一文读懂 |
您所在的位置:网站首页 › 基因组测序与组装有哪些策略 › 一文读懂 |
一文读懂
|
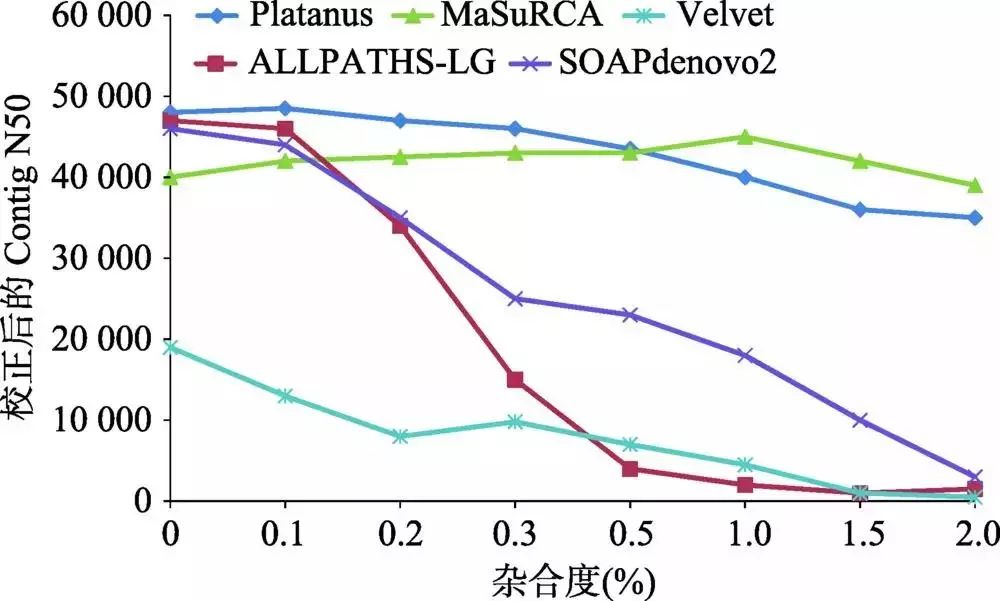
图1 基因组大小和重复序列的相关性 根据重复序列结构、位置及功能方面的差别,可分为散在重复序列(interspersed repeat)、串联重复序列(tandem repeat)和片段重复序列(segmental duplication)。散在重复序列比较均匀地分布在基因组中,包含长散在重复(long interspersed nuclear elements, LINE)、短散在重复(short interspersed nuclear elements, SINE)、类反转录病毒转座子(long terminal repeat- retrotransposon, LTR-RT)和DNA转座子(DNA transposon)。其中,LTR-RT是植物中分布最为广泛的一类转座子,是基因组重复区域的主要成分,如橡胶(Hevea brasiliensis)基因组中71.2%为重复序列,其中LTR-RT占主要部分,它们的大规模复制插入是橡胶基因组明显大于其他近缘物种如木薯(Manihot esculenta)、杨树(Populus trichocarpa)、蓖麻(Ricinus communis)等的主要原因[2;墨西哥蝾螈(Ambystoma mexicanum)基因组的重复序列为65.6%,LTR-RT是主要成分,且几乎都分布在Contig序列的末端,给组装带来巨大挑战[3]。 串联重复是由1~500个碱基的重复单元构成,一般在基因组中重复几十到几百万次,包含简单重复(simple sequence repeat)和卫星DNA。如人类基因组的着丝粒周边区域以及染色体近端短臂含有卫星DNA和串联重复序列;一些遗传调控区域序列如核小体结合单元、甲基化位点等都与串联重复有关;产生茶叶风味的次生代谢产物合成酶基因在基因组上发生拷贝数扩增主要是由串联重复产生[4]。 1.2 杂合度 杂合度对基因组组装产生很大影响,以二倍体基因组为例,通常只组装出一套染色体,对于杂合度高的区域,会将两条染色单体都组装出来,从而造成组装的基因组偏大于实际的基因组大小。对秀丽线虫(Caenorhabditis elegans)模拟不同杂合度的数据进行组装,当杂合度升高时,各组装软件的Contig N50指标都明显下降(图2)[5]。相比于动物基因组而言,植物基因组更加复杂,很多植物因远源杂交、自交不亲和等因素,具有基因组杂合高、倍性高等特征,加上基因组本身比较大,这些都增加了基因组组装的难度。如自交不亲和的茶树(Camellia sinensis)基因组由于种间频繁杂交导致杂合度高达2.8%[4];异源多倍体的陆地棉(Gossypium hirsutum)[6]、油菜(Brassica napus)[7]等物种需要借助二代和三代测序结合进行组装。
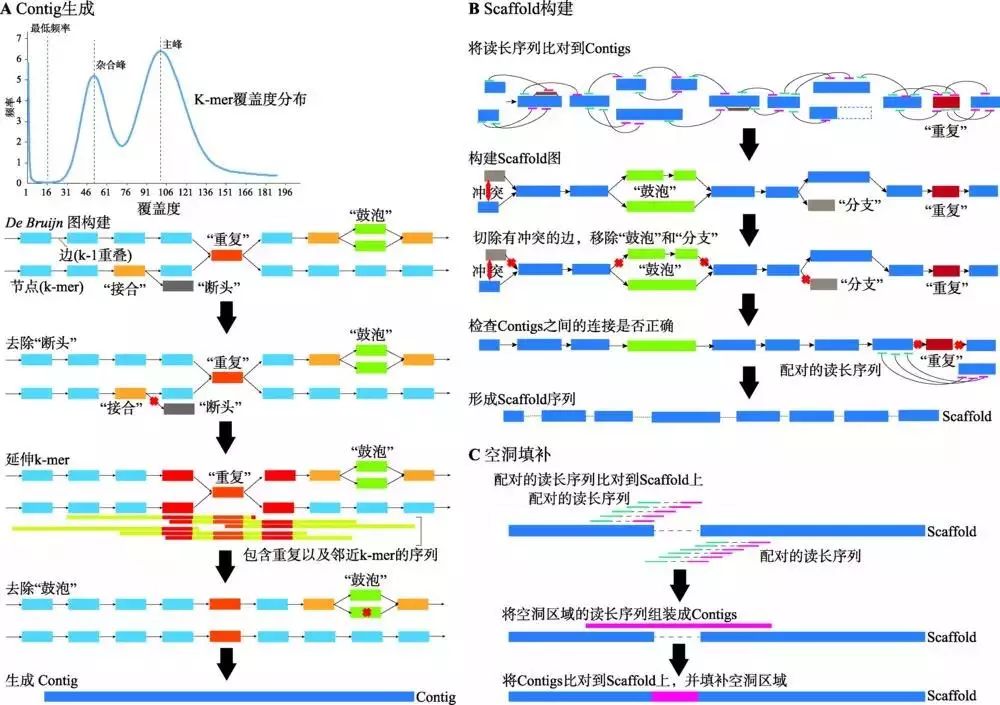
图2 杂合度对不同算法组装指标的影响 1.3 极端GC含量 尽管二代测序(next-generation sequencing, NGS)具有很大优势,但是极端碱基组成一直是造成NGS数据组装具有挑战性的因素之一。在PCR扩增、桥式簇扩增以及测序等NGS数据产生过程中(主要是Illumina测序平台),由于GC偏好性使得基因组中低GC或高GC区域的测序读长(Reads)覆盖度不均一。因为Reads覆盖度是许多组装软件的关键参数,这种极端的GC区域会导致基因组组装碎片化,使其完整性降低[8]。如恶性疟原虫(Plasmodium falciparum)的基因组平均GC含量低于25%,导致许多低GC区域的Reads覆盖度很少甚至没有Reads覆盖[9];脐形紫菜(Porphyra umbilicalis)基因组中GC含量高达65.8%,利用二代测序几乎无法进行组装[10]。 1.4 基因组污染 基因组中存在污染也是造成其复杂性的一个因素。基因组污染一方面可能来源于DNA提取或扩增过程,如DNA提取试剂盒、化学试剂和实验室环境中的杂菌很容易造成污染;另一方面可能来源于物种间相互作用/共生/共栖的生活环境。对于藻类来说,共生微生物较多,如紫菜基因组,即使经过抗生素处理,提取出的DNA中依然有50%的测序数据来自共生微生物和其他真核生物污染[10]。最近,水熊虫(Hypsibius dujardini)基因组就因为污染序列事件成为各方争论的热点,最终Koutsovoulos等[11]根据测序Reads的覆盖度和GC含量不均一性证明了Boothby 等[12]发表的版本组装结果中存在大量的(30%)来自细菌的污染序列。 2.高复杂基因组测序技术解决途径 2.1 针对高复杂基因组测序的实验方法 复杂基因组测序领域一直是基因组学的重要关注点。在第二代高通量测序之前,测序费用高且通量低,对获取高重复序列物种的全基因组序列难度太大或费用太高的物种,科研人员主要尝试提高“有用”基因组区域的比例,如利用杂交退火法提高重复序列较少的基因区域的相对丰度[13],采用甲基化碱基致死大肠杆菌突变体提高甲基化程度较低基因区及其邻近调控区在质粒克隆中的比例[14],或通过外显子芯片杂交获取近缘物种基因区域[15]。 实验手段“简化”复杂基因组是目前一个重要的研究方向,成功应用案例包括构建单倍体品系[16]、染色体分离[17, 18]以及低识别位点限制性内切酶完全酶切[19]等。但以上方法都有其技术局限性:并不是每个物种都可以获得稳定的单倍体品系;染色体分离技术要求染色体完整且各条染色体具有不同长度或标记信息,目标样品较少,而微量样品扩增可能引入偏差;酶切法无法有效分离不同来源的同源染色体。 2.2 现有高通量测序技术的特点 目前,使用最多的高通量测序手段分为两种主要类型:(1) 短读长高通量测序,主要包括Illumina的HiSeq和10X Genomics测序平台;(2) 长读长单分子测序,主要包括PacBio的SMRT平台和Oxford Nanopore Technologies的MinION平台。此外,还包括一系列辅助分子标记测序系,如BioNano的Saphyr光学酶切图谱系统等,可用于辅助复杂基因组的组装,并对组装的准确性进行评估。 从头测序组装(de novo assembly)复杂基因组的关键之一是获得较长的读长序列,以降低重复序列或高相似基因组片段对基因组组装的影响。在第二代高通量测序仪问世之初,Illumina/Solexa读长不足35 bp,基本难以实现对基因组进行有效的组装,对于复杂基因组更是“束手无策”。为了克服这一困难,当时发展起来的酶切“延伸”[20]和局部组装[21]技术对基因组的组装具有明显的促进作用。经过多年发展,Illumina的HiSeq平台目前的常见读长为2×100 bp (Illumina HiSeq 2000)至2×250 bp (Illumina MiSeq,虽然较早期有很大提升,但仍然难以满足复杂基因组组装的需求。尽管Illumina测序平台读长较短,但与长读长技术相比,其序列的准确性具有明显的优势。因此,目前针对复杂基因组组,需要依靠长读长数据与二代Illumina短读长数据相结合的方法来实现,以充分利用两者之间的互补优势。 Pacific Biosciences (PacBio)公司于2010年发布的基于单分子实时技术(single molecule real time, SMRT)的测序仪PacBio RS,目前已经更新到RSII和Sequel版本。PacBio测序反应是在SMRT Cell反应管中进行,每个测序芯片(Cell)都有一个厚度为100 nm的金属小芯片,其上面固定着大约15万个零模波导孔(zero-mode wave guide, ZMW)。ZMW是测序技术的核心[22]。DNA 聚合酶以共价结合的方式锚定在ZMW底部,用来结合单链DNA分子模板。PacBio测序得到的序列是真实的单分子DNA序列,且其读长较长,典型情况下可达到平均20~40 kb,与Illumina的最长250 bp相比具有明显的优势,但测序的准确度相对较低,平均准确度约为80%左右。PacBio产生的数据更适用于复杂基因组的组装,但需要先进行复杂的校正工作,才能达到组装要求。目前,PacBio是用于复杂基因组组装的主流方法。 Oxford Nanopore Technologies Limited公司在2012 年推出第一款基于纳米孔测序技术的测序仪。目前测序平台包括MinION、GridION X5、PromethION和SmidgION。其中SmidgION是迄今为止体积最小的测序设备,可在任何地点与智能手机配套使用。纳米孔测序技术的测序原理是:在纳米孔两边加上一定的电压,在电势的作用下,DNA电泳通过纳米孔,由于4种核苷酸的电离水平和空间结构不同,通过纳米孔时电流强度不同,根据电流强度准确判断碱基种类[23]。纳米孔测序的读长可达数百kb,在解决复杂基因组组装时,与PacBio相比具有更大的优势。 10X Genomics平台本质上是一种改进的二代Illumina测序技术,其核心是一种条码标记(barcoding)技术,根据Barcode信息组装短Reads从而获得跨度为几十kb到几百kb的连锁读长(linked reads),进而将基因组组装划分成数万乃至数百万个局部组装,再将局部组装进一步组装到全基因组。该技术可显著降低复杂度,获得更完整的组装结果,因此也十分适用于复杂基因组的组装。 对于植物等复杂物种基因组的组装项目,现有的二代和三代测序仍然难以准确跨过重复序列区域,而光学图谱技术的出现可以有效克服这一基因组组装难题[24, 25]。基因组光学图谱是指利用荧光标记酶切技术在全基因水平上构建限制性内切酶酶切图谱。BioNano Genomics公司分别在2014年和2017年推出了Irys分析平台和Saphyr分析平台。该平台利用限制性内切酶对DNA分子进行酶切,并利用DNA聚合酶和不同荧光标记的核苷酸合成带有荧光标记的核酸链;再利用微流控装置的毛细管电泳将DNA分子线性化;当DNA分子通过纳米孔的时候进行高分辨率荧光成像,从而生成酶切图谱。利用BioNano技术和三代PacBio/Nanopore相结合,可有效进行基因组从头测序组装,解决复杂基因组的组装难题。 Hi-C (high-throughput chromosome conformation capture)测序是一种以生物细胞核(动物/植物)为研究对象,研究染色质之间相互作用的技术。该技术可有效进行染色体构象捕获,从而获得基因组序列信息及其在基因组中的位置信息[26]。其处理过程:首先利用染色质与甲醛等交联剂进行交联反应;再利用HindⅢ、MboⅠ等限制性内切酶进行酶切反应而获得粘性末端,并加入生物素标记;最后进行解交联反应,利用带有标记的产物进行建库测序。由于Hi-C数据可以准确区分细胞核中的不同染色体,因此对于基因组组装来说,该技术和三代测序技术结合可以高效进行Scaffold乃至染色体级别基因组的构建[27]。 2.3 复杂基因组组装难点与解决方案 高重复和高杂合对于基因组组装的影响,在组装结果中表现为两个相反的特性:由于在组装过程中会将相似的重复序列组装到一起,因此重复序列会导致基因组组装大小的收缩(小于预估的实际基因组大小);对于高杂合来说,染色体组的杂合序列之间存在一定的序列差异,因此在组装的时候会被分别独立组装,从而导致基因组组装大小的扩张(大于预估的实际基因组大小)。因此,对于具有高重复和高杂合成分的基因组来说,对其进行正确组装具有较大的挑战性。 目前常用于基因组组装的两种算法DBG (De brujin Graph)[28]和OLC (overlap-layout-consensus)[29],虽然在原理和速度上具有较大的差别,但其本质都是寻找特定序列的最佳连续匹配,因此在处理高重复和高杂合时,都存在上述的弱点。相对而言,由于DBG算法是通过K-mer的精确匹配进行组装,可以区分细微的序列差别,因此在一定程度上可以区分不同的重复序列;但对于本身具有较大差异的杂合区段来说,DBG会将其组装成独立的序列,因此DBG对于高重复组装具有相对的优势,但对于高杂合表现则不佳。而OLC算法在寻找最佳比对时,允许一定的错配,因此在一定程度上可将杂合区段合并组装,但对于重复序列来说,由于大部分重复序列上的差别小于OLC允许的错配,重复序列可能被错误合并组装在一起,因此OLC算法对于高杂合具有相对的优势。如果将两种算法适当地结合在一起,则可以在一定程度上解决由于高重复和高杂合引起的组装难题。 无论使用哪一种组装方法,高重复与高杂合在本质上是无法被完美解决的,只存在解决这两种问题的相对方法。如前所述,基因组的组装是通过寻找测序数据之间的最佳比对来实现的,但重复序列是高度相似的,杂合区段是存在差异的,因此总会发生将序列错误合并组装,将本应合并的序列错误分离。为了尽可能降低发生错误的可能性,就需要在组装时寻找特异性的最佳比对(unique alignment)。由于比对结果的可信度(得分)与比对的长度成正比,越长的序列,得到的比对越长,得到最佳比对的可能性也越高,因此就要求用于组装的测序数据尽可能长。对于高重复基因组组装来说,最理想的情况就是测序数据将高度重复序列完全包含在读长中间,即形成特异-重复-特异(unique-repeat-unique)序列结构,方能保证重复序列被放置到正确的位置[30];对于高杂合基因组来说情况类似,最理想的情况就是将杂合区段完全包含在读长中间,形成特异-杂合-特异(unique-hetero-unique)序列结构,才能将杂合区段正确识别出来,避免杂合区段被重复组装的问题[5]。 然而,在实际的测序和组装过程中,最理想的情况是不易获得的。在测序平台方面,目前用于基因组组装的测序平台主要有以Illumina HiSeq为代表的二代平台和以PacBio为代表的三代平台。这两种平台具有各自不同的特点,前者测序的精度较高(错误率15%)。由于基因组中STR序列和LTR序列的存在,二代测序平台得到的数据无法将重复序列和高杂合区域跨过,导致组装时出现大量的分支(branch)和环(loop),使组装结果碎片化;而三代测序平台得到的数据虽然有助于跨过这些区域,但因其错误率较高,不仅会引入组装错误,同时在一些极端情况下,由于无法和其他序列正确比对,导致组装无法进行(事实上等同于人为引入了杂合)。此外,尽管长片段测序能够帮助解决一部分高重复和高杂合组装的问题,但并不是全部。根据基因组本身特性的差异,即使在PacBio平台上得到长度分布完全一样的测序数据,能够跨过重复或者杂合区域的比例也仅在30%~60%之间浮动。因此,根据基因组本身的特征对测序策略进行优化是十分必要的过程。 针对于不同测序数据的特点,目前产生了多种不同的组装方法,以利用测序数据的特点来尽可能降低高重复和高杂合对于基因组组装的影响,得到尽可能连续的基因组序列。 在产生较为有效的三代数据组装的算法之前,已经有研究对于仅使用二代数据进行高重复和高杂合基因组组装进行了尝试,结果比传统方法具有十分显著的提升。以Platanus为例,其组装策略分为Contig生成、Scaffold构建和空洞填补(Gapfill) 3个部分(图3)[5]。该软件主要基于DBG算法,并根据DBG算法的特点,重复与杂合成分会在DBG中形成“接合”(Junction)与“鼓泡”(Bubble),而测序的错误会形成“断头”(Tip)。进行组装优化的目的就是将Junction、Bubble和Tip尽可能去除,形成线性图(straight)。在Contig构建时,Platanus采取了3种创新的策略:(1) 通过拟合泊松分布,将低频“拐点”之下的K-mer全部去除,从而有效减少了Tips的数量;(2) 将Reads直接比对定位到Junction节点,通过定位的质量确定Junction的走向,而不是使用K-mer深度,可以解决连续Junction的组合问题;(3) 使用多K-mer延伸策略,从较小的K-mer向较大的K-mer进行延伸,既可以在初始构建DBG时避免杂合造成较低的K-mer深度,又可以有效利用测序数据的长度。通过这一策略,杂合形成的Bubble被有效地鉴定并被分离出来(注意不是去除)。而在Scaffold阶段,Platanus将大片段Mate-pair文库统一定位到Contig和去掉的Bubble上,将带有杂合的序列作为整体考虑,从而有效利用构建形成Scaffold时所包含的Contig两端的连接数。在后续过程中,Platanus同样会识别Scaffold图中可能存在的杂合,将覆盖度较低且内部不含Bubble的Scaffold分支识别为杂合从而去除,带有Bubble的进行保留(默认二倍体基因组中不应存在多重杂合)。最后,在空洞填补阶段,将Reads重新定位到组装成的Scaffold上,将在空洞(Gap)附近的Reads筛选出来,进行局部重新组装,将空洞进行填补。综上所述,Platanus进行高杂合基因组的核心策略是将含有杂合的序列鉴定出来并进行合并去除,相对于传统的方法,可以有效避免在分支处将序列切断,因此可以得到更加连续的组装结果。
图3 Platanus组装策略 A:Contig生成阶段:首先由原始数据生成k-mer分布并拟合泊松分布,确定最低频率、杂合峰和主峰,并去除最低频率下的所有k-mer。然后,依次通过De brujin图构建、去除“断头”、延伸k-mer和去除“鼓泡”4个步骤,生成尽可能连续的Contig序列。 B:Scaffold构建阶段:将原始数据比对到生成的Contig序列上,通过配对关系,首先构建Scaffold图,然后通过切除有冲突的边,移除“鼓泡”和“分支”,生成尽可能连续的Scaffold序列。 C:空洞填补阶段:通过比对获取空洞内及其临近的配对序列,对这些序列进行局部组装,再通过比对将空洞进行填补。根据文献[5]修改绘制。 与Platanus有所不同,另一个组装软件ALLPATHS-LG[31]则更适用于处理高重复基因组。与一般的组装程序不同,ALLPATHS-LG要求在DNA文库构建时同时构建小片段(Fragment)文库和长跨度(Jumping)文库。其中,小片段文库在构建时,要求插入片段长度小于Reads读长两倍的文库,例如插入长度为180 bp的2×100 bp Pair-end文库。在组装时,ALLPATHS-LG会将小片段文库两端的重叠区域结合起来,形成平均长度近似于插入长度的接合片段(end-overlap fragments)。然后,ALLPATHS-LG使用大小K-mer组合的策略,使用较大K-mer将结合片段组装成不含任何分支的独立路径(unipath)片段,通过长跨度文库,将路径片段连接成组装图(assembly graph),并通过覆盖度等信息将包含重复序列的分支“扁平化”(flatten),从而形成包含尽可能少的分支或者环路的线性组装序列。ALLPATHS-LG的组装方法具有以下优势:(1) 基于180 bp的3′末端对接片段,使用较大的K-mer (默认为K=96)进行初始组装,可以有效地避免重复序列区域产生过多的分支;(2) 在组装前,使用24-mer进行测序数据的矫正,可以有效降低由于测序错误或者低频SNP造成的复杂度;(3) 在处理长跨度文库(包括Mate-pair文库和BAC-end文库)时,首先进行嵌合和非环化Reads的检查,消除构建Scaffold时的负面影响;(4) 对于由PCR Bias或者极端GC造成的低覆盖度( |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |