Python 实战 |
您所在的位置:网站首页 › 图片中的文字怎么提取到表格中 › Python 实战 |
Python 实战
|
更多详情请点击查看原文:Python 实战 | 从 PDF 中提取(框线不全的)表格 Python教学专栏,旨在为初学者提供系统、全面的Python编程学习体验。通过逐步讲解Python基础语言和编程逻辑,结合实操案例,让小白也能轻松搞懂Python!>>>点击此处查看往期Python教学内容 本文目录 一、引言 二、camelot-py 介绍 三、安装 camelot-py 四、camelot-py 使用方法 五、camelot-py 的其他实用参数 六、结束语 七、相关推荐 本文共7015个字,阅读大约需要18分钟,欢迎指正! 一、引言社科同胞们一定有过收集/整理数据的经历吧,有时候一些原始数据被存放在大量的 PDF 文件中,例如上市公司公告公报中的各种指标信息,但如何快速地从大量的 PDF 中提取出那些表格却是一个难题。在过往的文章中,我们曾向大家分享过使用 Python 的 pdfplumber 库从 PDF 中读取表格的方法(>>>点击查看“一文读懂如何用python读取并处理PDF中的表格”),但经过长期使用,笔者注意到这个库在默认情况下解析时,对表格的要求非常之高。只有当表格的全部框线都存在时才能发挥作用,如果你要读取的表格框线不全,那么读取时极易丢失部分行或列。后来笔者找到了一个在表格框线不全时也能有不错解析效果的工具库,特此与大家分享使用方法和代码。 二、camelot-py 介绍一个基于 Ghostscript 的库,可以从 PDF 文件中提取表格数据,它使用了一种名为 Lattice 的算法,基于文本的近似排列来解析表,由此实现无框线(或框线不全)表格的解析,解析结果可以直接转为 DataFrame,进而存储为 Excel 表。 三、安装 camelot-pycamelot库的安装命令如下: pip install camelot-py # 常规安装方式 pip install camelot-py[cv] # 常规安装后如果调用报错,卸载后改用此命令, # 表示不仅安装 camelot自身,还会安装其他依赖库调用时发现camelot依赖PyPDF2库的特定版本,笔者的PyPDF2版本为2.2.2,可以正常运行。 四、camelot-py 使用方法笔者找到一个仅带有少量框线表格的某上市公司年度报告的 PDF 文件,表格位于第 91 页,如下图: 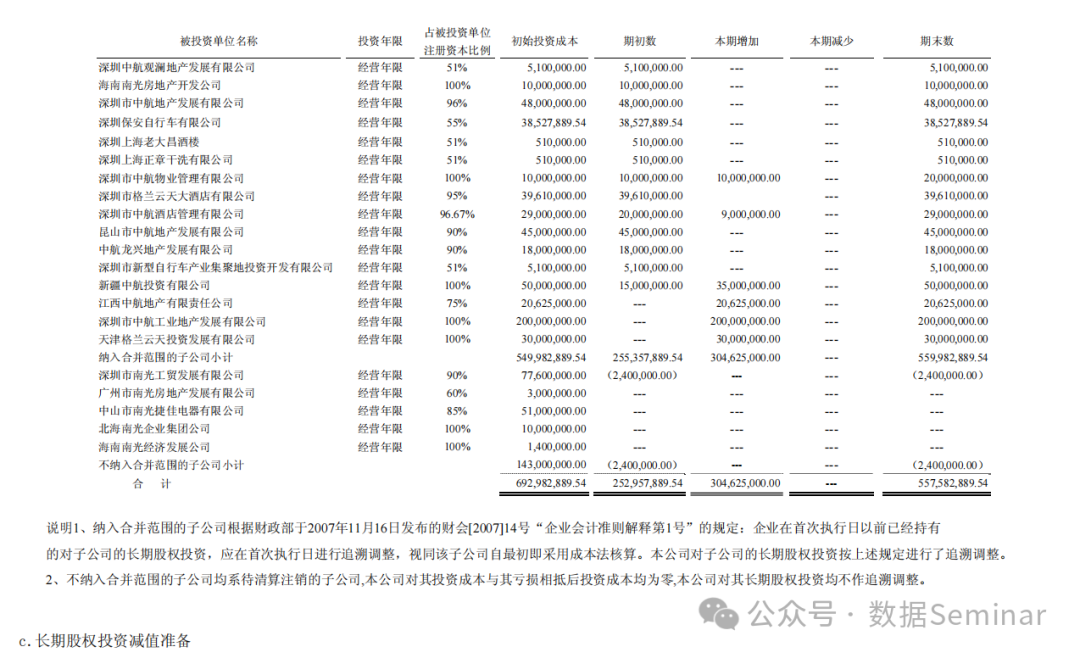
图片来源:《深圳中航地产股份有限公司二○○七年年度报告》-成本法核算的其他股权投资 下面是使用 camelot 读取该表格的 Python 代码: # 可以不导入 pandas,因为导入该库时会自动导入 pandas import camelot.io as camelot # 解析表格 result = camelot.read_pdf( filepath="001914_2007-12-31_2007.pdf", # 94 pages='94', flavor='stream', edge_tol=200, ) # 解析结果中可能包含多个表格,下面把解析到的第一个表格转为 DataFrame # 如果解析结果中不含表格,那么将会报错 df = result[0].df df解析结果如下图: 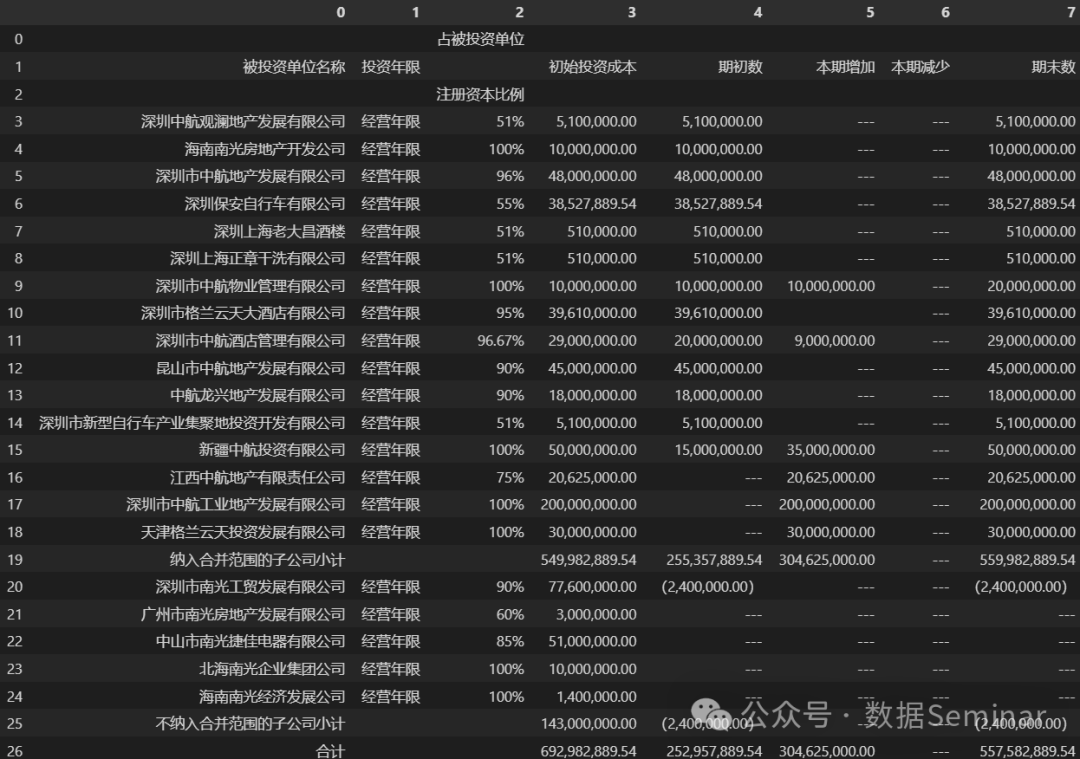
从解析结果来看,效果十分不错,唯一的问题在于表头的解析,这就需要对解析结果进行二次清洗,但总的来说效果已经很喜人了。 五、camelot-py 的其他实用参数让人欣喜的是,camelot并不是一个解析结果只能“看脸”的工具库,它还提供了很多可以干预或优化解析结果的参数,笔者将其中几个必要和实用的参数罗列在下表。 参数名称 取值 描述 filepath 字符串 pdf 文件路径。 pages 字符串,如"91"、"1,2,3"、"91-end"、"all" 从 1 开始算,必须是字符串,可以一次性解析多页,例如:'1,2,3'、'91-end'(表示从91页到最后一页)、'all'(全部页)。 flavor 'lattice'或'stream';默认值为 lattice 针对不同类型的PDF表格指定解析方式,可选参数有'lattice'(格子解析)和'stream'(流解析),前者适用于解析带有完整框线的表格,后者常用于解析框线不全的表格。 edge_tol 数字,默认值为 100 指定表格边缘容差(边缘容忍度)。它是一个浮点数,用于控制识别表格边缘的容差范围。默认值为 100,如果表格的某两行之间间隙稍大,导致表格解析被解析为多个表格,那么可以释放增加该参数的值,避免读取的表格不完整;或者减少参数值,这样当多个表之间的间隙不是特别大时也可以将其分开。 split_text True 或 False,默认值为 True 当单元格中有分行的文本时,是否应该将它们分为多个单元格。 strip_text 字符串,默认值为 空字符 '' 去除单元格中的指定字符,默认值为'',即不清洗,如果需要取出多种不需要的字符,那么直接将多个字符组合成一个字符串传入即可。 camelot库还有其他有用的参数,如果大家感兴趣,可以去查看源代码,笔者将源码中的参数介绍附在下方: """ Read PDF and return extracted tables. Note: kwargs annotated with ^ can only be used with flavor='stream' and kwargs annotated with * can only be used with flavor='lattice'. Parameters ---------- filepath : str Filepath or URL of the PDF file. pages : str, optional (default: '1') Comma-separated page numbers. Example: '1,3,4' or '1,4-end' or 'all'. password : str, optional (default: None) Password for decryption. flavor : str (default: 'lattice') The parsing method to use ('lattice' or 'stream'). Lattice is used by default. suppress_stdout : bool, optional (default: True) Print all logs and warnings. layout_kwargs : dict, optional (default: {}) A dict of `pdfminer.layout.LAParams `_ kwargs. table_areas : list, optional (default: None) List of table area strings of the form x1,y1,x2,y2 where (x1, y1) -> left-top and (x2, y2) -> right-bottom in PDF coordinate space. columns^ : list, optional (default: None) List of column x-coordinates strings where the coordinates are comma-separated. split_text : bool, optional (default: False) Split text that spans across multiple cells. flag_size : bool, optional (default: False) Flag text based on font size. Useful to detect super/subscripts. Adds around flagged text. strip_text : str, optional (default: '') Characters that should be stripped from a string before assigning it to a cell. row_tol^ : int, optional (default: 2) Tolerance parameter used to combine text vertically, to generate rows. column_tol^ : int, optional (default: 0) Tolerance parameter used to combine text horizontally, to generate columns. process_background* : bool, optional (default: False) Process background lines. line_scale* : int, optional (default: 15) Line size scaling factor. The larger the value the smaller the detected lines. Making it very large will lead to text being detected as lines. copy_text* : list, optional (default: None) {'h', 'v'} Direction in which text in a spanning cell will be copied over. shift_text* : list, optional (default: ['l', 't']) {'l', 'r', 't', 'b'} Direction in which text in a spanning cell will flow. line_tol* : int, optional (default: 2) Tolerance parameter used to merge close vertical and horizontal lines. joint_tol* : int, optional (default: 2) Tolerance parameter used to decide whether the detected lines and points lie close to each other. threshold_blocksize* : int, optional (default: 15) Size of a pixel neighborhood that is used to calculate a threshold value for the pixel: 3, 5, 7, and so on. For more information, refer `OpenCV's adaptiveThreshold `_. threshold_constant* : int, optional (default: -2) Constant subtracted from the mean or weighted mean. Normally, it is positive but may be zero or negative as well. For more information, refer `OpenCV's adaptiveThreshold `_. iterations* : int, optional (default: 0) Number of times for erosion/dilation is applied. For more information, refer `OpenCV's dilate `_. resolution* : int, optional (default: 300) Resolution used for PDF to PNG conversion. Returns ------- tables : camelot.core.TableList """ 六、结束语提取 PDF 中的表格是研究工作中的一项基础技术工作,传统的表格解析方法难以解决表格框线不全的问题,所以能解析的表格十分有限,而类似于 camelot 这种基于视觉的表格解析方式则强大很多。不过使用 camelot 时也会遇到一些奇怪的问题,例如目录等一些非表格文本可能也会被识别为表格,所以在应用中还需要根据实际情况选择最合适的工具库。 如果你想学习各种 Python 编程技巧,提升个人竞争力,那就加入我们的数据 Seminar 交流群吧,欢迎大家在社群内交流、探索、学习,一起进步!同时您也可以分享通过数据 Seminar 学到的技能以及得到的成果。 注:请查看原文Python 实战 | 从 PDF 中提取(框线不全的)表格,以获取客服联系方式。 七、相关推荐 Python 教学Python 教学 | 学习 Python 第一步——环境安装与配置 Python 教学 | Python 基本数据类型 Python 教学 | Python 字符串操作(上) Python 教学 | Python 字符串操作(下) Python 教学 | Python 变量与基本运算 Python 教学 | 组合数据类型-列表 Python 教学 | 组合数据类型-集合(内含实例) Python 教学 | 组合数据类型 - 字典&元组 Python 教学 | Python 中的分支结构(判断语句) Python 教学 | Python 中的循环结构(上) Python 教学 | Python 中的循环结构(下) Python 教学 | Python 函数的定义与调用 Python 教学 | Python 内置函数 Python 教学 | 最常用的标准库之一 —— os Python 教学 | 盘点 Python 数据处理常用标准库 Python 教学 | “小白”友好型正则表达式教学(一) Python 教学 | “小白”友好型正则表达式教学(二) Python 教学 | “小白”友好型正则表达式教学(三) Python 教学 | 数据处理必备工具之 Pandas(基础篇) Python 教学 | 数据处理必备工具之 Pandas(数据的读取与导出) Python 教学 | Pandas 数据索引与数据选取 Python 教学 | Pandas 妙不可言的条件数据筛选 Python 教学 | Pandas 缺失值与重复值的处理方法 Python 教学 | Pandas 表格数据行列变换 Python 教学 | Pandas 表格字段类型精讲(含类型转换) Python 教学 | Pandas 数据合并(含目录文件合并案例) Python 教学 | Pandas 数据匹配(含实操案例) Python 教学 | Pandas 函数应用(apply/map)【上】 Python 教学 | Pandas 函数应用(apply/map)【下】 Python 教学 | Pandas 分组聚合与数据排序 Python 教学 | Pandas 时间数据处理方法 Python 教学 | 列表推导式 & 字典推导式 Python 教学 | 一文搞懂面向对象中的“类和实例” Python 教学 | Python 学习路线+经验分享,新手必看! Python 教学 | 解密 Windows 中的 Path 环境变量 Python实战Python实战 | 如何使用 Python 调用 API Python 实战 | 使用正则表达式从文本中提取指标 大数据分析 | 用 Python 做文本词频分析 数据治理 | 从“今天中午吃什么”中学习Python文本相似度计算 数据治理 | 省下一个亿!一文读懂如何用python读取并处理PDF中的表格(赠送本文所用的PDF文件) 数据治理 | 还在人工识别表格呢?Python 调用百度 OCR API 又快又准 数据治理 | 如何用 Python 批量压缩/解压缩文件 案例分享:使用 Python 批量处理统计年鉴数据(上) 案例分享:使用 Python 批量处理统计年鉴数据(下) Python 实战 | ChatGPT + Python 实现全自动数据处理/可视化 ChatGPT在指尖跳舞: open-interpreter实现本地数据采集、处理一条龙 Python 实战 | 文本分析之文本关键词提取 Python 实战 | 文本分析工具之HanLP入门 Python 实战 | 进阶中文分词之 HanLP 词典分词(上) Python 实战 | 进阶中文分词之 HanLP 词典分词(下) Python实战 | 文本文件编码问题的 Python 解决方案 数据可视化数据可视化 | 讲究!用 Python 制作词云图学问多着呢 数据可视化 | 地址数据可视化—教你如何绘制地理散点图和热力图 数据可视化 | 太酷了!用 Python 绘制3D地理分布图 数据可视化 | 用 Python 制作动感十足的动态柱状图 数据可视化 | Python绘制多维柱状图:一图展示西部各省人口变迁【附本文数据和代码】 数据可视化 | 3D 柱状图一览各省农民合作社存量近十年变化 |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |