《大众点评爬虫程序实战:爬取店铺评论信息》 |
您所在的位置:网站首页 › 大众点评等级对应积分 › 《大众点评爬虫程序实战:爬取店铺评论信息》 |
《大众点评爬虫程序实战:爬取店铺评论信息》
|
一、前言
上一章节介绍了如何使用selenium与requests爬取大众点评店铺相关信息,本章将介绍如何爬取指定美食店铺下的评论信息 二、爬取目标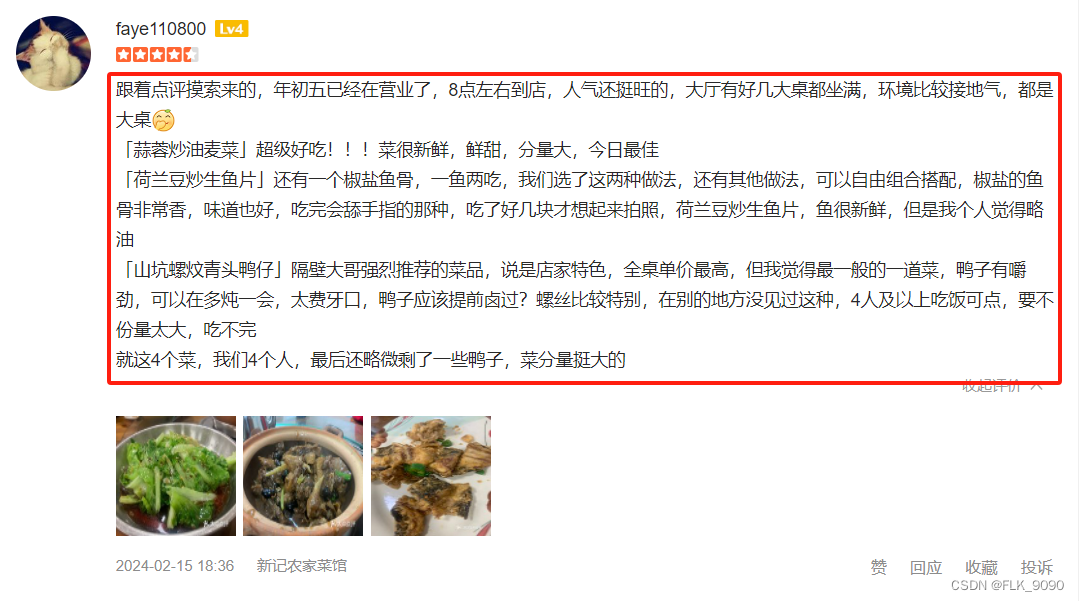 三、准备工作
三、准备工作
登录大众点评后生成的cookies,获取方法上一章节有介绍,不清楚的请自行查阅上一篇文章 四、分析通过上一篇文章获取到的munu.json文件我们知道美食店铺列表的链接为:https://www.dianping.com/{}/ch10,其中{}里面的值为城市的拼音,下面我将以肇庆为例来演示如何爬取店铺评论,因此目标链接为:https://www.dianping.com/zhaoqing/ch10
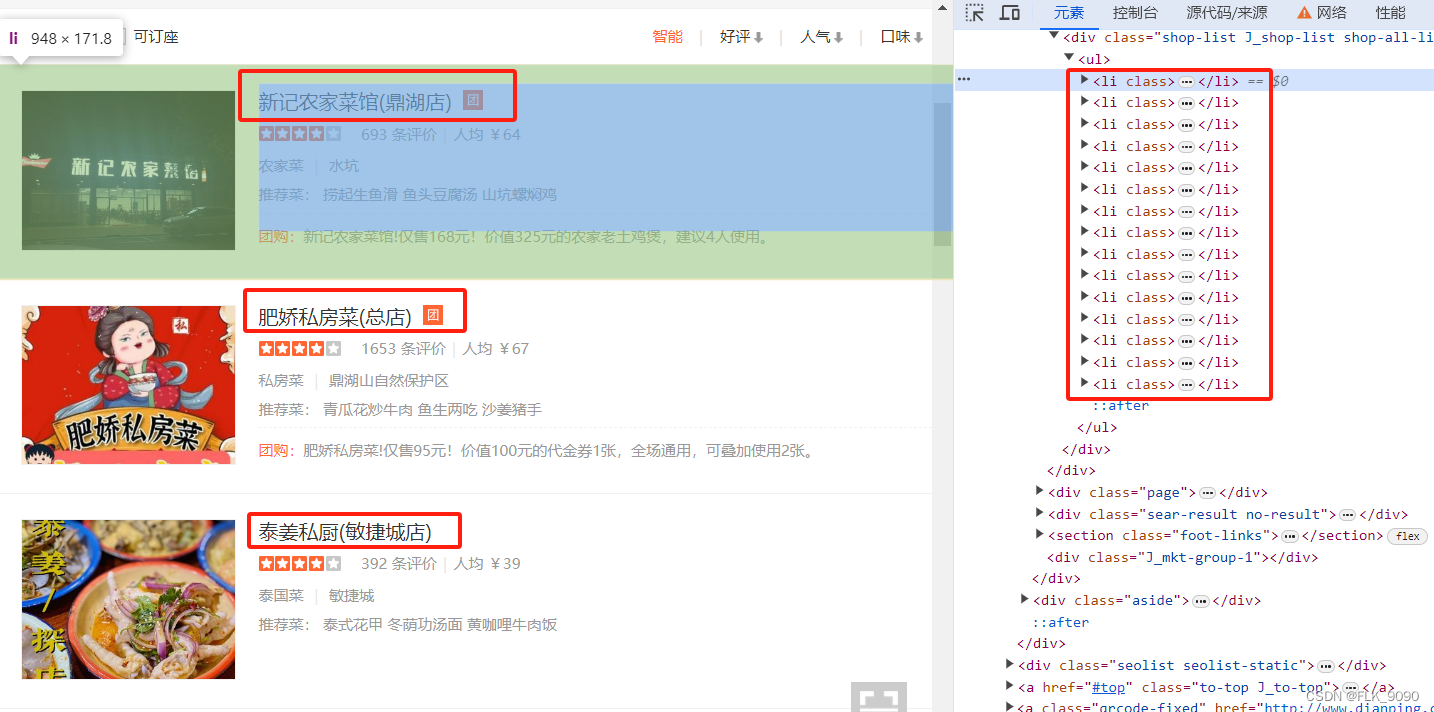
首先我们要先拿到店铺的链接才能顺理成章的拿到该店铺下的评论信息,用过f12观察元素可以清晰的发现店铺的链接就藏在这一个个的li标签下面。 接下来我们观察进入店铺页面点击更多评论时页面上的链接变成:https://www.dianping.com/shop/G2QCvbC34hFSrNIb/review_all 点击第二页链接变成:https://www.dianping.com/shop/G2QCvbC34hFSrNIb/review_all/p2,这时候我们可以猜测,其实p1,p2,p3,……分别会对应第一页,第二页,第三页……。这里我给出结论吧,经过验证我们的猜想是正确的 最后爬取评论信息 四、项目代码(带登录cookies) 获取店铺链接 #!/usr/bin/env python3 # coding:utf-8 import bag from bs4 import BeautifulSoup import re url = 'https://www.dianping.com/zhaoqing/ch10' session = bag.session.create_session() # 创建session管理器 for cookie in bag.Bag.read_json(r'./cookies.json'): # 添加cookies session.cookies.set(cookie['name'], cookie['value']) resp = session.get(url) # 发起请求 resp.encoding = 'utf8' resp.close() # print(resp.text) html = BeautifulSoup(resp.text, 'lxml') # 解析网页数据 soup = html.findAll('div', id='shop-all-list') # 缩小查找范围 # print(soup) pattern = re.compile(r'*?>.*?', self.content): flag.append([i, len(i)]) with open(self.css_path, mode='r', encoding='utf8') as cf: css = cf.read() with open(self.svg_path, mode='r', encoding='utf8') as sf: svg = sf.read() return css, svg, flag '''创建映射关系''' def mapping(self): mid = [] selection = {} for i in self.flag: try: res = re.search(r'{}(.*?);'.format(i[0]), self.css_text).group() mid.append([res[:i[1]], res[i[1]:]]) except AttributeError: continue coordinate = re.compile(r'-(\d{1,5})\..*?-(\d{1,5})\.') for j in mid: for k in re.findall(coordinate, j[1]): selection[j[0]] = k y = re.compile(r'(.*?)', re.S) for i in re.findall(y, self.svg_text): self.words[i[0]] = i[1] self.word_num.append(i[0]) self.word_value.append(i[1]) return selection '''恢复文字''' def recovery(self): for key, value in self.selection.items(): d_value = 50 label, number = key, [int(value[0]) // 14, int(value[1])] x = number[0] y = '' y1 = '' for y_key, w_value in self.words.items(): y1 = y if abs(number[1] - int(y_key)) < d_value: d_value = abs(number[1] - int(y_key)) y = y_key else: continue print(x, label, y1) count = self.word_num.index(y1) + 1 print(count) # print(word_value[count]) # if int(y1) % 8 == 0: if int(y1) - number[1] == 23: self.word[label] = self.word_value[count - 1][x] else: self.word[label] = self.word_value[count][x] data = self.content.replace('', ' ') data = re.sub(r'&.*?;|', '', data) for key, value in self.word.items(): data = data.replace(key, value) print(data.replace(' ', '')) Decode('css', 'dianping.css', 'dianping.svg') 最终还原的结果: 这个不带登录信息的爬取还原过程还是比较复杂的,感兴趣的可以下去自行探究,因为这里无法上传文件,需要拿上面三个文件测试的可以私聊获取 六、总结本章节介绍了两种爬取大众点评美食店铺评论的信息的方法,主要思路通过正向一步步往后推,得出相关页面的结论在写代码去实现 七、声明 本文只做学习交流用,切勿同于非法用途如本文内容侵犯到您的合法权益,请联系删除 |

【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |