|
文章目录
📚实验目的📚实验平台📚实验内容📚实验步骤🐇KNN介绍🐇并行化🥕在本地编写程序和调试🥕在集群上提交作业并执行
🐇非并行化
欢迎指正~
📚实验目的
机器学习和数据挖掘算法是大数据分析处理领域的重要内容,随着数据规模的不断扩大,设计面向大数据处理的并行化机器学习和数据挖掘算法越来越有必要。通过对并行化数据挖掘算法的实现,掌握并行化处理问题的分析方法和编程思想方法,能够根据实际情况定制并行化的算法解决问题。
📚实验平台
1)操作系统:Linux; 2)Hadoop 版本:3.2.2; 3)JDK 版本:1.8; 4)Java IDE:Eclipse 3.8; 5 ) Spark 版本:3.2.1。
📚实验内容
准备数据集(戳此下载),设计一种数据挖掘算法(聚类、分类、频繁项集挖掘或其他主题)对数据集进行信息提取,要求分别使用并行化和非并行化的方式实现该算法。实验环境可选择 Hadoop 或者 Spark,程序语言可选用 Java、Python、Scala 等。在伪分布式环境下完成并行化算法的编写和测试,并在服务器集群进行提交运行。在单机环境下完成非并行化算法的编写和测试。自行对比并行化和非并行化实现方法的数据挖掘结果,两种结果需完全一致。
📚实验步骤
🐇KNN介绍
k近邻法(k-nearest neighbor,k-NN)是一种基本的分类和回归方法,是监督学习方法里的一种常用方法。k近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例类别,通过多数表决等方式进行预测。k近邻算法用一句通俗的古语来说就是:“物以类聚,人以群分”。如果要看一个实例的类别,那么可以看它附近是什么类别。 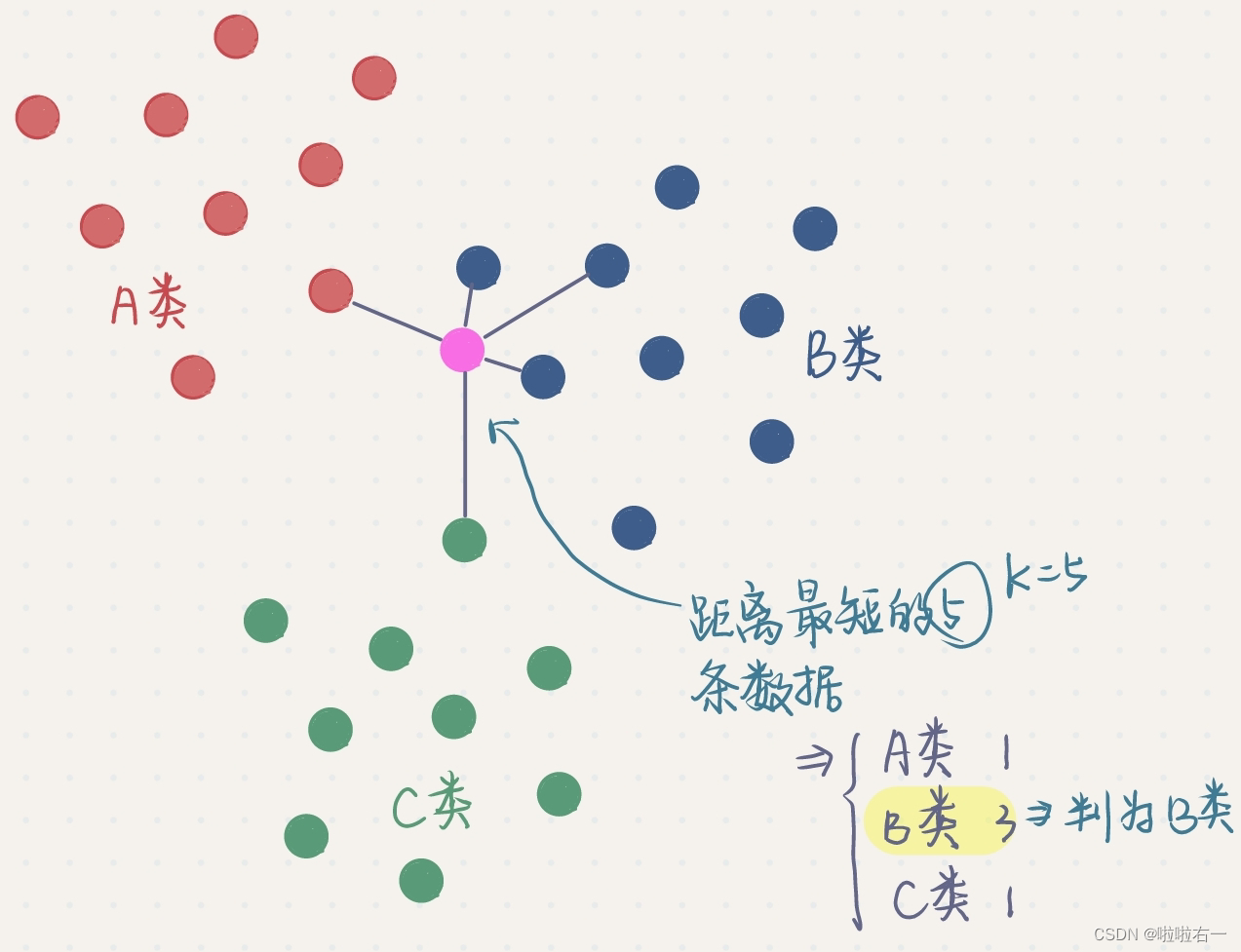 k近邻法三要素:距离度量、 k值的选择和分类决策规则。常用的距离度量是欧氏距离。 k值小时,k近邻模型更复杂,容易发生过拟合;k值大时,k近邻模型更简单,又容易欠拟合。 k近邻法三要素:距离度量、 k值的选择和分类决策规则。常用的距离度量是欧氏距离。 k值小时,k近邻模型更复杂,容易发生过拟合;k值大时,k近邻模型更简单,又容易欠拟合。 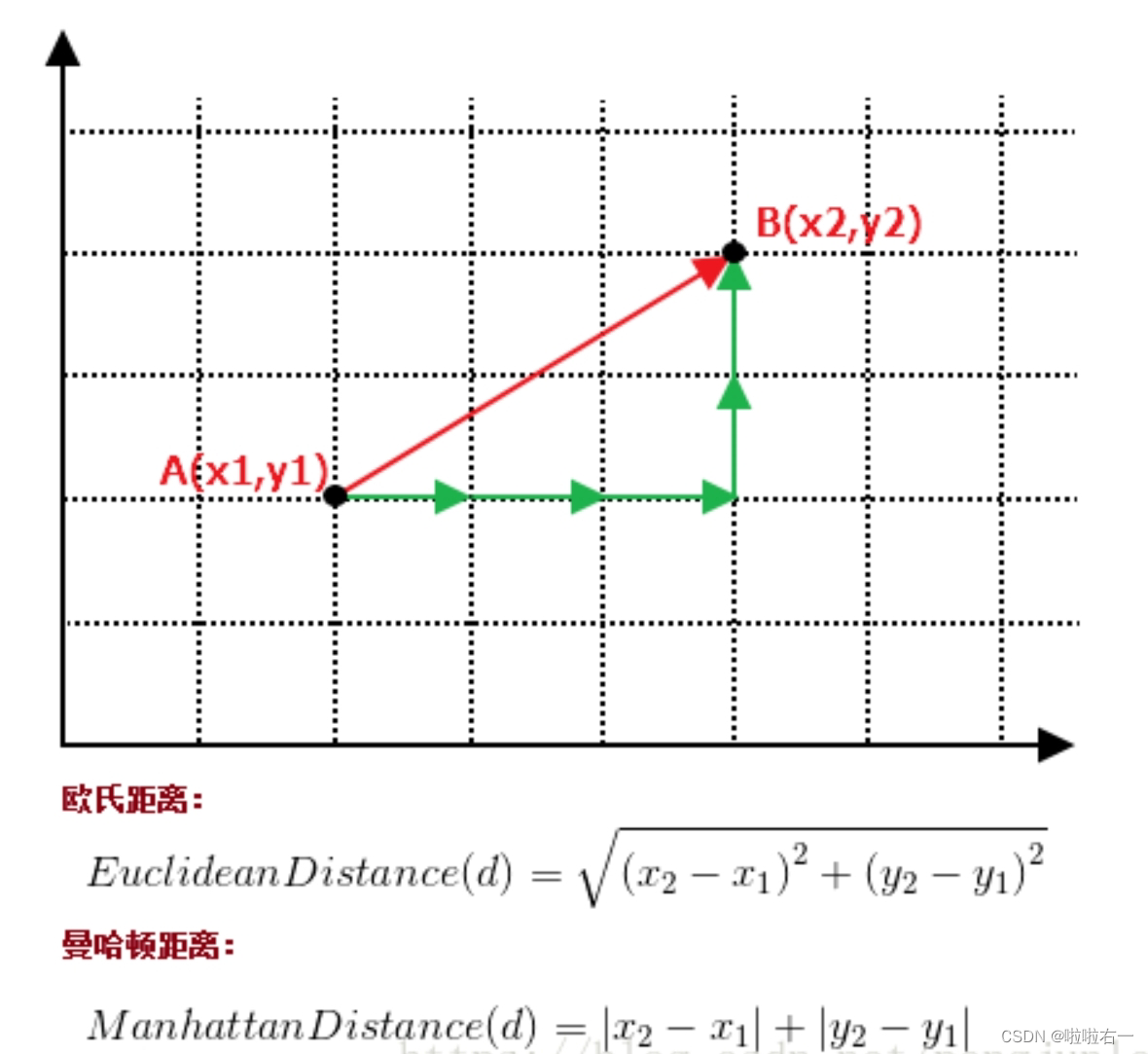 🐇并行化
🥕在本地编写程序和调试
🐇并行化
🥕在本地编写程序和调试
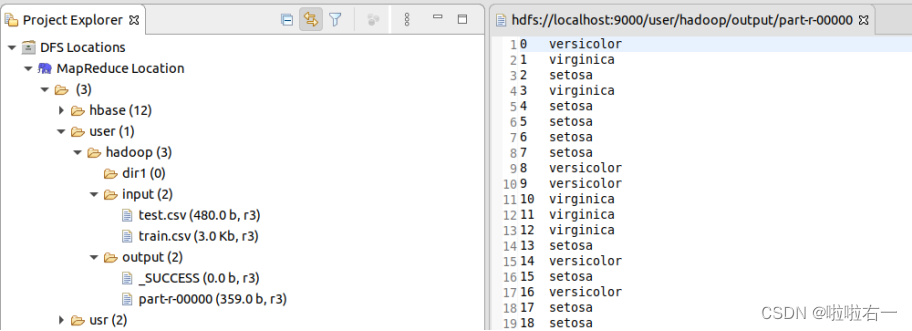
Mapper:计算训练集中每个点与测试集中所有点的欧式距离,并将距离和对应的类标签输出。
输入:,缓存的是test测试集,输入的是train训练集输出: Reducer:将输入数据(一组一组来)按照距离从小到大排序,统计前k个元素的不同类别出现的次数,并输出距离最近的前k个元素的分类结果。
输入:按照距离从小到大排序,统计前k个元素的不同类别出现的次数,找出出现次数最多的类别。输出:
package KNN;
import java.io.BufferedReader;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.nio.file.FileStore;
import java.nio.file.PathMatcher;
import java.nio.file.WatchService;
import java.nio.file.attribute.UserPrincipalLookupService;
import java.nio.file.spi.FileSystemProvider;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
import java.util.HashMap;
import java.util.Set;
import java.util.StringTokenizer;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class KNN
{
//Mapper:计算训练集中每个点与测试集中所有点的欧式距离,并将距离和对应的类标签输出。
public static class TokenizerMapper extends Mapper
{
//List类型的test变量,存储测试集
static List test = new ArrayList ();
@Override
//该函数在Mapper类运行前调用,用于初始化一些参数,读取缓存文件。
protected void setup(Context context) throws IOException,InterruptedException
{
//获取缓存文件的路径数组,这里只有一个缓存文件
Path[] paths = DistributedCache.getLocalCacheFiles(context.getConfiguration());
System.out.println(paths);
//通过BufferedReader类读取缓存文件中的内容
BufferedReader sb = new BufferedReader(new FileReader(paths[0].toUri().getPath()));
String temp = null;
//将每行数据存储到test变量中。
while ((temp = sb.readLine()) != null)
{
test.add(temp);
}
sb.close();
System.out.println("+++++++" + test);
}
//计算两个Double类型数组之间的欧式距离
private double distance(Double[] a, Double[] b)
{
double sum = 0.0;
for (int i = 0; i
//输入:,缓存的是test测试集,输入的是train训练集
//将输入数据按照逗号分割成一个字符串数组train[]
String train[] = value.toString().split(",");
//最后一个元素是样本点所属的类别标签。
String label = train[train.length - 1];
//将train[]中除了最后一个元素以外的每个元素转换成Double类型,并存储到train_point数组中
Double[] train_point = new Double[4];
for (int i = 0; i
//将每个测试点按照逗号分割成一个字符串数组test_poit1[]
String test_poit1[] = test.get(i).toString().split(",");
//将test_poit1[]中的每个元素转换成Double类型,并存储到test_poit数组
Double[] test_poit = new Double[4];
for (int j = 0; j
//定义一个Text类型的变量result,用于存储分类结果。
private Text result = new Text();
//定义变量用于设置k的值。
int k;
//setup()在Reducer开始处理数据之前初始化。
protected void setup(Context context) throws IOException,InterruptedException
{
//context是上下文对象,用于传递参数和获取配置信息。
Configuration conf=context.getConfiguration();
//获取名为"K"的配置参数的值,并将其转化为int类型的值,如果未找到该配置参数,则默认值为1。
k=conf.getInt("K", 1);
}
//将输入数据按照距离从小到大排序,统计前k个元素的不同类别出现的次数,并输出距离最近的前k个元素的分类结果。
public void reduce(IntWritable key, Iterable values,Context context) throws IOException,InterruptedException
{
//输入:
//定义一个TreeMap,用于将输入数据按照距离从小到大排序,其中键为距离,值为该距离所对应的类标签列表。
TreeMap treemap = new TreeMap ();
for (Text val: values)
{
//将输入数据按照"@"进行分割,分别存储距离和类标签列表。
String distance_lable[] = val.toString().split("@");
for (int i = 0; i
//获取 TreeMap 的下一个键
Double key1 = it.next();
//如果 Map 中已经存在当前键所代表的值,则表示该值已经出现过,需要将对应键的值加 1
if (map.containsKey(treemap.get(key1)))
{
//获取当前键所对应的值在 Map 中对应的计数
int temp = map.get(treemap.get(key1));
//将计数加 1,然后更新 Map 对应键所代表的值
map.put(treemap.get(key1), temp + 1);
}
else //如果 Map 中不存在当前键所代表的值,则表示该值还没有出现过,需要在 Map 中添加一个新的元素
{
//将当前键所代表的值加入 Map,并设定计数为 1
map.put(treemap.get(key1), 1);
}
//记录已经处理过的元素个数
num++;
if (num > k)
break;
}
//找出前k个数据里出现次数最多的类别
Iterator it1 = map.keySet().iterator();
String label = it1.next();
//并将其对应的值存储在`count`变量中
int count = map.get(label);
while (it1.hasNext())
{//当还有键未被遍历时,执行循环
String now = it1.next();
if (count
Configuration conf = new Configuration();
String[] otherArgs = new String[]
{
"hdfs://localhost:9000/user/hadoop/input/train.csv",
"hdfs://localhost:9000/user/hadoop/output"
};
if (otherArgs.length
FileInputFormat.addInputPath(job1, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job1,new Path(otherArgs[otherArgs.length - 1]));
System.exit(job1.waitForCompletion(true) ? 0 : 1);
}
}
🥕在集群上提交作业并执行
修改缓存路径、输入、输出路径(这里的路径其实不固定,以下是个人使用路径,与终端操作对应)
输入:hdfs://10.102.0.198:9000/user/bigdata_学号/input/train.csv输出:hdfs://10.102.0.198:9000/user/bigdata_学号/output缓存路径:hdfs://10.102.0.198:9000/user/bigdata_学号/input/test.csv 导出export包(这里的具体操作不清楚的可看实验二)  将数据包及导出的jar包上传至集群,终端操作依次如下: scp test.csv bigdata_学号@10.102.0.198:/home/bigdata_学号
scp train.csv bigdata_学号@10.102.0.198:/home/bigdata_学号
scp KNN.jar bigdata_学号@10.102.0.198:/home/bigdata_学号
登录ssh:ssh bigdata_学号@10.102.0.198 建好input文件夹,导入相关文件,并删除原有的output,终端操作依次如下: hdfs dfs -mkdir input
hdfs dfs -put train.csv /user/bigdata_学号/input/
hdfs dfs -put test.csv /user/bigdata_学号/input/
hadoop fs -rm -r output
运行:hadoop jar KNN.jar
最后可在集群查看提交情况 
🐇非并行化
采用python(knn函数自带),并在Anaconda的JupyterLab运行。 
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
import matplotlib as mpl
import matplotlib.pyplot as plt
# header参数指定标题的行,默认为0.如果没有标题,则使用None
data = pd.read_csv('iris_train1.csv',header=0)
data2=pd.read_csv('iris_test1.csv',header=0)
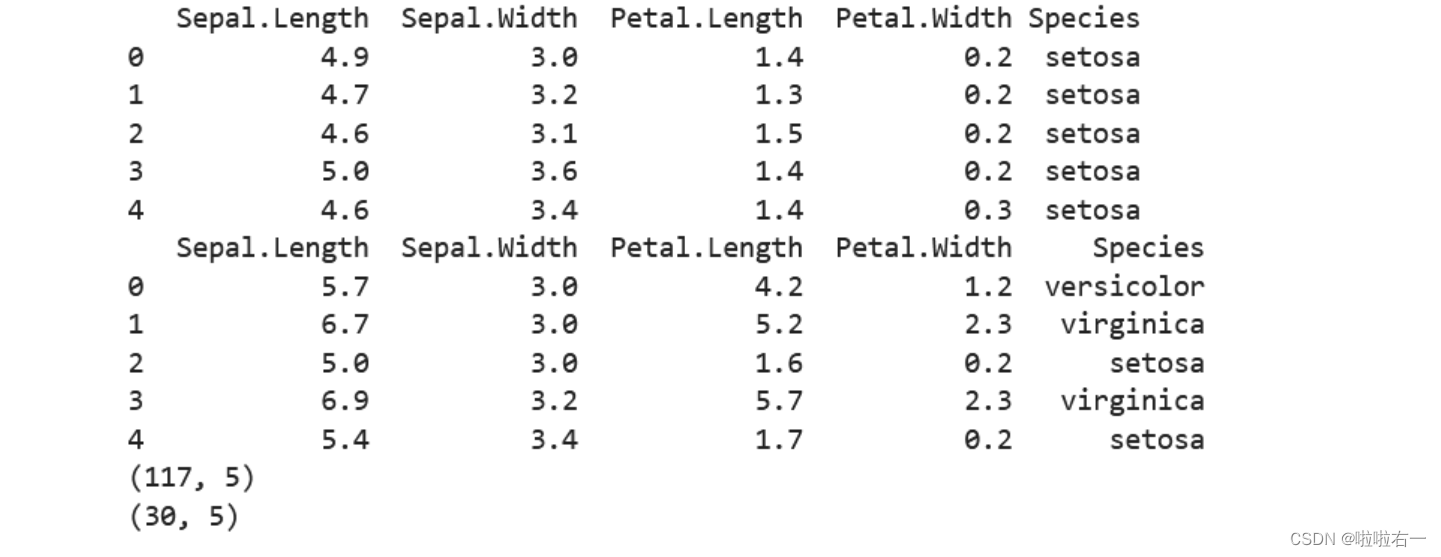
print(data.head())
print(data2.head())
# 将文本数据映射成数值类型
data['Species']=data['Species'].map({"versicolor":0,"setosa":1,"virginica":2})
data2['Species']=data2['Species'].map({"versicolor":0,"setosa":1,"virginica":2})
# print(data.duplicated().any())
data.drop_duplicates(inplace=True)
print(data.shape)
print(data2.shape)

# 提取出每个类中鸢尾花数据
t0=data[data['Species']==0]
t1=data[data['Species']==1]
t2=data[data['Species']==2]
# 打乱每个类别的数据
t0=t0.sample(len(t0),random_state=0)
t1=t1.sample(len(t1),random_state=0)
t2=t2.sample(len(t2),random_state=0)
# 分配训练集和测试集
train_X=pd.concat([t0.iloc[:30,:-1],t1.iloc[:30,:-1],t2.iloc[:30,:-1]],axis=0)
train_y=pd.concat([t0.iloc[:30,-1],t1.iloc[:30,-1],t2.iloc[:30,-1]],axis=0)
df=pd.DataFrame(data2)
test_X=df[["Sepal.Length","Sepal.Width","Petal.Length","Petal.Width"]]
test_y=df['Species']
# 训练与测试
knn=KNeighborsClassifier(3)
knn.fit(train_X,train_y)
result=knn.predict(test_X)
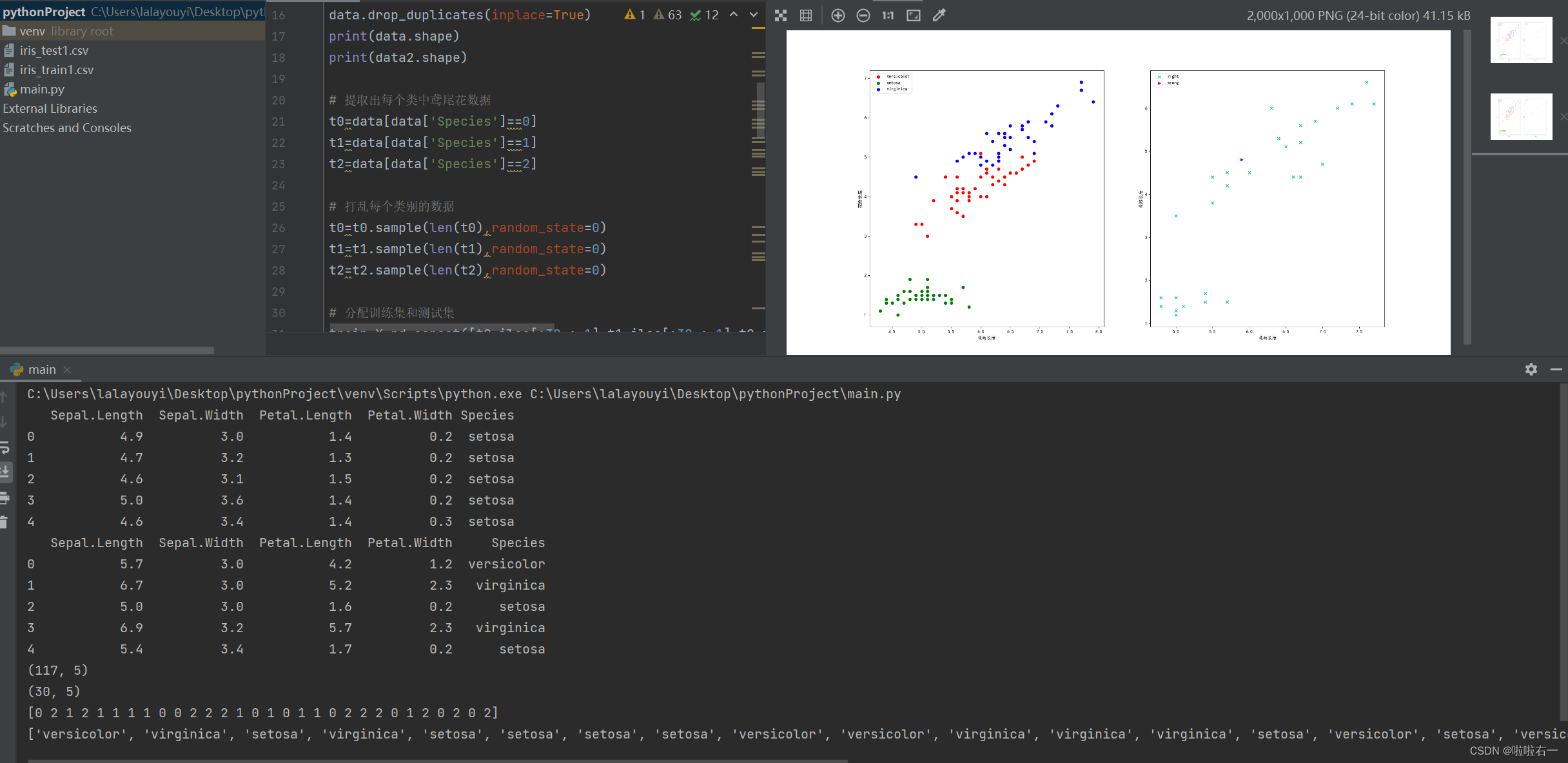
print(result)
final = []
for i in result:
if i == 0:
final.append("versicolor")
elif i == 1:
final.append("setosa")
else:
final.append("virginica")
print(final)

# 可视化
# 设置画布大小
plt.figure(figsize=(20,10))
# 设置字体为黑体,支持中文显示
mpl.rcParams['font.family']='SimHei'
# 设置中文字体,可以正常显示负号
mpl.rcParams['axes.unicode_minus']=False
# 绘制训练集数据
plt.subplot(121)
plt.scatter(x=t0['Sepal.Length'][:40],y=t0['Petal.Length'][:40],color='r',label='versicolor')
plt.scatter(x=t1['Sepal.Length'][:40],y=t1['Petal.Length'][:40],color='g',label='setosa')
plt.scatter(x=t2['Sepal.Length'][:40],y=t2['Petal.Length'][:40],color='b',label='virginica')
plt.xlabel('花萼长度')
plt.ylabel('花瓣长度')
plt.legend(loc='best')
plt.subplot(122)
right = test_X[result == test_y]
wrong = test_X[result != test_y]
plt.scatter(x=right['Sepal.Length'], y=right['Petal.Length'], color='c', label="right", marker="x")
plt.scatter(x=wrong['Sepal.Length'], y=wrong['Petal.Length'], color='m', label="wrong", marker=">")
plt.xlabel('花萼长度')
plt.ylabel('花瓣长度')
plt.legend(loc='best')
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OdClEh1H-1685002353688)(KNN.assets/image-20230525082701583.png)]](https://img-blog.csdnimg.cn/87a246ae36b44951bf8ffe431f07cdf5.png)
Anaconda是在之前上数据导论的时候安装的(好像当时还挺难装 ,具体安装教程之后再补吧(当时没记可恶 。
以下是完整python代码(没装Anaconda问题不大,pycharm或者vs都可以
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
import matplotlib as mpl
import matplotlib.pyplot as plt
# header参数指定标题的行,默认为0.如果没有标题,则使用None
data = pd.read_csv('iris_train1.csv',header=0)
data2=pd.read_csv('iris_test1.csv',header=0)
print(data.head())
print(data2.head())
# 将文本数据映射成数值类型
data['Species']=data['Species'].map({"versicolor":0,"setosa":1,"virginica":2})
data2['Species']=data2['Species'].map({"versicolor":0,"setosa":1,"virginica":2})
# print(data.duplicated().any())
data.drop_duplicates(inplace=True)
print(data.shape)
print(data2.shape)
# 提取出每个类中鸢尾花数据
t0=data[data['Species']==0]
t1=data[data['Species']==1]
t2=data[data['Species']==2]
# 打乱每个类别的数据
t0=t0.sample(len(t0),random_state=0)
t1=t1.sample(len(t1),random_state=0)
t2=t2.sample(len(t2),random_state=0)
# 分配训练集和测试集
train_X=pd.concat([t0.iloc[:30,:-1],t1.iloc[:30,:-1],t2.iloc[:30,:-1]],axis=0)
train_y=pd.concat([t0.iloc[:30,-1],t1.iloc[:30,-1],t2.iloc[:30,-1]],axis=0)
df=pd.DataFrame(data2)
test_X=df[["Sepal.Length","Sepal.Width","Petal.Length","Petal.Width"]]
test_y=df['Species']
# 训练与测试
knn=KNeighborsClassifier(3)
knn.fit(train_X,train_y)
result=knn.predict(test_X)
print(result)
final = []
for i in result:
if i == 0:
final.append("versicolor")
elif i == 1:
final.append("setosa")
else:
final.append("virginica")
print(final)
# 可视化
# 设置画布大小
plt.figure(figsize=(20,10))
# 设置字体为黑体,支持中文显示
mpl.rcParams['font.family']='SimHei'
# 设置中文字体,可以正常显示负号
mpl.rcParams['axes.unicode_minus']=False
# 绘制训练集数据
plt.subplot(121)
plt.scatter(x=t0['Sepal.Length'][:40],y=t0['Petal.Length'][:40],color='r',label='versicolor')
plt.scatter(x=t1['Sepal.Length'][:40],y=t1['Petal.Length'][:40],color='g',label='setosa')
plt.scatter(x=t2['Sepal.Length'][:40],y=t2['Petal.Length'][:40],color='b',label='virginica')
plt.xlabel('花萼长度')
plt.ylabel('花瓣长度')
plt.legend(loc='best')
plt.subplot(122)
right = test_X[result == test_y]
wrong = test_X[result != test_y]
plt.scatter(x=right['Sepal.Length'], y=right['Petal.Length'], color='c', label="right", marker="x")
plt.scatter(x=wrong['Sepal.Length'], y=wrong['Petal.Length'], color='m', label="wrong", marker=">")
plt.xlabel('花萼长度')
plt.ylabel('花瓣长度')
plt.legend(loc='best')
plt.show()
|