Python数据分析 |
您所在的位置:网站首页 › 好电影包含哪些因素 › Python数据分析 |
Python数据分析
|
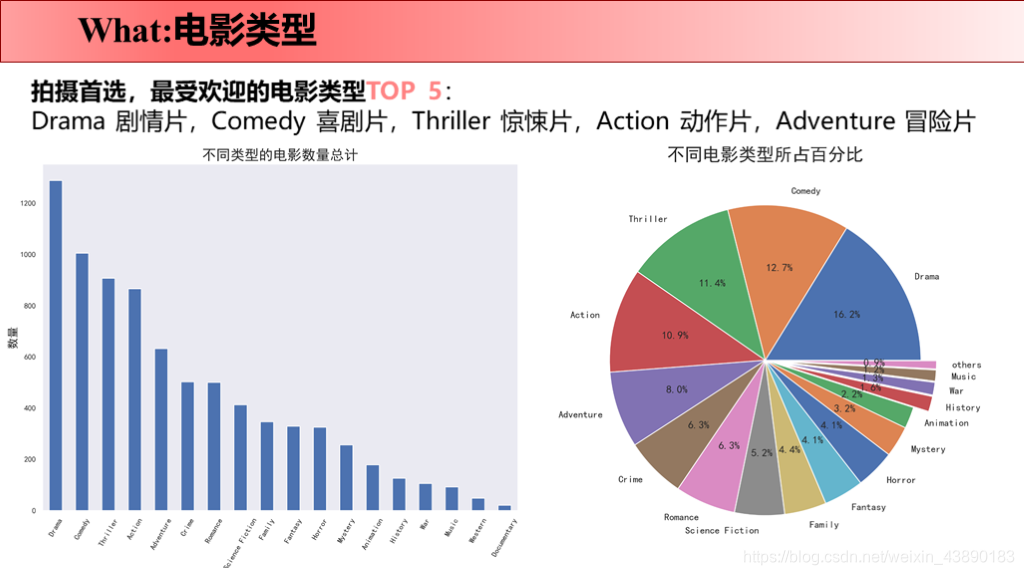
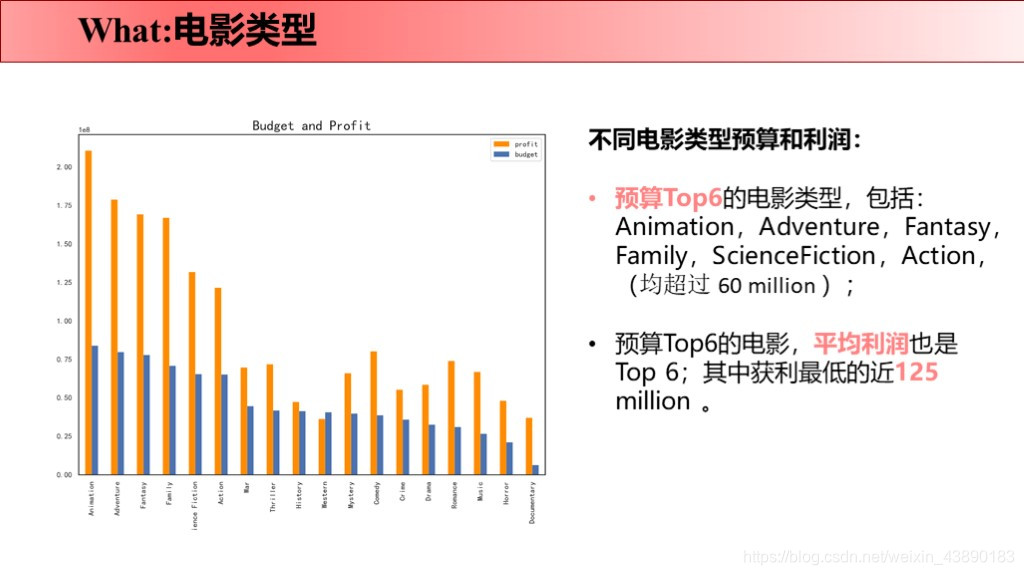
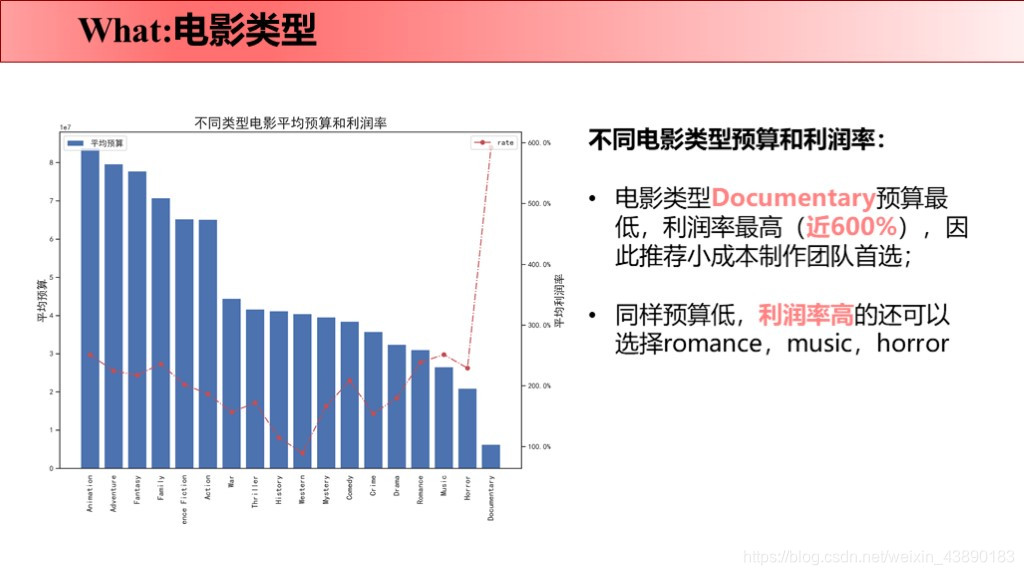
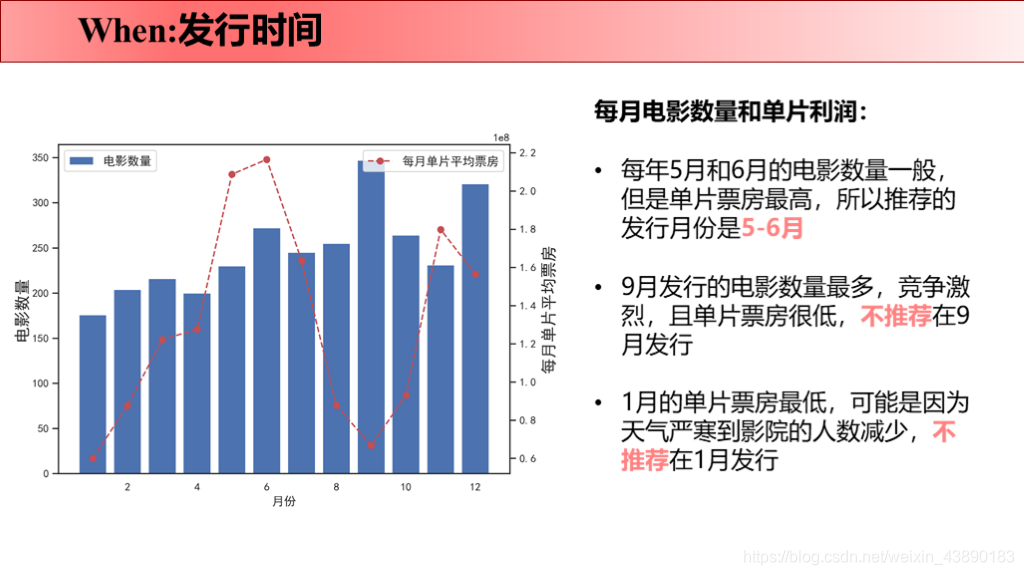
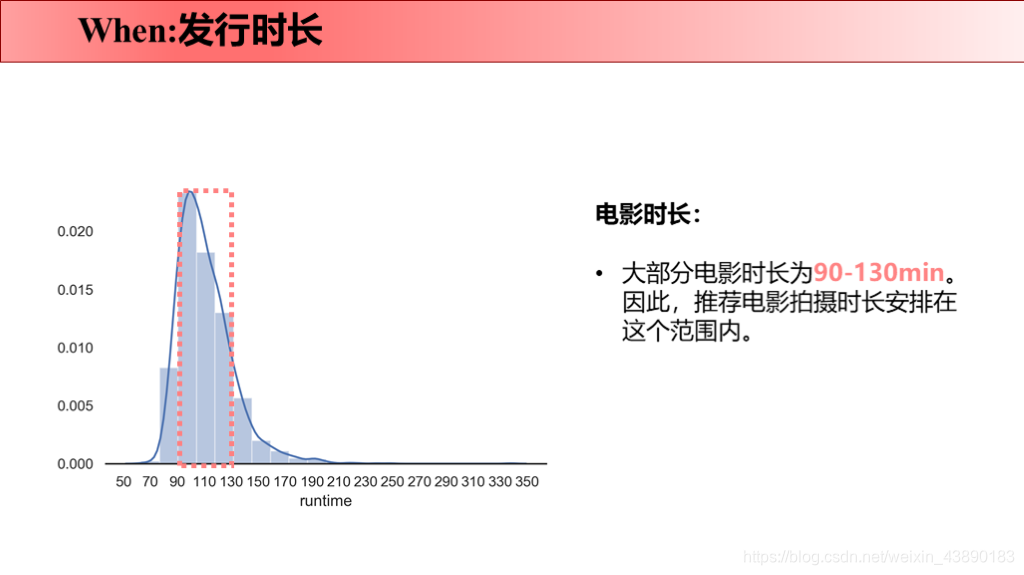
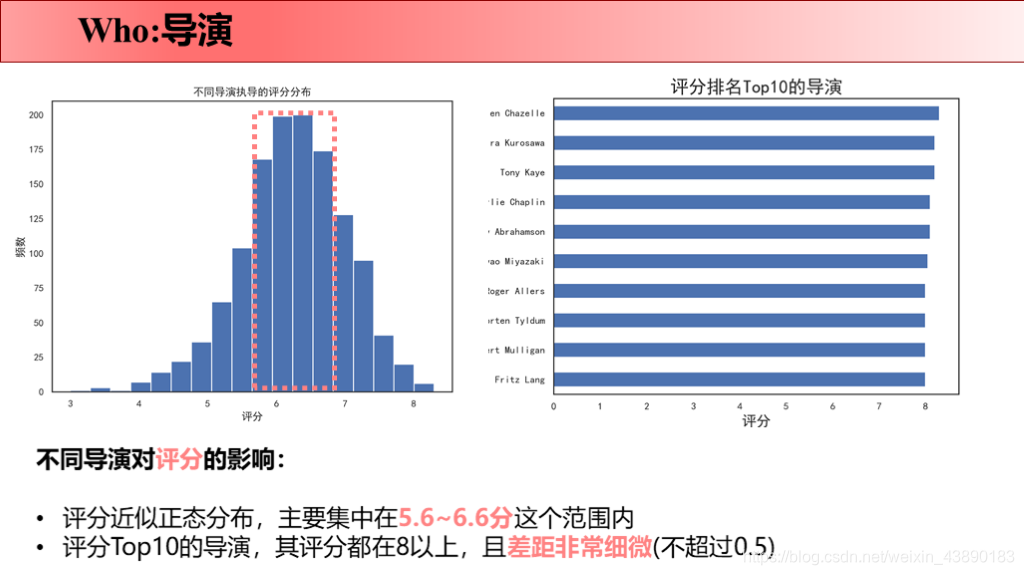
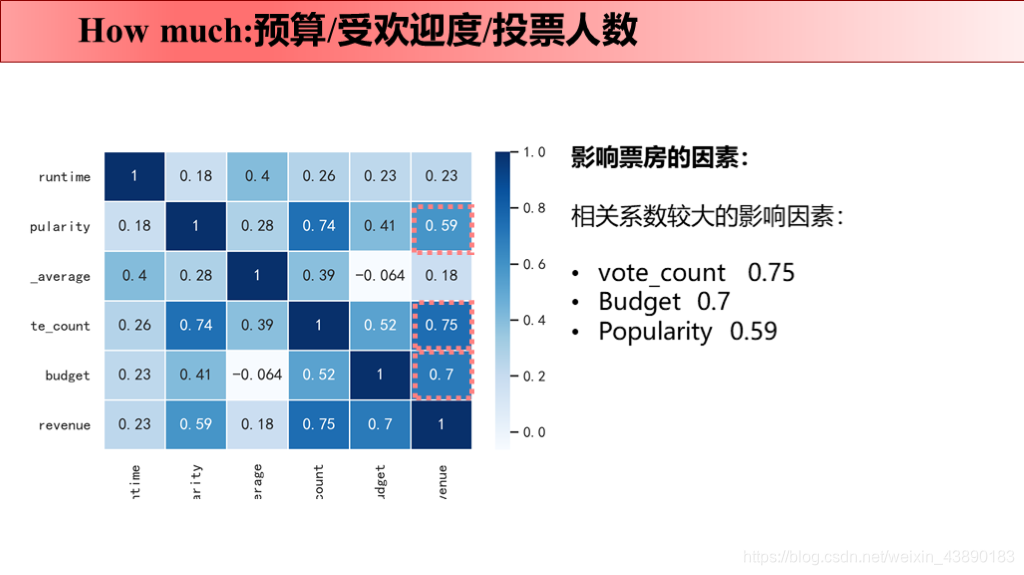
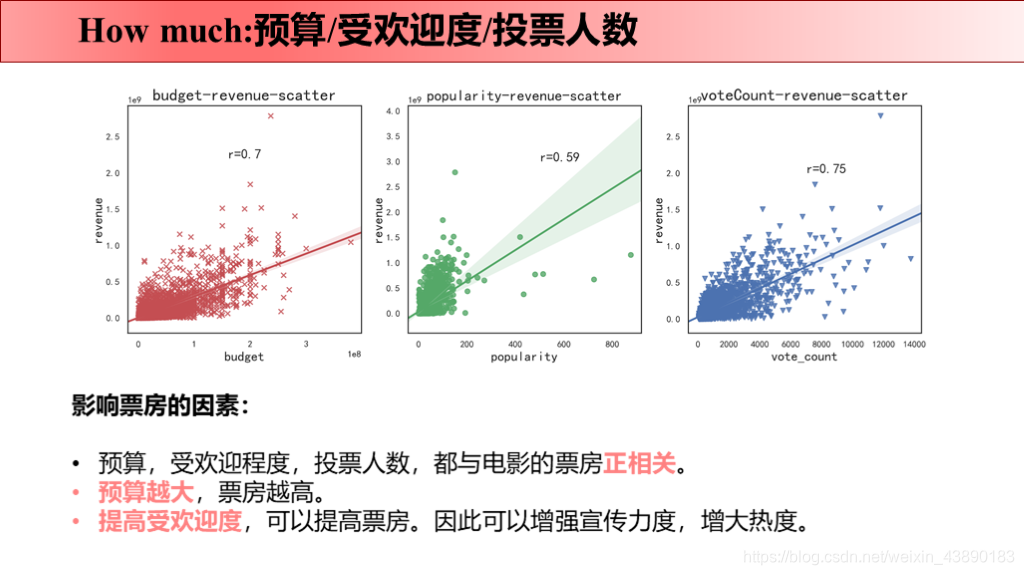
前言 最近刚好Python学完了,所以拿这个项目来练手。要知道好多爬虫数据仅仅凭借Excel和sql是没办法处理的,Python绝对是数据分析的绝佳兵器,数据清洗-数据处理-可视化都可以完成。实践出真知,虽然过程中遇到很多问题,但是学完之后能力就提升啦!这次将自己做的项目完整记录下来并进行分享,以备后续回忆和二次学习。也欢迎感兴趣的同学评论留言,希望我们共同学习,共同进步! 文章目录 1 项目背景 1.1 故事背景 1.2 提出问题 2 项目报告 3 理解数据 3.1 数据来源 3.2 数据字段 4 数据清洗 4.1 导入数据 4.2 缺失值处理 4.2.1 补全release_date 4.2.2 补全runtime 4.3 重复值处理 4.4 日期值处理 4.5 筛选数据 4.6 json数据转换 4.7 数据备份 5 数据分析 5.1 why 5.2 what 5.2.1 电影类型 5.2.1.1 电影类型数量(条形图) 5.2.1.2 电影类型占比(饼图) 5.2.1.3 电影类型变化趋势(折线图) 5.2.1.4 不同电影类型预算/利润(组合图) 5.2.2 电影关键词 5.3 when 5.3.1 电影时长 5.3.2 发行时间 5.4 where 5.5 who 5.5.1 票房分布及票房Top10的导演 5.5.2 评分分布及评分Top10的导演 5.6 how 5.6.1 原创VS改编占比(饼图) 5.6.2 原创VS改编预算/利润率(组合图) 5.7 how much 5.7.1 计算相关系数 5.7.2 票房影响因素散点图 1 项目背景 1.1 故事背景数据分析最重要的就是要讲一个故事喽!故事怎么讲呢?无非就是提出问题-分析问题-解决问题。因为分析出来的数据解决了某个问题,所以,故事说出来才有卖点,别人才会觉得你的数据分析有价值,才愿意为你的数据分析买单。不多说啦,哈哈(⊙o⊙)…回归正题。 我讲故事就是,王思聪想要在海外开拓万达电影的市场,这次他在考虑:怎么拍商业电影才能赚钱?毕竟一些制作成本超过1亿美元的大型电影也会失败 。这个问题对电影业来说比以往任何时候都更加重要。 所以,他就请来了公司的数据分析师来帮他解决问题,给出一些建议,根据数据分析一下商业电影的成功是否存在统一公式?以帮助他更好地进行决策。 1.2 提出问题解决的终极问题是:电影票房的影响因素有哪些? 接下来我们就分不同的维度分析: 观众喜欢什么电影类型?有什么主题关键词? 电影风格随时间是如何变化的? 电影预算高低是否影响票房? 高票房或者高评分的导演有哪些? 电影的发行时间最好选在啥时候? 拍原创电影好还是改编电影好? 2 项目报告国际惯例先来一份数据报告: 本次使用的数据来自于kaggle平台(点击链接下载TMDb 5000 Movie Database)。收录了美国地区1916-2017年近5000部电影的数据,包含预算、导演、票房、电影评分等信息。 3.2 数据字段原始数据集包含2个文件: tmdb_5000_movies:电影基本信息,包含20个变量 tmdb_5000_credits:演职员信息,包含4个变量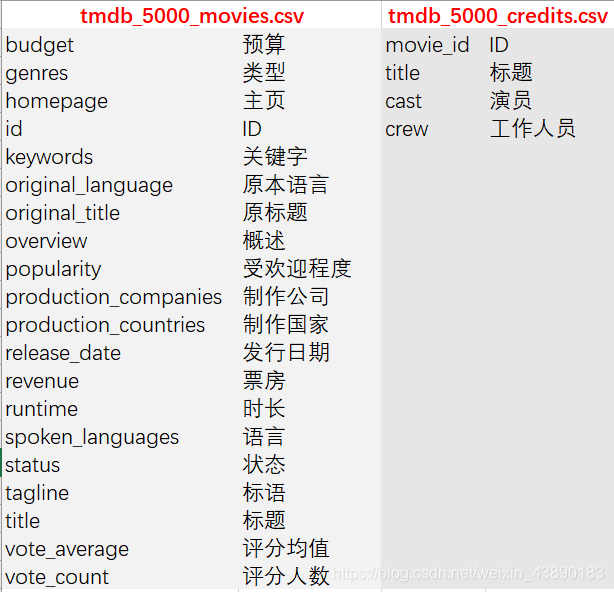 4 数据清洗
4.1 导入数据
4 数据清洗
4.1 导入数据
导入数据包 # 数据导入 import numpy as np import pandas as pd from pandas import DataFrame, Series #可视化显示在界面 %matplotlib inline import matplotlib import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] #用来显示中文 plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 import seaborn as sns sns.set(color_codes=True) # 学习seaborn参考:https://www.jianshu.com/p/c26bc5ccf604 import json import warnings warnings.filterwarnings('ignore') from wordcloud import WordCloud, STOPWORDS movies = pd.read_csv('F:\\tmdb-movie-metadata\\tmdb_5000_movies.csv',encoding = 'utf_8') credits = pd.read_csv('F:\\tmdb-movie-metadata\\tmdb_5000_credits.csv',encoding = 'utf_8') movies.info() #查看信息 credits.info()运行结果: 运行结果: 缺失记录仅3条,采取网上搜索,补全信息。 4.2.1 补全release_date # 查找缺失值记录-release_date df[df.release_date.isnull()]运行结果为: 运行结果: 运行结果:有4803个不重复的id,可以认为没有重复数据。 4.4 日期值处理将release_date列转换为日期类型: #转换日期格式,增加 年份 月份 日 列 #如果日期不符合时间戳限制,则errors ='ignore'将返回原始输入,而不会报错。 #errors='coerce'将强制超出NaT的日期,返回NaT。 df['release_year'] = pd.to_datetime(df.release_date, format = '%Y-%m-%d',errors='coerce').dt.year df['release_month'] = pd.to_datetime(df.release_date).apply(lambda x: x.month) df['release_day'] = pd.to_datetime(df.release_date).apply(lambda x: x.day) df.info()运行结果: 使用数据分析师最喜欢的一个语法: df.describe()运行结果: 查看筛选结果: df.info() |














 续表:
续表: 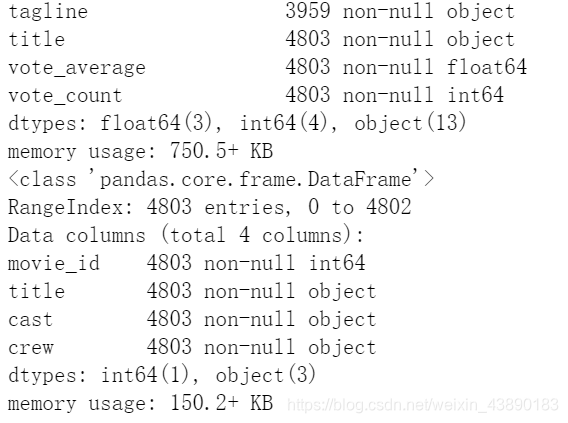 从上述信息可知,共有记录4803条。
从上述信息可知,共有记录4803条。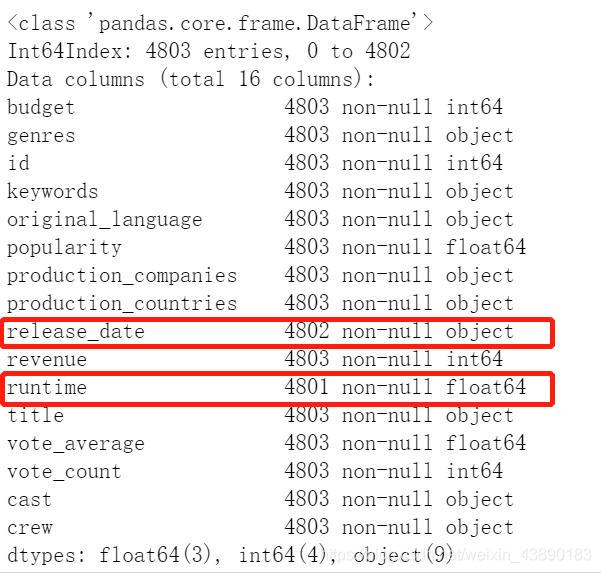 从上可知,发行日期 和 运行时间 两列有数据缺失。 接下来处理缺失值。
从上可知,发行日期 和 运行时间 两列有数据缺失。 接下来处理缺失值。 缺失记录的电影标题为《America Is Still the Place》,日期为’ 2014-06-01 ’
缺失记录的电影标题为《America Is Still the Place》,日期为’ 2014-06-01 ’ 缺失记录的电影runtime分别为94min和 240min
缺失记录的电影runtime分别为94min和 240min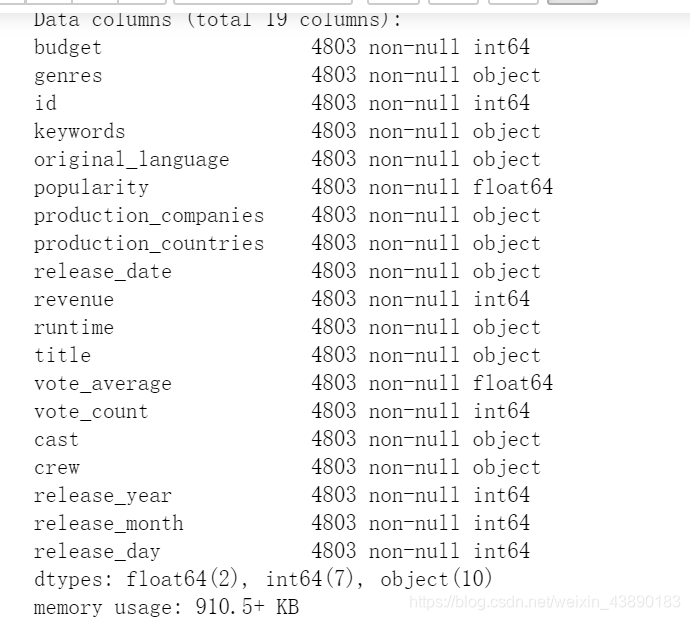 养成处理完数据列就进行查看的习惯~
养成处理完数据列就进行查看的习惯~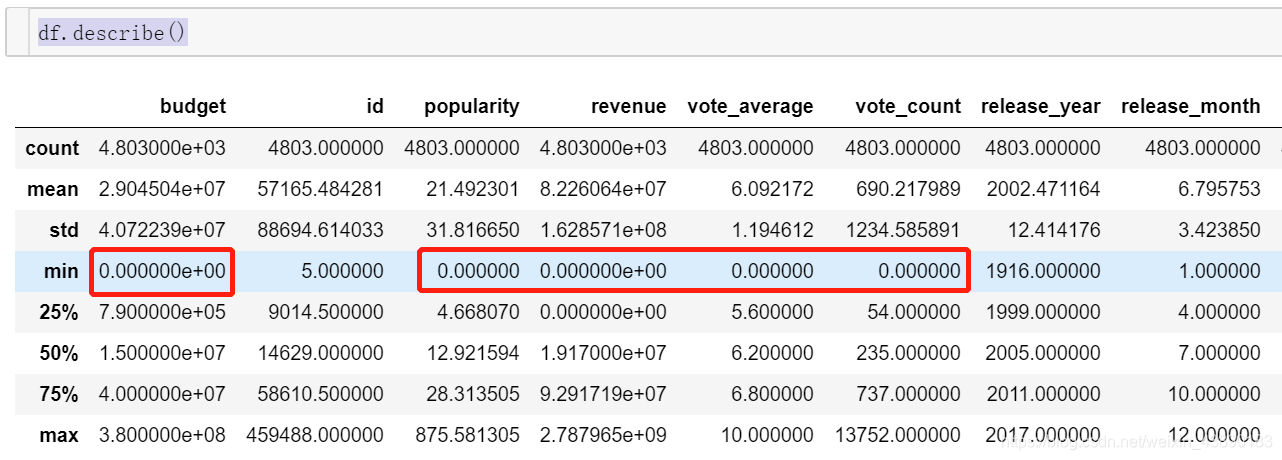
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |