使用TensorFlow构建神经网络:使用人工神经网络进行回归分析 |
您所在的位置:网站首页 › 基于回归分析 › 使用TensorFlow构建神经网络:使用人工神经网络进行回归分析 |
使用TensorFlow构建神经网络:使用人工神经网络进行回归分析
|
使用人工神经网络 (ANN) 的回归分析是一种统计技术,用于根据一个或多个自变量预测因变量的值。人工神经网络在数据集上进行训练,该数据集包括一组观测值的输入和输出值,可以处理非线性关系和大量数据。但是,它们可能比其他回归模型更难解释,并且可能需要更多的数据和计算资源来训练。 介绍使用人工神经网络 (ANN) 的多元线性回归分析是一种机器学习技术,它利用神经网络根据输入变量预测连续输出变量。它是对复杂的非线性关系进行建模的强大工具,可应用于金融、经济、工程等广泛领域。 回归分析的人工神经网络主要有两种类型:前馈神经网络和递归神经网络。前馈神经网络是最常用的类型,由处理输入数据并产生输出的神经元层组成。相比之下,递归神经网络被设计用于处理顺序数据,并具有允许信息多次流经网络的循环。两种类型的人工神经网络都有其优势,可以根据问题和数据集使用。
多元线性回归是分析多个自变量与单个因变量之间关系的强大工具。目标是创建一个模型,该模型可以根据自变量的值准确预测因变量的值。 该形式的方程表示模型: Y=b0+b1X1+b2X2+...+bnXn 其中 Y 是因变量,X1、X2、...、Xn 是自变量,b0、b1、b2、...、bn 是模型系数。系数表示每个自变量与因变量之间的关系。 最小二乘法等方法用于估计系数,该系数使因变量的预测值与实际值之间的平方差之和最小化。 估计系数后,该模型可用于预测给定自变量值的因变量值。该模型还可用于确定每个自变量在解释因变量变化方面的相对重要性。 多元线性回归是一种广泛使用的统计方法,在金融、经济和市场营销等领域特别有用。识别多个变量之间的关系,例如在医学、生态和社会科学研究中,也很有用。 多元线性回归的一个例子可能是一项研究,研究人员试图根据房屋的大小(以平方英尺为单位)、卧室数量和所在社区来预测房屋的价格。在这种情况下,自变量将是房屋大小、卧室数量和社区,因变量将是房屋的价格。
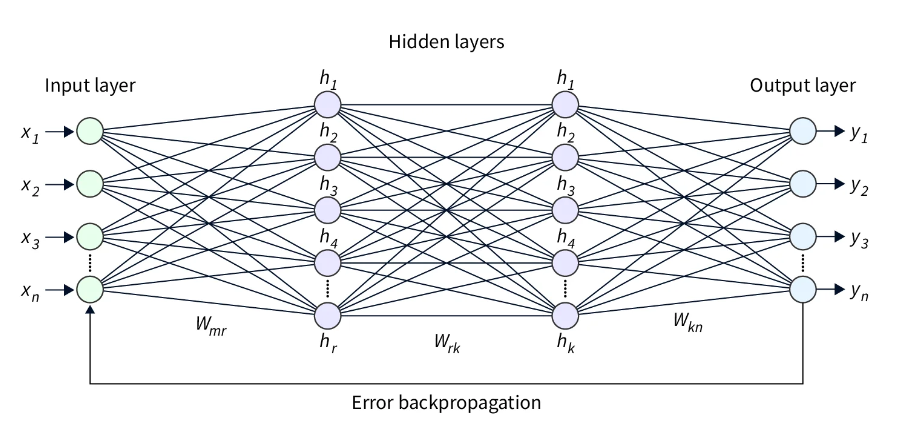
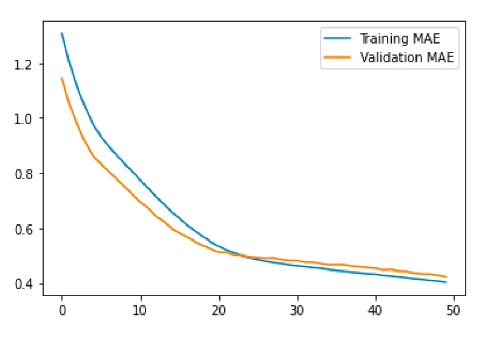
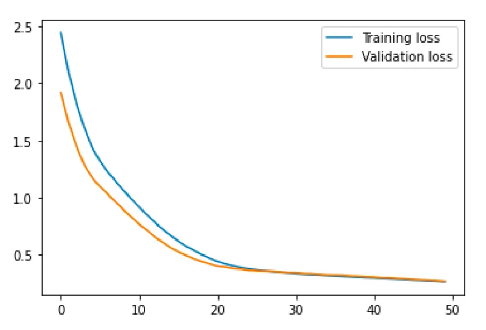
深度神经网络 (DNN) 是一种具有许多层的人工神经网络,通常由输入层和输出层之间的多个隐藏层组成。DNN 可以学习数据中的复杂关系,并在各种任务(包括回归)上获得最先进的结果。 在使用 DNN 的回归分析中,目标是学习将输入特征映射到输出的函数,以便模型做出的预测尽可能准确。输入特征通过 DNN 的输入层,然后由隐藏层处理,隐藏层使用非线性激活函数来学习数据中的复杂关系。DNN 的输出层根据处理后的输入特征生成因变量的预测。 为了训练用于回归的 DNN,损失函数用于测量预测输出和真实输出之间的误差。然后使用优化算法(例如随机梯度下降)来调整网络权重以最小化损失。然后,我们可以使用经过训练的 DNN 通过输入输入特征的值并计算相应的输出来预测新数据。 使用深度神经网络创建回归有几个步骤: 收集和预处理数据:第一步是收集和预处理适当的数据,以确保其采用神经网络可以使用的格式。这可能涉及清理数据、处理缺失值和规范化数据。 定义模型架构:下一步是定义神经网络的架构。这包括选择层的类型(密集层或卷积层)、每层中的神经元数量以及要使用的激活函数。 编译模型:定义架构后,我们必须编译模型。这涉及指定损失函数、优化器以及我们将用于评估模型的任何指标。 训练模型:下一步是使用预处理的数据训练模型。这涉及将数据输入模型并调整网络中神经元的权重和偏差,以最小化损失函数。 评估模型:训练模型后,必须对其进行评估以确定其性能。这可能涉及使用单独的数据集(或训练数据的子集)来评估模型做出准确预测的能力。 微调模型:根据评估结果,模型可能需要微调以提高其性能。这可能涉及调整架构、重新训练模型或试验不同的超参数。 进行预测:一旦模型经过微调,我们就可以用它来预测新数据。 部署:训练模型后,可以在生产环境中部署模型以预测新的数据点。 请注意,这些步骤是常规步骤,可能因任务和数据集的具体要求而异。 构建 Keras 顺序模型 导入必要的模块Sequential 模型类和 Dense layer 类分别从 keras.models 和 keras.layers 导入,train_test_split 函数从 sklearn.model_selection 导入。numpy 库也以别名 np 导入。 #Import packages from keras.models import Sequential from keras.layers import Dense import numpy as np from sklearn.model_selection import train_test_split 生成随机输入数据 随机输入数据是使用 NumPy 的 random.rand 函数生成的,该函数生成一个介于 0 和 1 之间的随机值数组。调用 np.random.seed 函数来设置随机种子,确保每次运行代码时都生成相同的随机数据。 # Generate random input data np.random.seed(0) X = np.random.rand(1000, 3) 定义 True 函数定义了一个名为 true_fun 的函数,该函数接受一个输入数据数组,并根据某些输入值的正弦和余弦加上另一个输入值的两倍返回一个值。 # Define the true function def true_fun(X): return np.sin(1.5 * np.pi * X[:, 0]) + np.cos(1.5 * np.pi * X[:, 1]) + 2 * X[:, 2] 将数据拆分为训练集、测试集和验证集 该代码首先使用以下行生成输入变量“X”和相应目标变量“y”的数据集:y = true_fun(X) + np.random.normal(0, 0.1, 大小=1000) 在这里,“true_fun(X)”表示生成目标变量的一些基础函数,“np.random.normal(0, 0.1, size=1000)”部分将平均值为 0、标准差为 0.1 的随机正态噪声添加到目标变量上。这种噪声模拟了大多数数据集中存在的真实世界变异性。 生成数据集后,代码使用 scikit-learn 库中的 train_test_split 函数将数据划分为训练集、验证集和测试集。对 train_test_split 的第一次调用通过传递输入变量和目标变量,将 test_size 参数设置为 0.2,并设置随机种子以实现可重复性,将数据分为 80% 的训练集和 20% 的测试集。 第二次调用 train_test_split 用于将训练集进一步划分为 80% 训练集和 20% 验证集。这是通过传递训练集的输入变量和目标变量,将test_size参数设置为 0.2,并设置随机种子以提高可重复性来完成的。这将为我们提供三个数据集:X_train、X_val、X_test 和 y_train、y_val 和 y_test。 通过使用这三个数据集,可以使用 X_train、y_train 来训练模型,使用 X_val、y_val 来微调模型,并使用 X_test、y_test 来评估模型在看不见的数据上的性能。 # Generate output data y = true_fun(X) + np.random.normal(0, 0.1, size=1000) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42) 定义模型 第一行 “model = Sequential()” 创建一个空的顺序模型。接下来的两行将图层添加到模型中:model.add(Dense(30, input_dim=3, activation='relu')):此行向模型添加一个密集(也称为全连接)层。Keras 中的“Dense”类在神经网络中创建了一个标准的神经元层。第一个参数“30”是该层中的神经元数量,“input_dim=3”用于指定输入特征的数量,“activation='relu'”指定该层中使用的激活函数。在这种情况下,激活函数是整流线性单元(ReLU)激活函数。model.add(Dense(1, activation='linear')):这条线为模型添加了另一个密集层,具有一个神经元和线性激活函数。这是一个简单的前馈神经网络架构,具有两层,用于回归任务。第一层有 30 个神经元,它接受三个输入特征,然后通过 ReLU 激活函数传递输入。然后第二层有一个神经元,通过线性激活函数传递输出。 # Define the model model = Sequential() model.add(Dense(30, input_dim=3, activation='relu')) model.add(Dense(1, activation='linear')) 编译模型代码行 “model.compile(loss='mean_squared_error', optimizer='adam', metrics=['mean_absolute_error'])” 用于配置神经网络模型的学习过程。 compile 方法在训练模型之前配置学习过程。它需要三个参数: 损失:这是模型在训练期间最小化的功能。在这种情况下,损失函数为“mean_squared_error”,它测量预测值和实际值之间的平均平方差。 优化:这是用于在训练期间更新模型权重的算法。在本例中,使用的优化器是“adam”。Adam 是一种优化算法,可调整每个参数的学习率。对于大多数问题来说,它通常是一个不错的选择。 指标:这将监视训练和测试步骤。在本例中,使用的指标为“mean_absolute_error”,即预测值和实际值之间的平均绝对差值。 model.compile(loss='mean_squared_error', optimizer='adam', metrics=['mean_absolute_error']) 做出预测代码行“history = model.fit(X_train, y_train, epochs=50, batch_size=30, validation_data=(X_val, y_val))“ 用于使用训练数据和目标数据训练神经网络模型。 fit 方法用于在输入数据和目标数据上训练模型。它需要几个参数: X_train,y_train:这些是训练数据和目标数据。模型将在训练期间使用此数据更新其权重。 时代:模型循环遍历训练数据的次数。纪元是整个训练数据集的完整迭代。在这种情况下,模型将遍历训练数据 50 次。 batch_size:这是每次梯度更新的样本数。它将训练数据划分为称为批次的较小块,模型将更新每个批次的权重。在本例中,批次大小设置为 30,这意味着模型将更新每 30 个样本的权重。 validation_data:此数据用于评估模型在训练期间的性能。验证数据用于评估模型在每个周期后的性能,并用于检查模型是否过拟合。在本例中,它使用 X_val 和 y_val 作为验证数据。 fit 方法返回一个 history 对象、一个包含训练和验证损失的字典,以及每个 epoch 的指标值。我们可以使用此历史记录对象来绘制一段时间内的训练和验证损失以及指标值,这有助于诊断过拟合或欠拟合等问题。 history = model.fit(X_train, y_train, epochs=50, batch_size=30, validation_data=(X_val, y_val))对测试集进行预测:该模型使用预测方法对测试集进行预测。 predictions = model.predict(X_test) 性能分析此代码绘制了神经网络训练过程中的训练和验证损失以及训练和验证平均绝对误差 (MAE)。 首先,它从历史对象返回的 model.fit 方法中提取损失、验证损失、平均绝对误差和验证均值绝对误差值。 loss = history.history['loss']:此行从历史对象中提取训练损失值。val_loss = history.history['val_loss']:此行从历史记录对象中提取验证损失值。mae = history.history['mean_absolute_error']:此行从历史记录对象中提取训练平均绝对误差值。val_mae = history.history['val_mean_absolute_error']:此行从历史记录对象中提取验证平均绝对误差值。 loss = history.history['loss'] val_loss = history.history['val_loss'] mae = history.history['mean_absolute_error'] val_mae = history.history['val_mean_absolute_error']然后,它使用 python 中的 Matplotlib 库绘制训练和验证损失。 plt.plot(loss, label='训练损失') :此行绘制训练损失值。plt.plot(val_loss, label='Validation loss') :此行绘制验证损失值。plt.legend():此行在图中添加图例,以指示哪条线对应于训练损失,哪条线对应于验证损失。plt.show() :此行显示绘图。 # Plot the training and validation loss plt.plot(loss, label='Training loss') plt.plot(val_loss, label='Validation loss') plt.legend() plt.show()同样,它绘制了训练和验证平均绝对误差。 plt.plot(mae, label='训练 MAE') :此行绘制训练平均绝对误差值。plt.plot(val_mae, label='Validation MAE') :此行绘制验证平均绝对误差值。plt.legend():此行向图中添加图例,以指示哪条线对应于训练 MAE,哪条线对应于验证 MAE。plt.show() :此行显示绘图。 # Plot the training and validation accuracy plt.plot(mae, label='Training MAE') plt.plot(val_mae, label='Validation MAE') plt.legend() plt.show()
|
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |