基于Python的大数据实验分析(包含:wordCount实验、PageRank实验、关系挖掘实验、k |
您所在的位置:网站首页 › 大数据分析挖掘算法 › 基于Python的大数据实验分析(包含:wordCount实验、PageRank实验、关系挖掘实验、k |
基于Python的大数据实验分析(包含:wordCount实验、PageRank实验、关系挖掘实验、k
|
全套资源下载地址:https://download.csdn.net/download/sheziqiong/86763887 全套资源下载地址:https://download.csdn.net/download/sheziqiong/86763887 实验一 wordCount 算法及其实现 1.1 实验目的 理解 map-reduce 算法思想与流程;应用 map-reduce 思想解决 wordCount 问题;可选)掌握并应用 combine 与 shuffle 过程。 1.2 实验内容提供 9 个预处理过的源文件(source01-09)模拟 9 个分布式节点,每个源文件中包含一百万个由英文、数字和字符(不包括逗号)构成的单词,单词由逗号与换行符分割。 要求应用 map-reduce 思想,模拟 9 个 map 节点与 3 个 reduce 节点实现 wordCount 功能,输出对应的 map 文件和最终的 reduce 结果文件。由于源文件较大,要求使用多线程来模拟分布式节点。 学有余力的同学可以在 map-reduce 的基础上添加 combine 与 shuffle 过程,并可以计算线程运行时间来考察这些过程对算法整体的影响。 提示:实现 shuffle 过程时应保证每个 reduce 节点的工作量尽量相当,来减少整体运行时间。 1.3 实验过程 1.3.1 编程思路总思路如图 1-1 所示:
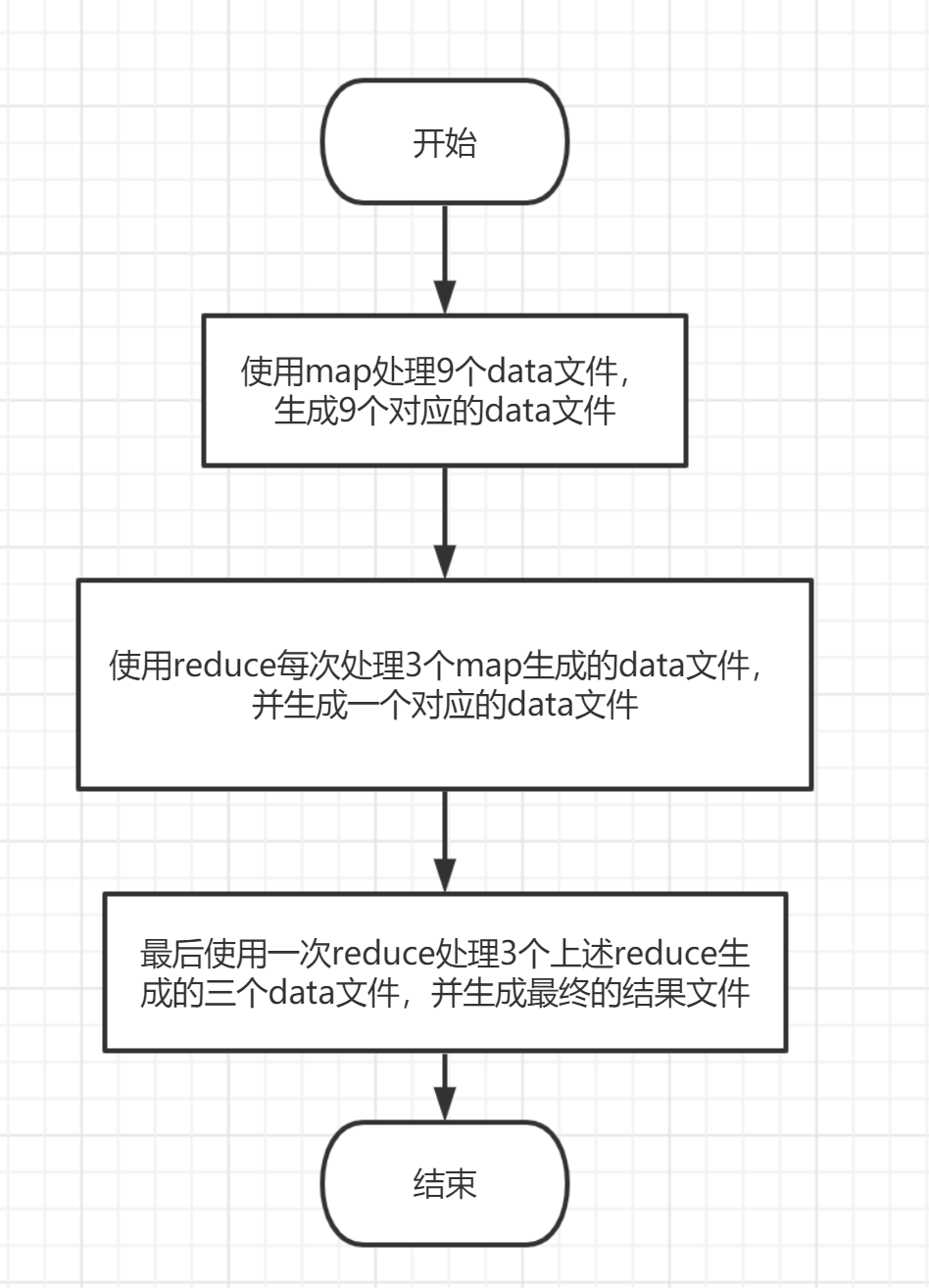
图 1-1:总体逻辑实现 map: 编写面向一个 data 文件的 map 函数,具体实现逻辑就是对出现过的单词进行记录,生成形如“单词,1”的键值对,然后存入另一个 data 文件;主函数里开 9 个线程,同时处理 9 个 data 文件,并生成 9 个 map 处理后的文件。 reduce: 编写面向三个 data 文件的 reduce 函数,具体实现逻辑就是对三个文件里的单词进行出现次数统计,生成形如“单词,出现次数”的键值对,然后存入一个 data 文件;主函数里先开三个线程分别处理 9 个 map 生成的文件,同时会生成 3 个经过 reduce 处理的文件,最后等待三个线程处理结束后,将刚刚 reduce 生成的 3 个文件作为参数再次进行一次 reduce 操作,生成最终的结果文件。 1.3.2 遇到的问题及解决方式 map: 文件处理时的细节:由于我是按照特定的字符切割行来读取的文件流,但是文件的最后一行与其他行相比少了一个换行符,由此会出现一个单词统计的错误,解决方案就是在做文件解析之前先将文件里写入一个”\n”,保证所有行之间的一致性,这样就能避免此错误;线程的实现:采用的是 threading 包里的 Thread 方法来实现多个线程。 reduce: map 文件处理与 reduce 文件处理的一致性:由于经过 map 处理后的文件键值对的第二项均为 1,reduce 处理后的文件键值对的第二项为单词出现次数,原 reduce 函数实现时记录单词出现次数的方式肯定不能再用了,改为加上键值对第二项的数值这一逻辑后即解决了问题;线程等待的实现:使用 join()方法实现主函数的阻塞,在三个线程结束之后才开始最后结果文件的生成。 1.3.3 实验测试与结果分析 经过 map 处理后生成的 data 文件如下图 1-2,图 1-3 所示:
图 1-2 map 处理后生成的文件
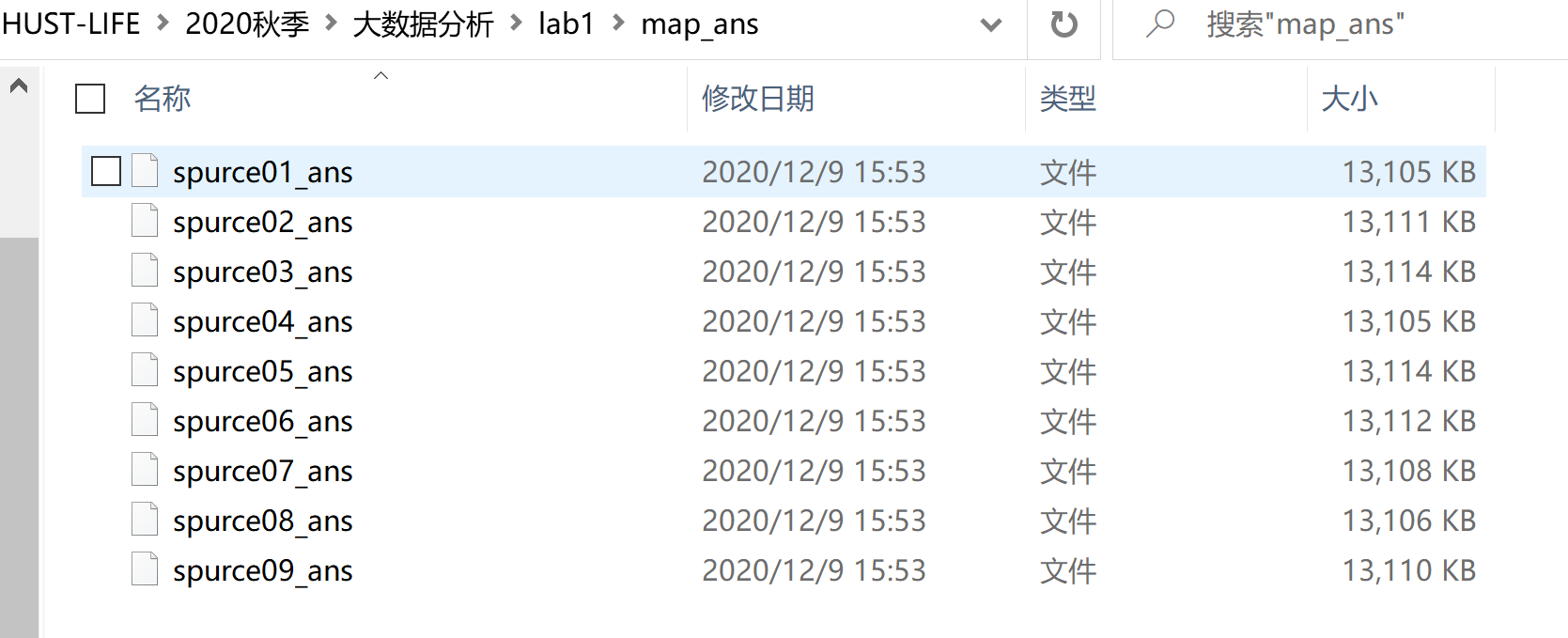
图 1-3:spurce01_ans 文件部分内容 经过 reduce 处理后生成的文件如下图 1-4,1-5 所示:
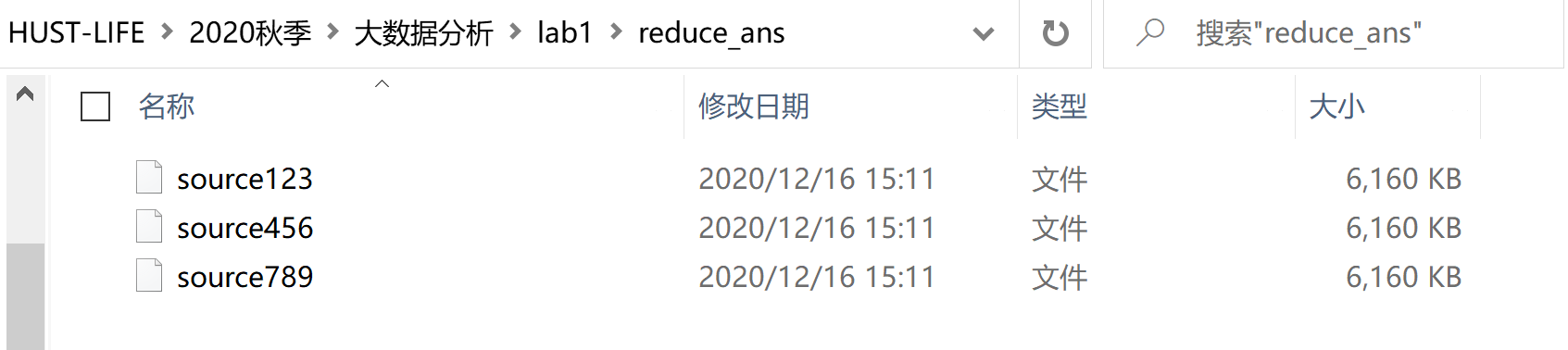
图 1-4:reduce 处理后生成的文件
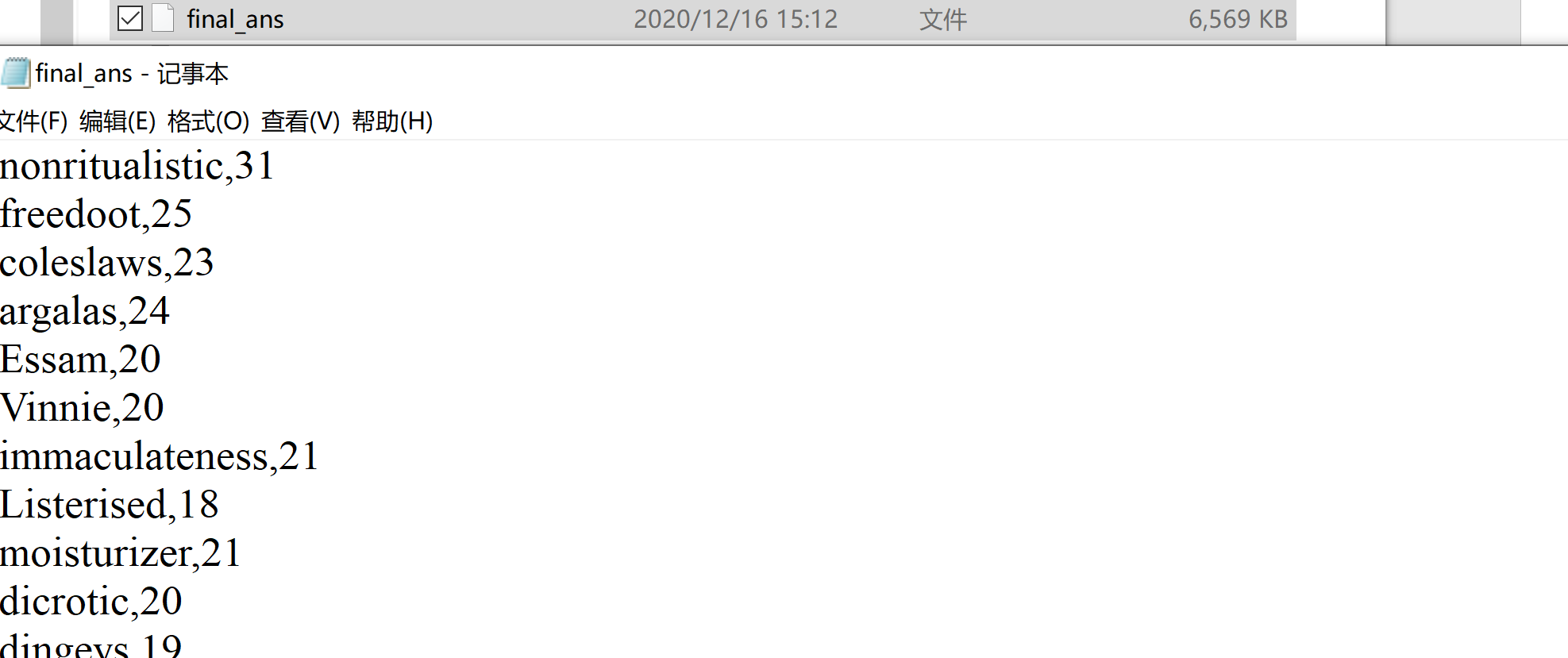
图 1-5:source123 文件部分内容 将三个 reduce 处理后生成的文件再进行一次 reduce 处理后生成的最终结果文件,如下图 1-6 所示:
图 1-6:final_ans 文件部分内容 1.4 实验总结通过实验一更好的理解了 mapreduce 的核心思想,也是一次对于线程操作的实践。 实验二 PageRank 算法及其实现 2.1 实验目的 学习 pagerank 算法并熟悉其推导过程;实现 pagerank 算法;(可选进阶版)理解阻尼系数的作用;将 pagerank 算法运用于实际,并对结果进行分析。 2.2 实验内容提供的数据集包含邮件内容(emails.csv),人名与 id 映射(persons.csv),别名信息(aliases.csv),emails 文件中只考虑 MetadataTo 和 MetadataFrom 两列,分别表示收件人和寄件人姓名,但这些姓名包含许多别名,思考如何对邮件中人名进行统一并映射到唯一 id?(提供预处理代码 preprocess.py 以供参考)。 完成这些后,即可由寄件人和收件人为节点构造有向图,不考虑重复边,编写 pagerank 算法的代码,根据每个节点的入度计算其 pagerank 值,迭代直到误差小于 10-8 实验进阶版考虑加入 teleport β,用以对概率转移矩阵进行修正,解决 dead ends 和 spider trap 的问题。 输出人名 id 及其对应的 pagerank 值。 2.3 实验过程 2.3.1 编程思路 对 CSV 文件进行解析,生成一个阿拉伯数字到节点的映射,一个边集用来表示节点的关联关系;通过边集与映射关系生成一个转移矩阵;通过计算公式进行迭代计算,当误差小于 0.00000001 时,迭代结束,公式为:r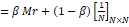 ,β为阻尼系数,值设为 0.85根据映射关系将迭代后的结果转化成一个结果字典,最后对字典按照推荐度从大到小排序,最后写入文件。
2.3.2 遇到的问题及解决方式 ,β为阻尼系数,值设为 0.85根据映射关系将迭代后的结果转化成一个结果字典,最后对字典按照推荐度从大到小排序,最后写入文件。
2.3.2 遇到的问题及解决方式
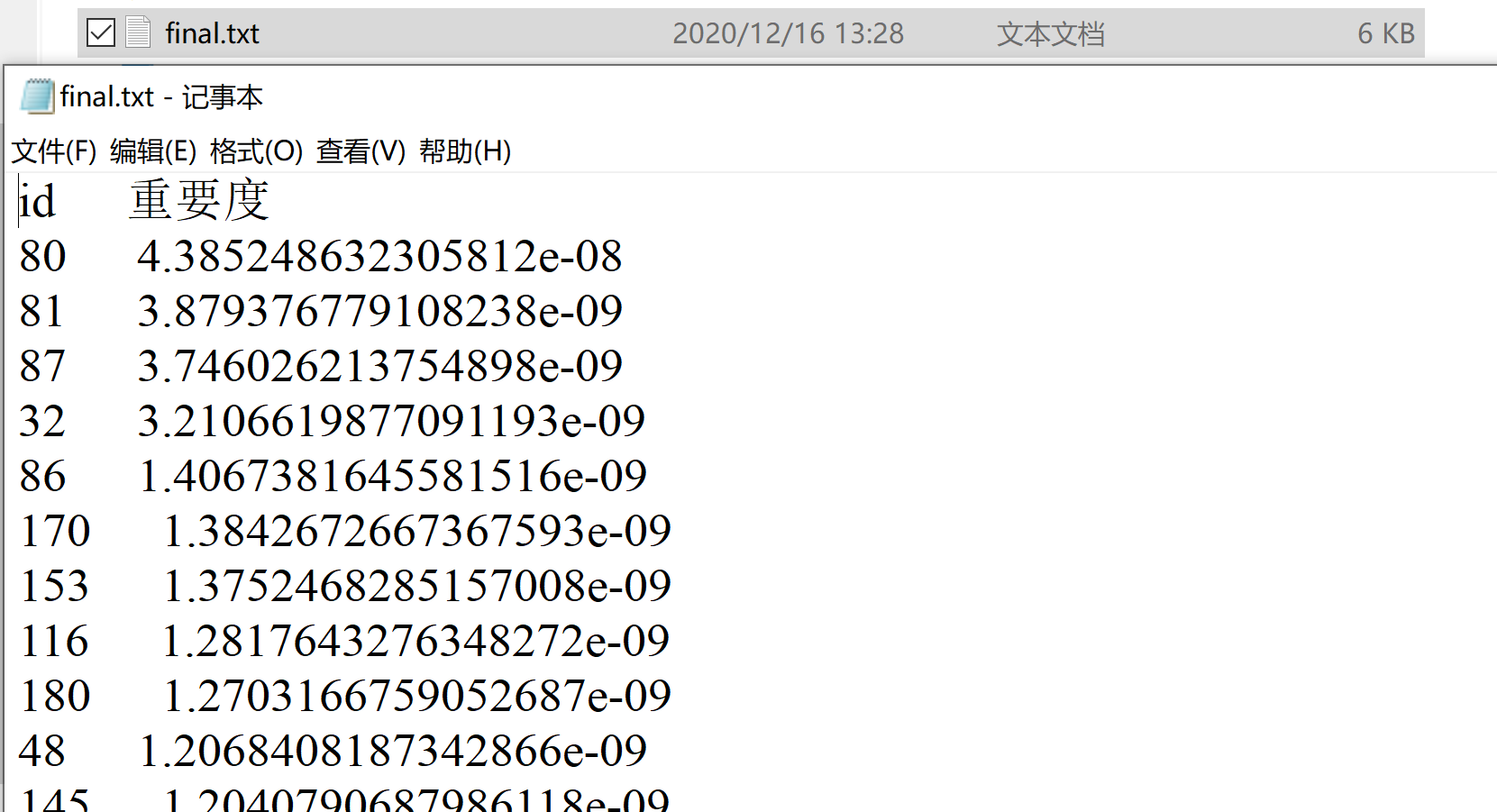
文件处理,即转移矩阵初始化问题:由于给的原始文件中,sender 与 receiver 的 id 是没有规律的,所以就想着通过一个映射关系来简化操作,以便生成原始的转移矩阵,具体的映射方式就是按照节点在 CSV 文件里的出现次序来赋值; 2.3.3 实验测试与结果分析结果文件如下图所示:
图:final.txt 文件部分内容 2.4 实验总结PageRank 实验是最简单的一个实验,只要将初始的转移矩阵构造出来,后面要处理的东西就势如破竹,直接套公式迭代即可,重要的还是拓展了视野,了解了网页排名算法的大致思想。 实验三 关系挖掘实验 3.1 实验内容实验内容 编程实现 Apriori 算法,要求使用给定的数据文件进行实验,获得频繁项集以及关联规则。 实验要求 以 Groceries.csv 作为输入文件 输出 1~3 阶频繁项集与关联规则,各个频繁项的支持度,各个规则的置信度,各阶频繁项集的数量以及关联规则的总数 固定参数以方便检查,频繁项集的最小支持度为 0.005,关联规则的最小置信度为 0.5 3.2 实验过程 3.2.1 编程思路 文件处理:将文件解析成一个列表,列表里的元素也为列表,列表里包含各个单词字符串;编写创建 1 项候选集函数:即将文件解析后的列表解析为单项集;编写扫描数据集函数:该函数根据设置的最小支持度生成频繁项集以及候选项集的支持度字典;编写利用频繁项集构建候选项集函数:该函数即基于 k 阶频繁项集生成 k+1 阶候选项集;编写 apriori 主函数,循环处理三次生成 1,2,3 阶频繁项集,函数逻辑如下图 3-1 所示:
图 3-1:apriori 函数逻辑 利用最小置信度 0.5 来遍历频繁项集生成关联规则。 3.2.2 遇到的问题及解决方式关联规则算法的实现:首先直观的想法就是生成各个映射对来计算置信度,但是这样的工作量比较大并且逻辑容易紊乱,最后我发现如果按照阶的顺序来处理并且将每一阶的频繁项集按序排列后,会形成之前处理过的对是后面即将要处理的对的子集的特殊情形,这样就大大简化了计算的逻辑。 3.2.3 实验测试与结果分析结果文件如图 3-2,3-3,3-4,3-5 所示:
图 3-2:结果文件(1)
图 3-3:结果文件(2)
图 3-4:结果文件(3)
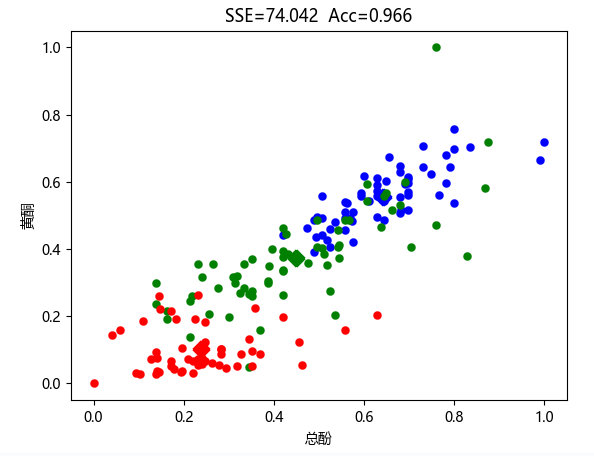
图 3-5:结果文件(4) 结果分析: 由上图可知:1 阶频繁项集:120 个;2 阶频繁项集:605 个;3 阶频繁项集:264 个;关联规则总数:99 个。 3.3 实验总结实验三应该是几个实验里最不好做的一个,主要在于数据处理以及一些关键点的理解上面,好在网上开源资料丰富,最后顺利的实现了要求。 实验四 kmeans 算法及其实现 4.1 实验目的 加深对聚类算法的理解,进一步认识聚类算法的实现;分析 kmeans 流程,探究聚类算法院里;掌握 kmeans 算法核心要点;将 kmeans 算法运用于实际,并掌握其度量好坏方式。 4.2 实验内容提供葡萄酒识别数据集,数据集已经被归一化。同学可以思考数据集为什么被归一化,如果没有被归一化,实验结果是怎么样的,以及为什么这样。 同时葡萄酒数据集中已经按照类别给出了 1、2、3 种葡萄酒数据,在 cvs 文件中的第一列标注了出来,大家可以将聚类好的数据与标的数据做对比。 编写 kmeans 算法,算法的输入是葡萄酒数据集,葡萄酒数据集一共 13 维数据,代表着葡萄酒的 13 维特征,请在欧式距离下对葡萄酒的所有数据进行聚类,聚类的数量 K 值为 3。 在本次实验中,最终评价 kmean 算法的精准度有两种,第一是葡萄酒数据集已经给出的三个聚类,和自己运行的三个聚类做准确度判断。第二个是计算所有数据点到各自质心距离的平方和。请各位同学在实验中计算出这两个值。 实验进阶部分:在聚类之后,任选两个维度,以三种不同的颜色对自己聚类的结果进行标注,最终以二维平面中点图的形式来展示三个质心和所有的样本点。效果展示图可如图 1 所示。
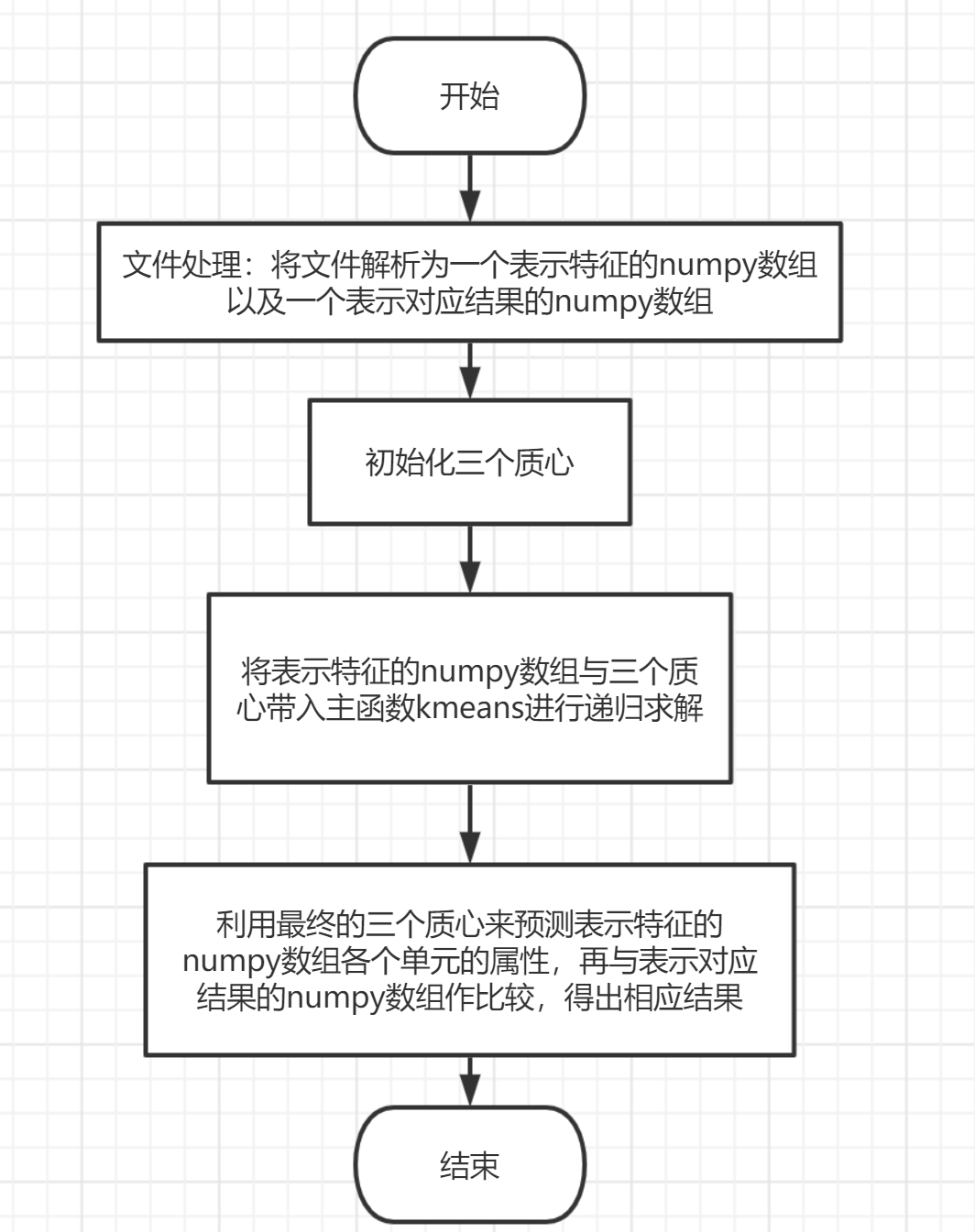
图 1 葡萄酒数据集在黄酮和总酚维度下聚类图像(SSE 为距离平方和,Acc 为准确率) 4.3 实验过程 4.3.1 编程思路主要逻辑如下图 4-1 所示:
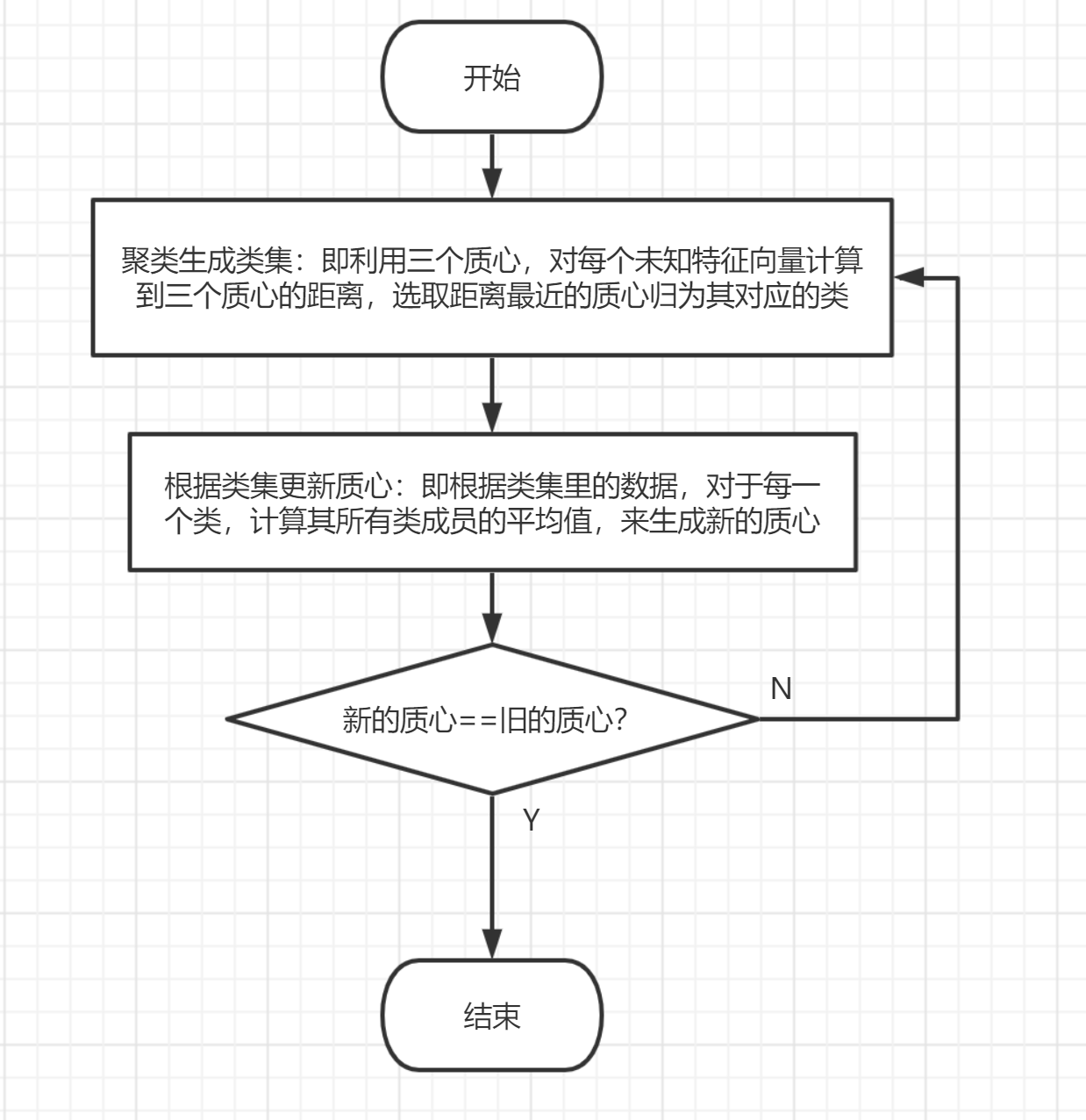
图 4-1:主要逻辑 kmeans 函数逻辑如下图 4-2 所示:
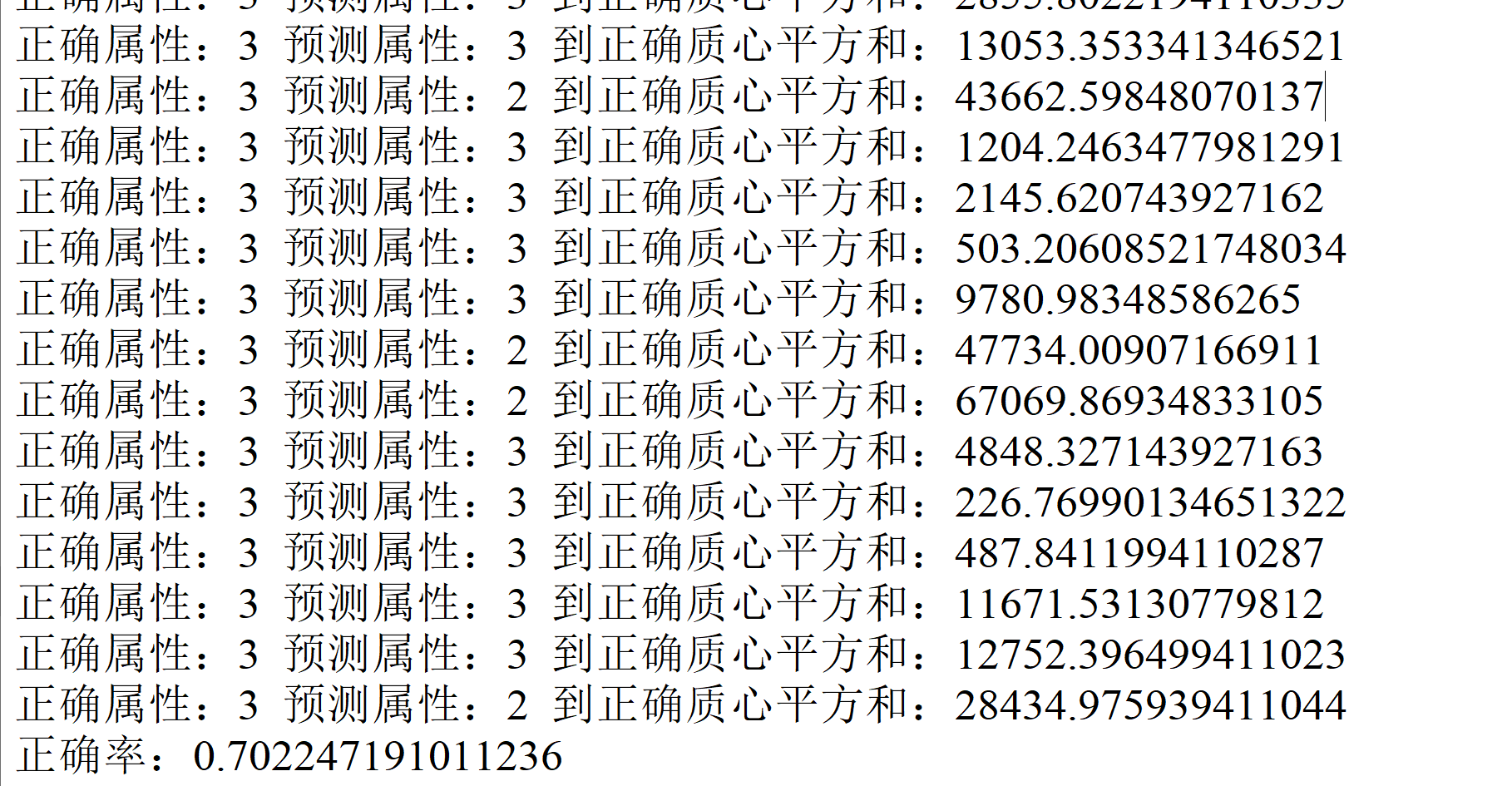
图 4-2:kmeans 函数逻辑 4.3.2 遇到的问题及解决方式 kmeans 函数递归爆栈:由于我是按照递归的方式来进行迭代,所以在跑了 1000 多次之后就出现了栈空间不足的问题,解决方案一就是设置一个迭代次数,在迭代次数超过某个数之后就来到递归边界,然后我发现在不同的迭代次数设置下正确率总会到达一个阈值,所以我觉得应该要换一个思路,于是就换了一个递归边界的方式。原来我使用的递归边界是类集里同样的类到质心的距离平方和不变,可能是精确度的问题或者是编码中的 bug 导致一直达不到递归边界。学长告诉我正常迭代 100 多次就能得出结果,所以我将递归边界换成了比较质心更新后与更新前的值,如果相等就直接退出,结果就没遇到这个爆栈的问题,但是正确率不尽人意;聚类后属性的认定:在进行迭代之后虽然分成了三个簇,但是它们的属性都是未知的,于是就按照簇内原属性占比最大的属性的方法来定义该簇属性。 4.3.3 实验测试与结果分析结果如图 4-3 所示:
图 4-3:final.txt 文件部分内容 4.4 实验总结Kmeans 算法在之前机器学习课程中已经学习过了,所以再次上手没有觉得有太大障碍。可能是由于写的有点仓促以及 python 中一些数值转化时的精度影响,最后的正确率只有百分之七十多,不是很理想。 五、实验五 推荐系统算法及其实现 5.1 实验目的 了解推荐系统的多种推荐算法并理解其原理。实现 User-User 的协同过滤算法并对用户进行推荐。实现基于内容的推荐算法并对用户进行推荐。对两个算法进行电影预测评分对比在学有余力的情况下,加入 minihash 算法对效用矩阵进行降维处理 5.2 实验内容给定 MovieLens 数据集,包含电影评分,电影标签等文件,其中电影评分文件分为训练集 train_set 和测试集 test_set 两部分 基础版必做一:基于用户的协同过滤推荐算法 对训练集中的评分数据构造用户-电影效用矩阵,使用 pearson 相似度计算方法计算用户之间的相似度,也即相似度矩阵。对单个用户进行推荐时,找到与其最相似的 k 个用户,用这 k 个用户的评分情况对当前用户的所有未评分电影进行评分预测,选取评分最高的 n 个电影进行推荐。 在测试集中包含 100 条用户-电影评分记录,用于计算推荐算法中预测评分的准确性,对测试集中的每个用户-电影需要计算其预测评分,再和真实评分进行对比,误差计算使用 SSE 误差平方和。 选做部分提示:此算法的进阶版采用 minihash 算法对效用矩阵进行降维处理,从而得到相似度矩阵,注意 minihash 采用 jarcard 方法计算相似度,需要对效用矩阵进行 01 处理,也即将 0.5-2.5 的评分置为 0,3.0-5.0 的评分置为 1。 基础版必做二:基于内容的推荐算法 将数据集 movies.csv 中的电影类别作为特征值,计算这些特征值的 tf-idf 值,得到关于电影与特征值的 n(电影个数)*m(特征值个数)的 tf-idf 特征矩阵。根据得到的 tf-idf 特征矩阵,用余弦相似度的计算方法,得到电影之间的相似度矩阵。 对某个用户-电影进行预测评分时,获取当前用户的已经完成的所有电影的打分,通过电影相似度矩阵获得已打分电影与当前预测电影的相似度,按照下列方式进行打分计算:
选取相似度大于零的值进行计算,如果已打分电影与当前预测用户-电影相似度大于零,加入计算集合,否则丢弃。(相似度为负数的,强制设置为 0,表示无相关)假设计算集合中一共有 n 个电影,score 为我们预测的计算结果,score’(i)为计算集合中第 i 个电影的分数,sim(i)为第 i 个电影与当前用户-电影的相似度。如果 n 为零,则 score 为该用户所有已打分电影的平均值。 要求能够对指定的 userID 用户进行电影推荐,推荐电影为预测评分排名前 k 的电影。userID 与 k 值可以根据需求做更改。 推荐算法准确值的判断:对给出的测试集中对应的用户-电影进行预测评分,输出每一条预测评分,并与真实评分进行对比,误差计算使用 SSE 误差平方和。 选做部分提示:进阶版采用 minihash 算法对特征矩阵进行降维处理,从而得到相似度矩阵,注意 minihash 采用 jarcard 方法计算相似度,特征矩阵应为 01 矩阵。因此进阶版的特征矩阵选取采用方式为,如果该电影存在某特征值,则特征值为 1,不存在则为 0,从而得到 01 特征矩阵。 选做(进阶)部分: 本次大作业的进阶部分是在基础版本完成的基础上大家可以尝试做的部分。进阶部分的主要内容是使用迷你哈希(MiniHash)算法对协同过滤算法和基于内容推荐算法的相似度计算进行降维。同学可以把迷你哈希的模块作为一种近似度的计算方式。 协同过滤算法和基于内容推荐算法都会涉及到相似度的计算,迷你哈希算法在牺牲一定准确度的情况下对相似度进行计算,其能够有效的降低维数,尤其是对大规模稀疏 01 矩阵。同学们可以使用哈希函数或者随机数映射来计算哈希签名。哈希签名可以计算物品之间的相似度。 最终降维后的维数等于我们定义映射函数的数量,我们设置的映射函数越少,整体计算量就越少,但是准确率就越低。大家可以分析不同映射函数数量下,最终结果的准确率有什么差别。 对基于用户的协同过滤推荐算法和基于内容的推荐算法进行推荐效果对比和分析,选做的完成后再进行一次对比分析。 5.3 实验过程 5.3.1 编程思路基于用户的协同过滤推荐算法 处理训练集中的评分数据,忽略文件中的观看时间这一列,构造用户-电影效用矩阵; 编写 pearson 相似度计算逻辑,主要包括评分向量的构建以及计算公式的实现,评分向量的构建是找出两个 user 电影列表里的相同电影来实现,计算公式为: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sOB5Dovt-1642771363266)(./photo/770768de97c97c9922c0b19aa0ab8979.writebug)] 编写预测评分逻辑,对于特定 user,找出 user 列表中与其相似度最高的 k 个 user,然后在这 k 个 user 中找出目标电影的评分,计算平均值; 编写测试函数,解析测试文件,将 userId 和 movieId 带入预测评分函数,得出的结果与正确结果进行误差分析,最后统计 SSE 即可。 基于内容推荐 首先要得到 tf-idf 矩阵,创建一个 1925*19 的矩阵,代表一共 19 种电影,一种 1925 个电影。第 j 列的 idf 值,为:电影的总数(1925)/该类下的电影数,第 i 行第 j 列的 tf 值为:1/该第 i 个电影拥有的电影种类数目。 得到 tf-idf 矩阵后可以根据这个矩阵得到相似度矩阵: 首先是根据余弦相似度的计算方法得到电影之间的相似度矩阵,余弦相似度的计算方法为,对任意两行 i,j 运用该公式就可以得到一个相似度矩阵中(i,j)处的值:
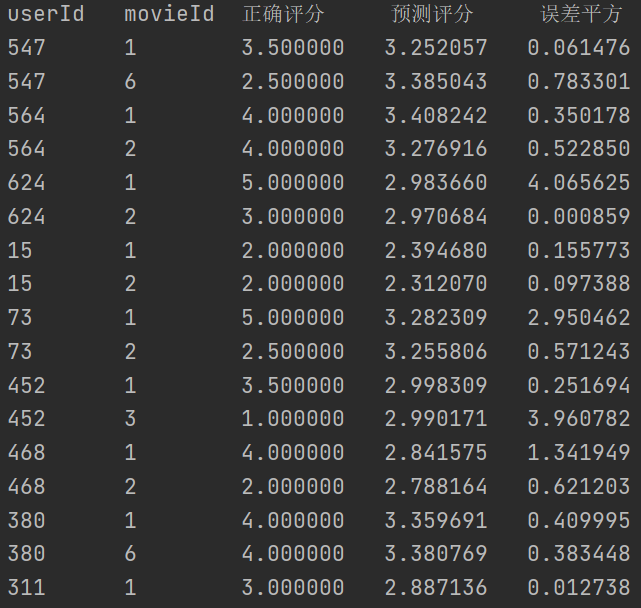
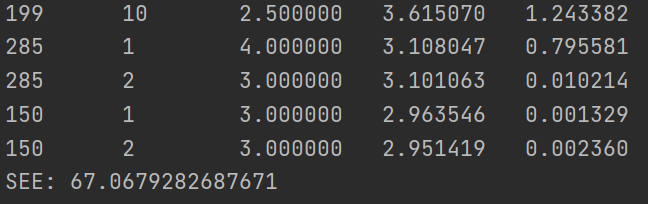
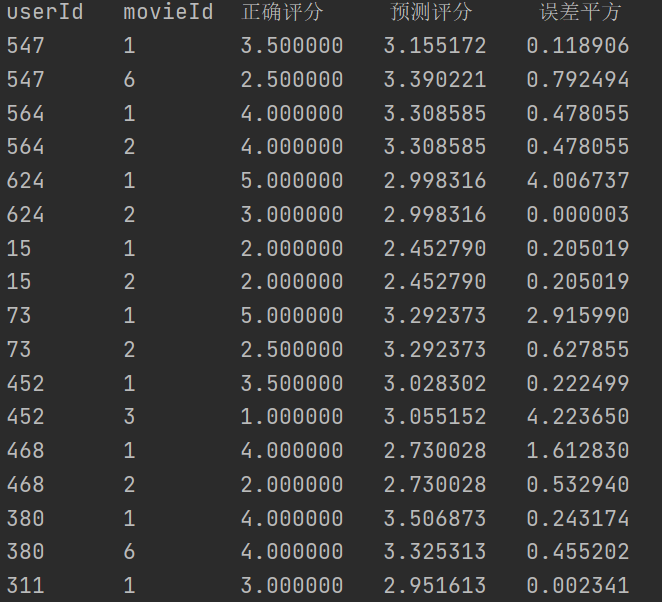
然后是根据 minhash 计算电影之间的相似度矩阵。首先得到 01 矩阵,如果该电影存在某特征值,则特征值为 1,不存在则为 0,从而得到 01 特征矩阵,根据 01 矩阵。为了将维数降到 1925×5,自定义 5 个 hash 函数,这五个 hash 函数可以将行数打乱:h1(x) = (x+1)mod19, h2(x) = (2x+1)mod19, h3(x) = (3x+1)mod19, h4(x) = (4x+1)mod19, h5(x) = (5x+1)mod19。根据 hash 函数得到签名矩阵,该签名矩阵的维数是 1925*5,1925 行中任意两行 i,j 之间进行 jarcard 操作,得到相似度矩阵中(i,j)处的值,遍历该 1925 行,得到相似度矩阵的所有值。 得到相似度矩阵(余弦相似度或 minhash)后,要预测某 movieId 的分数,先得到用户已打分的电影 Id,得到与 movieId 的相似度,根据任务书中的 score 计算方法,得到该 movieId 的预测分数。 最后打印不同 userId 的 movieId 的预测分数,将预测分数与真实分数求出 SSE。 5.3.2 遇到的问题及解决方式 基于用户的协同过滤推荐算法 文件解析问题:给定的训练集中包含 timestamp 这一项,最后认定为无关项,直接在解析文件时忽略掉即可;特殊测试案例问题:当 k 值取得不是很大时,存在某一个测试集里的用户-电影对,与该用户相似度最高的 k 个用户里都没有看过这个电影,所以无法预测其评分,我的处理方式是显式的告知该预测评分缺失,直接不纳入最后的 SSE 统计,当然最后肯定要统计一些可预测的数目;另一种方式就是找到满足所有测试集可预测的最小 k 值,经过不断测试,发现 k 值为 66。 基于内容的推荐算法 最大的问题是理解 tf-idf 的意思,本题中的文本文档比较特殊,是一个电影 Id,而单词是电影的类别。这点是问了助教的。第二个问题是计算相似度矩阵时用时过多,最初是通过遍历所有行得到相似度矩阵中的值的,然后改进了算法,利用得到的 tf-idf 矩阵,先对每一个元素除以该元素所在行的模,得到新的 if-idf 矩阵,将这个矩阵 × 矩阵的转置,正好得到相似度矩阵,通过实验,处理后的 if-idf 矩阵的行 ×if-idf 矩阵转置后的列正好是余弦相似度的计算公式。 5.3.3 实验测试与结果分析 基于用户的协同过滤推荐算法值取 6 时,测试结果文件如下图所示:
图 5-1 k=6 测试结果 值取 20 时,测试结果文件如下图所示:
图 5-2 k=20 测试结果 取 40 时,测试结果文件如下图所示:
图 5-3 k=40 测试结果 取 66 时,测试结果文件如下图所示:
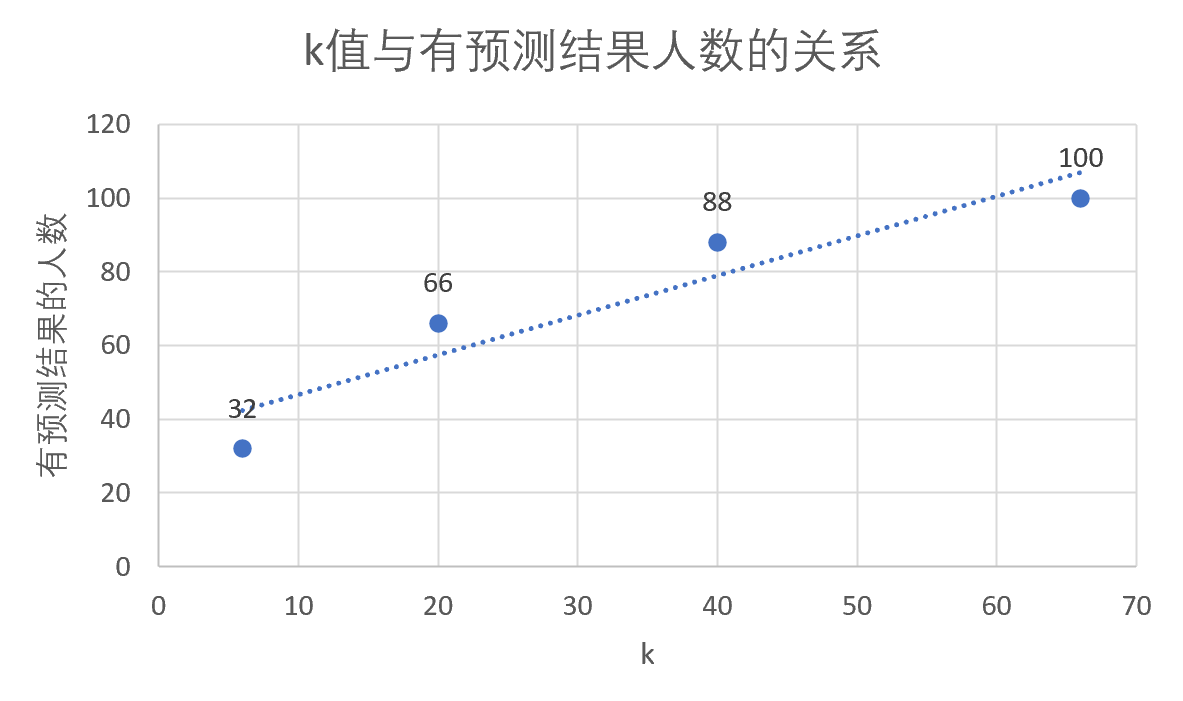
图 5-4 k=66 测试结果 结果分析: 对上述测试的综合分析,k 值与有预测结果人数的关系,如下图所示:
图 5-5 k 值与有预测结果人数的关系 由上图可知,k 值越大,有预测结果的人数越多,人数最大为 100(测试集人数为 100)。从概率上来讲,相似的人越多对于某一电影是否被人看过来讲概率也会更高,经过测试,当 k 达到 66 时,测试集里的所有用户-电影对均有测试结果。 对上述测试的综合分析,k 值与平均误差的关系,如下图所示:
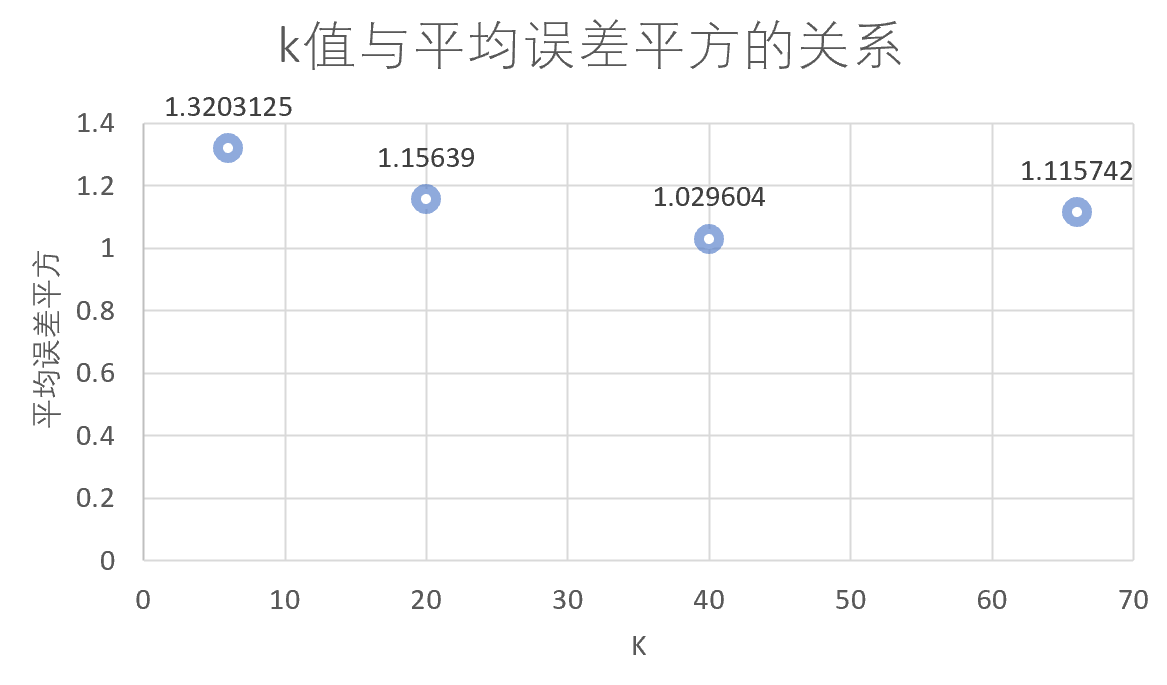
图 5-6 k 值与平均误差的关系 由上图可知,平均误差先减小,再增大;先减小的原因应该是样本具有一定规模后具备了普遍性,k 值取得太小样本量较小,不利于预测;再增大的原因应该是当 k 不断增大后,一些原本跟目标用户相似度并不是那么高的用户也纳入了预测,会对预测产生干扰。 基于内容的推荐算法
图 5-7 余弦相似度实验结果
图 5-8 余弦相似度的 SSE
图 5-9 minhash 的实验结果
图 5-10 minhash 的 SSE 基于 minhash 在本实验中得到的 SSE 的更小,虽然降低了维度,但是 SSE 确实更小了。此外余弦相似度的实验中,不计算 tf-idf 矩阵,直接用 01 矩阵代替 tf-idf 矩阵得到的结果与使用 tf-idf 矩阵得到的结果相近,所以本次实验中使用 tf-idf 矩阵并没有体现出优越性。 两个算法比较分析: 由上述实验结果可知,基于内容的推荐算法要明显优于基于用户的推荐算法。在基于用户的推荐算法中,由于 k 个相似的用户不一定也看过测试集中的电影,所以导致 k 值选取总会偏大,从而受到多个并不是那么相似的用户的干扰。 由以上结果也可以得知,在实际操作中,基于内容的推荐算法往往比基于用户的推荐算法更可靠。 5.4 实验总结基于用户的协同过滤推荐算法 最后完成的是基于用户的协同过滤算法,相对于基于内容来说代码量较少,主要的工作就是在对于算法的理解与结果的分析上。 基于内容的推荐算法 本实验中实现了推荐系统。基于内容的总体思路是通过所有电影的不同类别,通过某种合理的算法得到电影之间的相似度,并得到相似度矩阵。这样在推断用户对电影的喜好时,根据用户已打分电影,可以利用相似度矩阵找出用户对当前推测电影的喜好程度。本实验中对庞杂数据的处理比较困难,需要建立很多字典和列表保存数据,对矩阵的处理也不是简单粗暴的。此外只是根据电影的类别一个特征去预测结果也不是很好,比如 100 个预测数据的 SSE 就达到了 67。 全套资源下载地址:https://download.csdn.net/download/sheziqiong/86763887 全套资源下载地址:https://download.csdn.net/download/sheziqiong/86763887 |






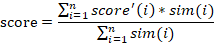
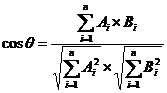




【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |