03标签丰富 |
您所在的位置:网站首页 › 图片标注处理赚钱是真的吗 › 03标签丰富 |
03标签丰富
|
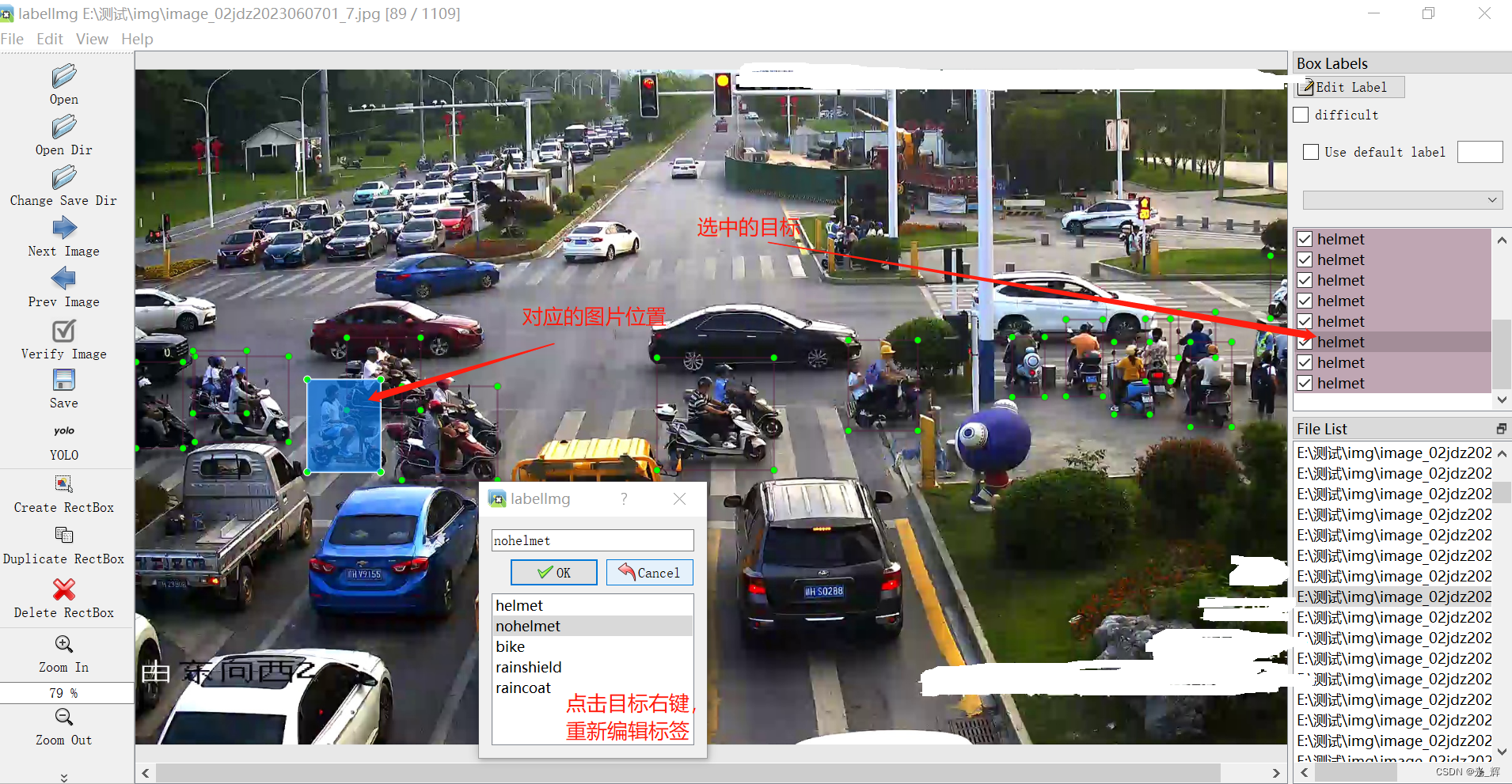
在实际生产项目中,为了提升目标识别的准确性,我们往往需要3000-5000张图片进行标注。而直接参与过标注的人都有一个共同的感觉,就是标注是一个简单、枯燥、无聊且十分耗时费力的差事。为此,我们可以在有了初步训练模型的基础上,采用更加自动化的方式进行标注,届时,你讲不用每个照片、每个目标的重复标注,而是直接在现有模型对图片进行识别后的结果上进行调整标注或者新增标注。本章节,笔者将重点围绕使用labelIMG进行自动化高效率的标注进行讲解。 1、前期模型准备前期,笔者使用约1000张图片对摩托车、电动自行车头盔配搭和加装雨棚进行了训练,得到了一个已经初步训练好的模型。暂且将其命名为“best_jx.pt”。下面我们将依托该pt文件模型,对新增的图片进行识别,并导入labelIMG进行自动化标准,从而非常明显的提升我们的图片标注工作效率。 相信,当你读到本文时,你也已经有了自己的best.pt训练模型文件,大家可以直接套用本文档的步骤。 2、编写图片识别脚本程序当你的图片文件夹中已经有了上千张最新的图片后,我们现在要做的就是编写代码,调用前期你已经生成的pt文件,将文件夹中的图片逐一进行识别。唯一不同的是,本次我们不光是要识别,还需要将识别的结果以标签的形式存为txt文档。这个功能YOLO V8已经在程序中实现了,我们只需要直接调用。 2.1 图片标签生成程序具体代码示例如下: from ultralytics import YOLO import os import glob import threading # 加载现有的xxx.pt模型 model = YOLO("E:/pyCharmProject/pythonProjectDetection/best_jx.pt") # 指定图片文件夹的路径 image_folder = "E:/pyCharmProject/DetectionProjectHelmetRainshield/20230817pan1IMG/imgs/" #本函数为调用YOLO V8的predict方法,进行识别,并将其存为txt格式的标签文件 def auto_get_img_tag(image_path): results = model.predict(source=image_path, save_txt=True) print('done..........',image_path) return results # 对每张图片进行预测,并保存标签文件 for image_path in glob.glob(image_folder + "*.jpg"): # 对图片进行预测,并保存标签文件 results = model.predict(source=image_path, save_txt=True) print('done..........', image_path) print('done.....................overall')上述函数中使用了model.predict()方法,其与笔者之前直接使用的model()方法有所不同。 result = model(source) 是一个低级的 API,它直接调用了模型的 forward 方法,返回一个 Results 对象,其中包含了模型的原始输出,例如预测的类别、置信度、边界框坐标等。这个 API 适合那些想要对模型的输出进行自定义处理的高级用户,但是它不会执行任何后处理或保存操作,也不会考虑任何预测参数,例如图像大小、置信度阈值等。 result=model.predict(source) 是一个高级的 API,它封装了模型的 forward 方法,并且执行了一些后处理和保存操作,例如非极大值抑制、标签文件生成、结果可视化等。这个 API 适合那些想要快速得到预测结果的普通用户,但是它需要指定一些预测参数,例如图像大小、置信度阈值、保存目录等。这些参数可以在调用 predict 方法时传入,也可以在配置文件中设置。 总之,result = model(source) 和 result=model.predict(source) 的区别在于前者返回的是模型的原始输出,后者返回的是模型的后处理输出。前者更灵活,但需要用户自己处理结果;后者更方便,但需要用户指定参数。你可以根据你的需求选择合适的 API。 #2.2 并发实现图片标签生成程序当我们图片很多的时候,我们就需要使用高并发的形式实现。示例代码如下。 from ultralytics import YOLO import glob from concurrent.futures import ThreadPoolExecutor # 加载现有的xxx.pt模型 model = YOLO("E:/pyCharmProject/pythonProject1Chu/best_jiangxi.pt") # 指定图片文件夹的路径 image_folder = "E:/pyCharmProject/DetectionProjectHelmetRainshield/20230817pan1IMG/imgs/" # 本函数为调用YOLO V8的predict方法,进行识别,并将其存为txt格式的标签文件 def auto_get_img_tag(image_path): results = model.predict(source=image_path, save_txt=True) print('done..........', image_path) return results # 创建一个线程池,指定最大线程数为4 pool = ThreadPoolExecutor(max_workers=4) # 对每张图片进行预测,并保存标签文件 for image_path in glob.glob(image_folder + "*.jpg"): # 使用map方法将函数和参数传递给线程池 pool.map(auto_get_img_tag, [image_path]) # 等待所有线程完成 pool.shutdown(wait=True) print('done.....................overall')为了让代码支持并发,笔者创建一个线程池,使用ThreadPoolExecutor类来管理多个线程,并使用map方法来将您的函数应用到每个图片路径上。这样,就可以同时处理多张图片,并保存标签文件。 3、生成所需打标签图片的label文件运行上述代码后,你该程序py脚本文件的根目录看到一个新的文件夹,名称为run,每张图片生成的label文件就在这个文件夹中,具体的存储路径为: \runs\detect\predict\labels 其生成的文件进入下图所示: 至此,我们就已经通过编写的脚本程序,实现了对要逐个打标签的图片进行预处理的工作了,下部就可以将其导入labelIMG进行自动化的打标签操作了。 4、准备“class.txt”文件我们知道,labelIMG工具在对图片打标签后,会在输出label的txt文档目录文件夹中,同步生成一个class.txt文件,按顺序记录所有标签内容。为此,我们为了实现自动化的标签识别,也需要提前准备好class.txt文件,并提前存放在标签输出目录内。 正常来说,我们根据要打标签的内容,肯定是知道class.txt中具体要写什么标签的,如下图所示: 由于图片的量太大,我们很难由一个人一次打完,或者很难统筹每个人都是按同样的标签顺序进行标注。为此,在laeblIMG工具中,有一个预先设置标签的功能。也就是我们可以在以下目录venv/Lib/site-packages/labelImg/data,找到predefined_classes.txt文件。在这个文件中,我们可以提前设置好所有的标签类型和标签顺序,这样labelIMG在进行打标签的时候,就不需要每次出现新的标签就需要手动输入的情况,而是可以在所有预先设置好的标签选项中进行选择。如下图所示,笔者已经预先设置了5个标签,并明确了其顺序。 我们知道,当我们在pycharm的terminal命令行窗口输入labelIMG命令后,程序将自动启动labelIMG工具,如下图所示。 当我们明确了上面的思路,便可清晰的知道我们需要做标注的图片和生成的label文件以及class.txt文件需要存放的路径了。 6、开始高效图片标注工作在本例子中,笔者将图片存放于以下文件夹目录:E:\测试\img,将label文件和class.txt文件存放于以下文件夹目录:E:\测试\label。因此,我们在labelIMG工具中按照上图所示,选择完成后,便可发现我们打开的图片已经有了相关的标注情况。只需要我们手动检查或调整就可以了。如下图所示: 在这里,我们便可以逐一对目标进行该检查,对识别错误的,我们可以点击目标右键,重新编辑标签属性,重新编辑保存的label文档,和直接生成的文档,效果是一样的。如下图所示: |
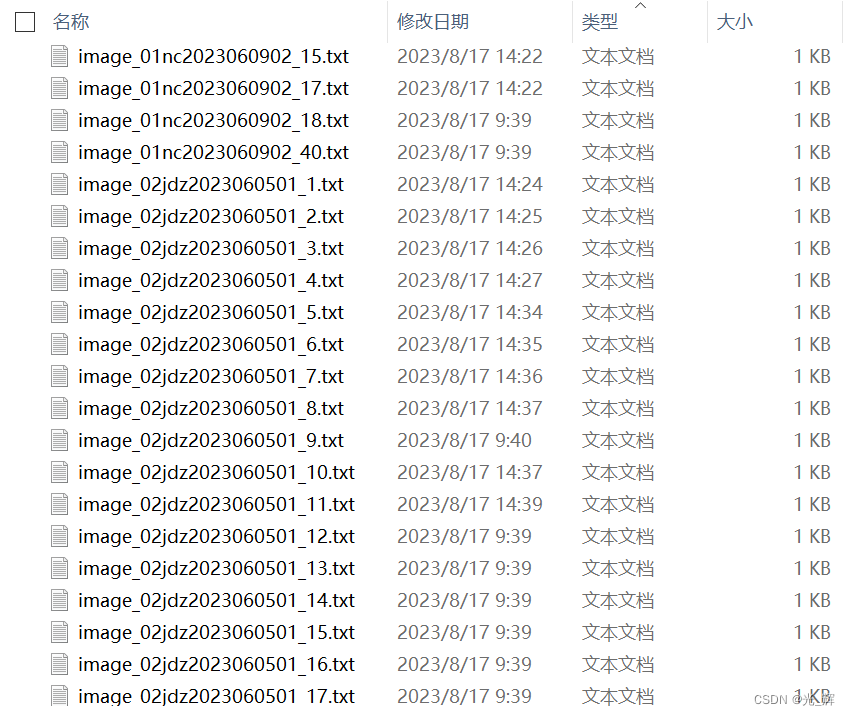 当我们将生成的文本,与导入上述识别脚本程序的图片比较,可以发现,txt标签文件的名称与图片的名称是一一对应的。
当我们将生成的文本,与导入上述识别脚本程序的图片比较,可以发现,txt标签文件的名称与图片的名称是一一对应的。 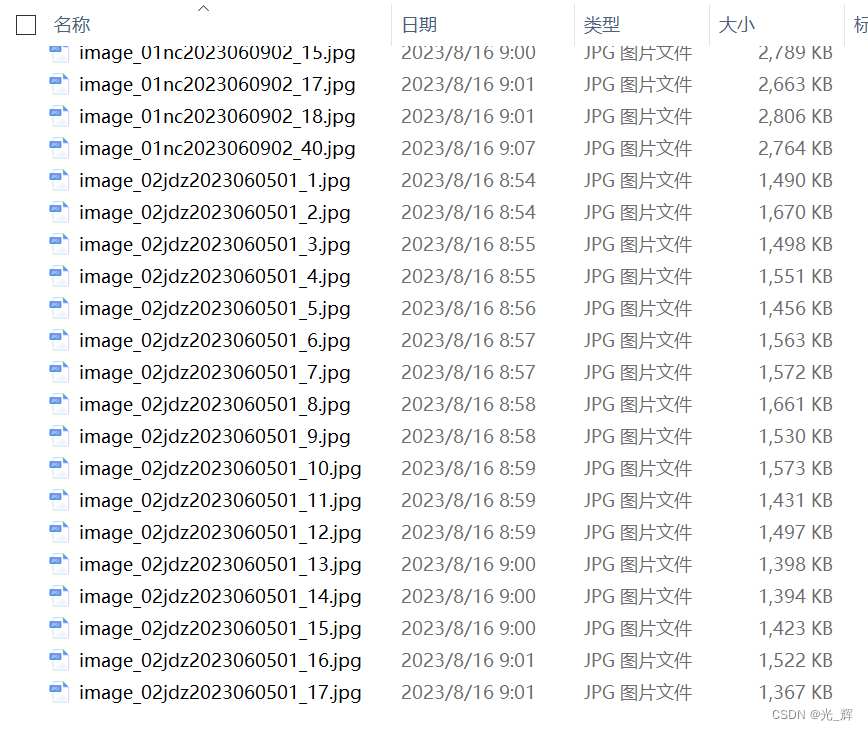
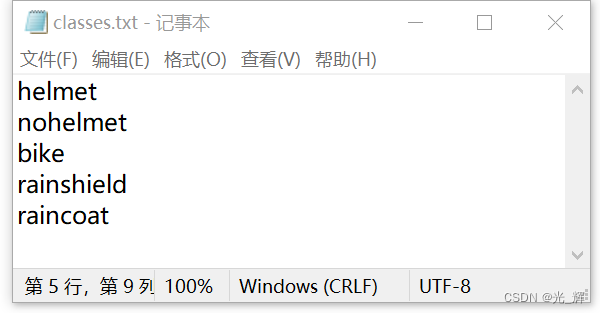 但值得我们非常需要注意的一点是!按照labelIMG生成class.txt文件的逻辑,文件中各个标签的顺序默认是根据在所有图片中,首次打上这个标签的顺序来的。比如我们对这些图片进行打标签操作时,第一个打的是nohelmet,那么nohelmet会出现在第一行。
但值得我们非常需要注意的一点是!按照labelIMG生成class.txt文件的逻辑,文件中各个标签的顺序默认是根据在所有图片中,首次打上这个标签的顺序来的。比如我们对这些图片进行打标签操作时,第一个打的是nohelmet,那么nohelmet会出现在第一行。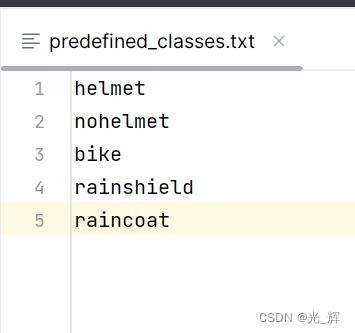 我们在实际项目中,可以直接将predefined_classes.txt中预先设定的标签内容直接复制到class.txt文件中。从而确保我们为labelIMG工具提前准备的class.txt文件没有错误,从而不会出现工具中途卡死、闪退,造成需要重新打标签的情况。
我们在实际项目中,可以直接将predefined_classes.txt中预先设定的标签内容直接复制到class.txt文件中。从而确保我们为labelIMG工具提前准备的class.txt文件没有错误,从而不会出现工具中途卡死、闪退,造成需要重新打标签的情况。 启动labelIMG工具后,我们首先要指定“Open Dir”和"Change Save Dir",如下图所示。也就是说,设定好我们读取图片的文件夹,和将生成的label文件存放的文件夹。
启动labelIMG工具后,我们首先要指定“Open Dir”和"Change Save Dir",如下图所示。也就是说,设定好我们读取图片的文件夹,和将生成的label文件存放的文件夹。 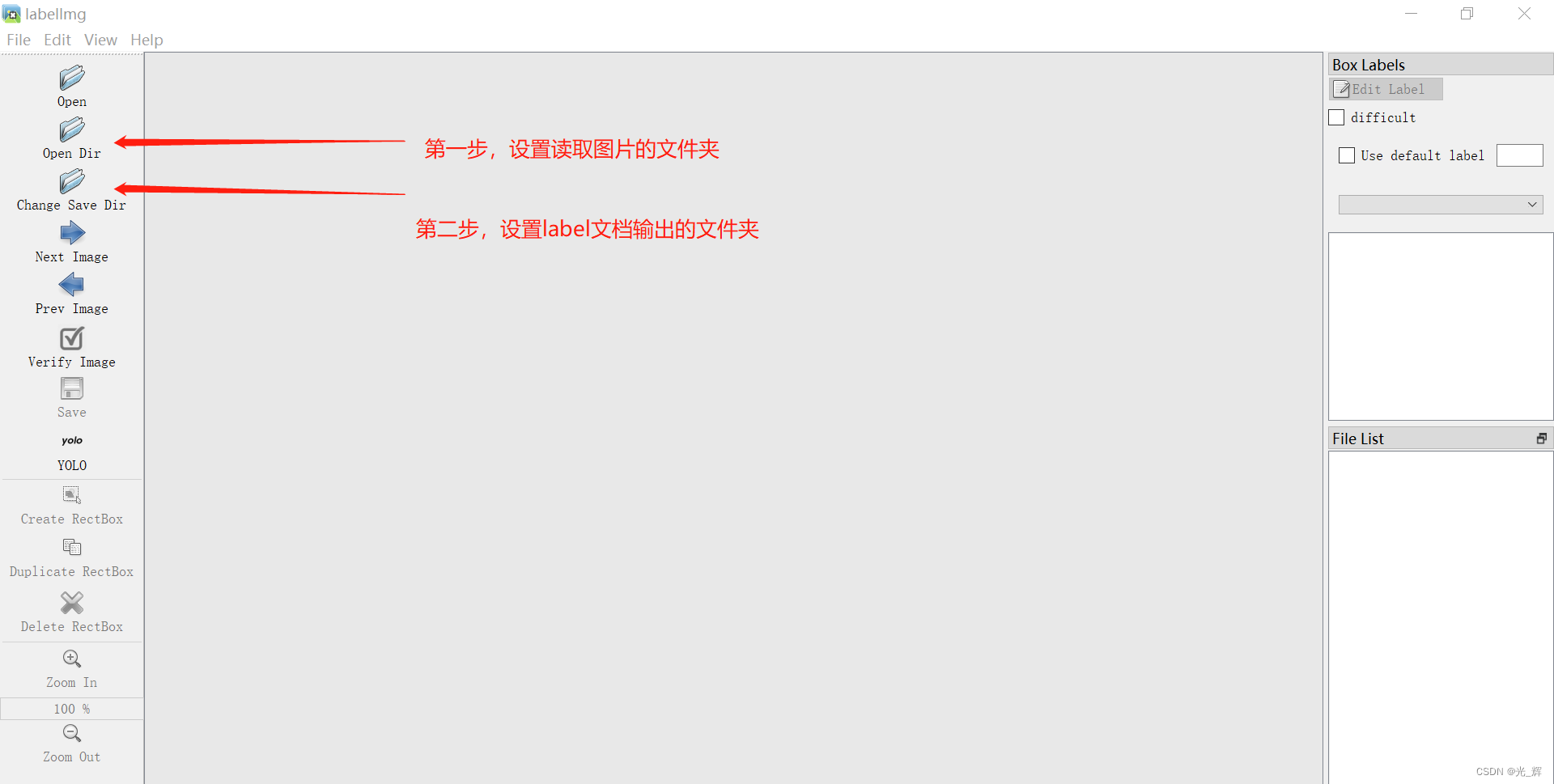 由于我们前期已经通过脚本程序预先生成了label文件,我们就可以理解为是电脑用我们的前期训练的模型,帮我们使用这个工具对所有图片进行了标注,并生成了对应的label文件,我们现在需要做的只是逐一图片的检查其标注情况是否准确,如果发现不准确或者遗漏的,我们可以在labelIMG工具中再进行手动调整。
由于我们前期已经通过脚本程序预先生成了label文件,我们就可以理解为是电脑用我们的前期训练的模型,帮我们使用这个工具对所有图片进行了标注,并生成了对应的label文件,我们现在需要做的只是逐一图片的检查其标注情况是否准确,如果发现不准确或者遗漏的,我们可以在labelIMG工具中再进行手动调整。
 我们完成所有图片的标注审核和修改工作后,便可直接在E:\测试\label目录下,获取最新的label文件了。这些文件以及配套的图片文件,还有我们提前生成的class.txt文件,都需要进一步拷贝到用来做YOLO v8训练使用。这一点就和正常操作步骤没有任何不同了。
我们完成所有图片的标注审核和修改工作后,便可直接在E:\测试\label目录下,获取最新的label文件了。这些文件以及配套的图片文件,还有我们提前生成的class.txt文件,都需要进一步拷贝到用来做YOLO v8训练使用。这一点就和正常操作步骤没有任何不同了。【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |