于目标区域的紧凑型滤波器。空间正则化策略已被应用于各种跟踪器中,包括 ARCF、ASRCF 和 AutoTrack。为了提高 SRDCF 的效率,Li 等人提出了 STRCF,它只使用单一的训练样本,而引入了时间正则化项来整合历史信息。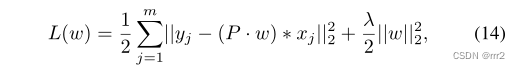 其中 pw掩盖了背景特征对于滤波器参数的影响,目标函数采用 ADMM 迭代优化。公式 (13) 和 (14) 中所研究的特定于目标的约束通常针对不同的对象是固定的,并且在跟踪过程中不会发生变化。最近,Dai 等人通过引入自适应正则化项来扩展 BACF 和 SRDCF。
其中 pw掩盖了背景特征对于滤波器参数的影响,目标函数采用 ADMM 迭代优化。公式 (13) 和 (14) 中所研究的特定于目标的约束通常针对不同的对象是固定的,并且在跟踪过程中不会发生变化。最近,Dai 等人通过引入自适应正则化项来扩展 BACF 和 SRDCF。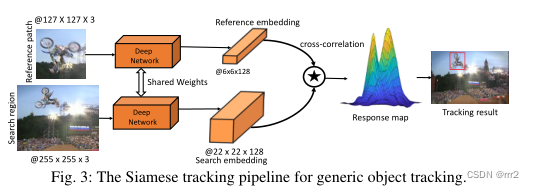 深度学习模型成功的关键是特征在大量数据上的离线学习能力,能够从大量标注的数据中学习复杂而丰富的关系。 孪生网络将目标跟踪看成一个相似性学习问题,通过端到端的离线训练来学习目标图像和搜索区域之间的相似性。Siamese 跟踪器由模板分支和检测分支组成,模板分支输入初始目标图像块,检测分支输入当前帧图像块。这两个分支共享 CNN 参数,使得两个图像块编码了适合跟踪的相同变换。Siamese 跟踪框架如图 3 所示,其主要目标是克服预训练 CNN 的局限性,充分利用端到端学习。 离线训练视频用于指导跟踪器处理旋转、视点变化、光照变化和其他复杂的挑战。Siamese 跟踪器能够学习物体运动和外观之间的一般关系,并可以用来定位训练中未见过的目标。
深度学习模型成功的关键是特征在大量数据上的离线学习能力,能够从大量标注的数据中学习复杂而丰富的关系。 孪生网络将目标跟踪看成一个相似性学习问题,通过端到端的离线训练来学习目标图像和搜索区域之间的相似性。Siamese 跟踪器由模板分支和检测分支组成,模板分支输入初始目标图像块,检测分支输入当前帧图像块。这两个分支共享 CNN 参数,使得两个图像块编码了适合跟踪的相同变换。Siamese 跟踪框架如图 3 所示,其主要目标是克服预训练 CNN 的局限性,充分利用端到端学习。 离线训练视频用于指导跟踪器处理旋转、视点变化、光照变化和其他复杂的挑战。Siamese 跟踪器能够学习物体运动和外观之间的一般关系,并可以用来定位训练中未见过的目标。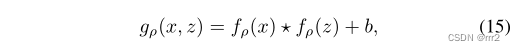 其中星号表示互相关, fp表示 CNN,如 AlexNet,模型参数为 p。 g表示 x 和 z 之间相似性的响应映射, b是常数标量。
其中星号表示互相关, fp表示 CNN,如 AlexNet,模型参数为 p。 g表示 x 和 z 之间相似性的响应映射, b是常数标量。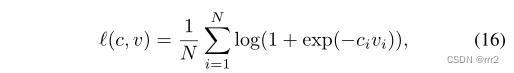
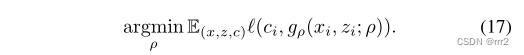
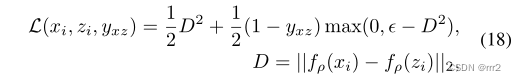
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |