【IntelliJ IDEA】UTF |
您所在的位置:网站首页 › 如何把中文转成乱码 › 【IntelliJ IDEA】UTF |
【IntelliJ IDEA】UTF
|
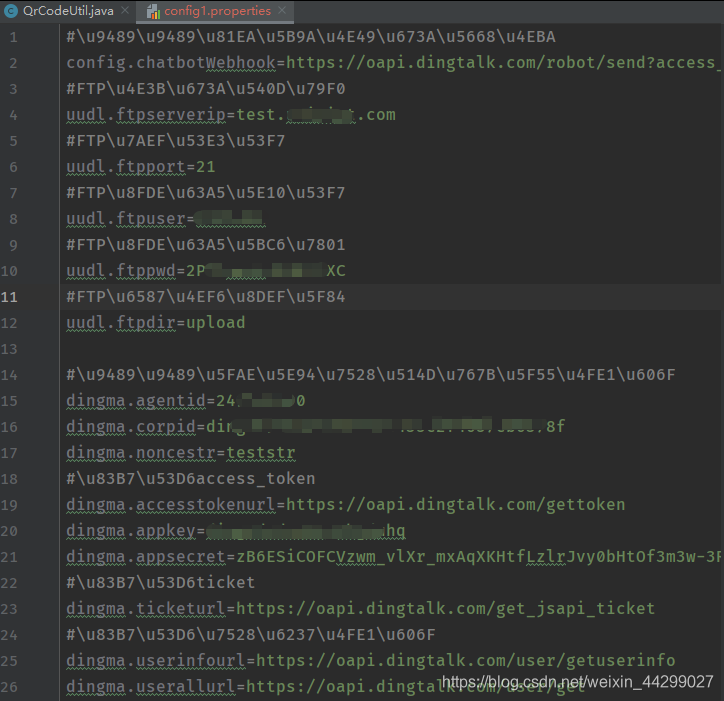
本文目录 一、背景描述 二、问题原因 三、解决方案 一、背景描述本地开发环境,Windows 10 + IntelliJ IDEA + Spring boot项目。 在开发项目中遇见设置文件编码格式为UTF-8,但是打开该文件出现类似\u9489\u9489\u81EA\u5B9A\u4E49\u673A\u5668\u4EBA这样的数据,看也看不懂,也不是平常见到的乱码。这里的\u9489\u9489\u81EA\u5B9A\u4E49\u673A\u5668\u4EBA类似的数据,其中'\u'表示UNICODE编码,其实数据就是对应的UTF-8下的汉字。 \u9489\u9489\u81EA\u5B9A\u4E49\u673A\u5668\u4EBA 此处代表的汉字是“钉钉自定义机器人”。
此处的文件(config.properties)编码格式为UTF-8,而Idea编辑器里的文件编码跟随电脑的操作系统里(Windows 10,默认的是GBK编码)的文件编码格式保持了一致。 三、解决方案打开IDEA的设置,找到设置编码的页面。菜单路径是 File --> Settings --> Editor --> File Encodings。(其他编辑器请自行百度) (1)设置全局编码(Global Encoding)、工程编码(Project Encoding)、文件(Properties Files/*.properties)默认编码为UTF-8.(2)勾选Transparent native-to-ascii conversion选项(3)点击按钮Apply、OK应用即可
修改完Idea的配置之后,即可看到Unicode字符自动转为中文,如下图所示:
拓展: 需要在线转UNICODE编码与对应的UTF-8下的汉字以及互转的同学,可以点击链接,已经亲测,完全满足需求。Unicode与中文互转 16进制Unicode编码转换、还原:http://www.msxindl.com/tools/unicode16.asp
完结! |

【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |