线性回归异常值分析之 |
您所在的位置:网站首页 › 回归检测模型 › 线性回归异常值分析之 |
线性回归异常值分析之
|
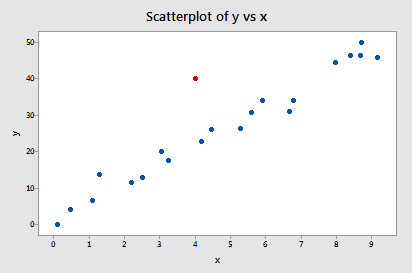
对于一组数据拟合模型时,我们希望保持拟合结果不要过度依赖于一个或几个观测,于是我们想知道这种点是否存在。离群点、高杠杆点、强影响点,都是数据观测中常见的异常数据形式,下面分别从概念,检测方法和处理方法三方面来谈论。 一 概念——————————————————————————————————————————— 1.高杠杆点X空间中的异常值,被称为高杠杆点,即其有异常的X值,X取值远离X均值。高杠杆点可能影响模型的性质,但并不是所有的高杠杆点都会影响回归系数;但可以确定的是,它对模型的汇总统计量(比如R方和回归系数的标准误差)或预测值有非常大的影响。
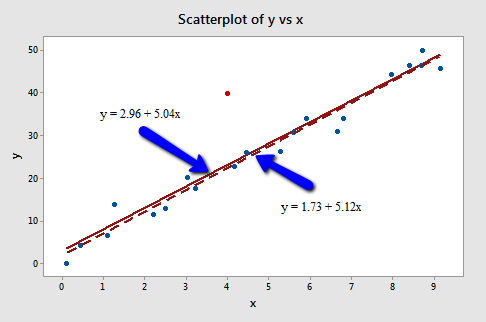
上图中的红色点,是一个高杠杆值的例子,其X值远离X的取值空间;
同时,该点离回归趋势线不远,因此不是离群点; 虚线和实线分别是包含红点在内和不包含红点在内训练出来的回归模型。可以看到,两条回归线之间相差不大,因此,高杠杆点不一定会显著影响模型系数的拟合结果。 2.离群点有异常Y值的观测值被称为离群点,由于其Y值远离拟合方程,该观测值的标准化残差通常较大;因为标准化残差近似服从均值为0,方差为1的正态分布,通常标准化残差的绝对值大于2或3时,即可判断该观测值为离群点。离群点根据其在X空间中的位置不同,可以对回归模型有从中等程度到重要程度的影响,使模型不合理,但不一定会显著影响模型系数的拟合结果。对于离群点,应找出其行为异常的原因,对于错误的度量、不正确的数据记录、测量工具的错误等原因,应修正或删除离群点,但舍弃离群点之前应当有强有力的非统计证据证明离群点是错误值;如果离群点是异常但合乎实际情况的产物,剔除这些点以改善模型质量
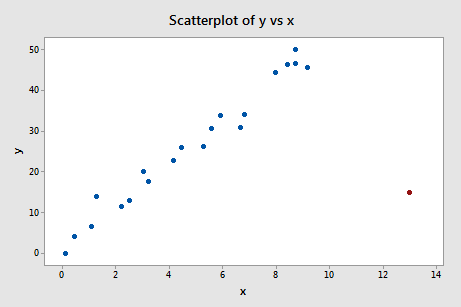
上图中的红色点,x值取值在正常范围内,接近X空间均值,但Y值远离相似X分布对应的Y分布均值;因此该点是离群点。 上图中红色实线表示包含红点值拟合的模型趋势线;红色虚线表示不包含红点值拟合的模型趋势线;虽然去掉该点后拟合的模型变化不算明显,但该点处的残差较大,明显大于其他点对应的残差。 3.强影响点强影响点指对模型的系数有显著影响的点,若该点被被单独删除或与其他几个点被一起删除,会导致拟合模型的实质性变化,如系数估计值、拟合值、t检验值等,则该点为强影响点;强影响点通常是一个数据集的少数点,但却对模型的系数与性质施加了不成比例的影响,这对模型是一种不利的情况;因此要找出这些点,并对这些强影响点对模型的影响进行评定;如果这些强影响点的值是错误的或有问题的,那应当将其从样本中清除,但如果其并不存在错误,但他们对模型最终使用结果影响较大,仍然需要了解这些点。
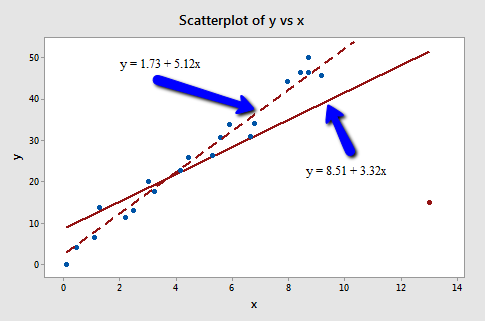
上图中的红点,离其他自变量的值较远,因此是高杠杆点;它离回归线也很远(残差大),因此该红点也是离群点。
虚线和实线分别是包含红点在内和不包含红点在内训练出来的回归模型。可以看到,两条回归线之间相差较大,因此,该点是强影响点。 注意: 强影响点要么是离群点、要么是高杠杆点、要么二者都有 二 检测方法上面的图例是简单线性回归,在实际应用中,通常有多个自变量,因此在高维空间中,我们不可能通过画图来判断某个观测值是否是异常点或高杠杆点或强影响点。我们可以通过其他的统计指标来进行检测。 1.高杠杆点检测 第i个观测的杠杆值 杠杆值的计算方式如下: 计算杠杆值的Python脚本: #coding:utf-8 import pandas as pd import numpy as np from statsmodels.formula.api import ols import matplotlib.pyplot as plt #1.计算杠杆值 def pii(variables,data): """ variables:str,例 "y ~ x1 + x2 + x3" ,其中y是标签列的列名,x1~xn是自变量列的列名 data:dataframe,数据集,其中包含自变量和因变量 hat:ndarray,1D,长度与data长度相同,每个元素对应每个样本的杠杆值 """ model= ols(formula=variables, data=data).fit() #回归模型 outlier = model.get_influence() #异常值检测 hat = outlier.hat_matrix_diag #计算杠杆值 return hat #2.绘制杠杆值散点图 def plot_pii(hat): """ hat:ndarray,1D,长度与data长度相同,每个元素对应每个样本的杠杆值 """ hat_2mean = [np.mean(hat)]*len(hat) #定义杠杆值的2倍均值 x = np.array(range(0,len(hat),1)) #定义散点图x轴序号 #画杠杆值图 plt.ylabel('hat values') plt.scatter(x, hat) plt.scatter(x, hat_2mean) plt.show() 2.离群点检测 正如前文中提到过的,离群点可以直接通过标准化残差的绝对值进行判断,通常尺度化残差的绝对值大于2或3即可认为该样本点为离群点;常用的尺度化残差有‘标准化残差’和“学生化残差”,相对于普通残差来说,尺度化消除了量纲的影响,学生化残差相对于标准化残差,还去除了高杠杆值的影响。计算方式如下: 标准化残差计算方式: 其中 学生化残差计算方式:
识别离群点的Python脚本: #coding:utf-8 import pandas as pd import numpy as np from statsmodels.formula.api import ols import matplotlib.pyplot as plt #1.计算学生化残差 def outlier(variables,data): """ variables:str,例 "y ~ x1 + x2 + x3" ,其中y是标签列的列名,x1~xn是自变量列的列名 data:dataframe,数据集,其中包含自变量和因变量 stu_r:ndarray,1D,长度与data长度相同,每个元素对应每个样本的学生化残差 """ model= ols(formula=variables, data=data).fit() #回归模型 outcheck = model.get_influence() #异常值检测 stu_r = outcheck.resid_studentized_external #内学生化残差 # stu_r = outcheck.resid_studentized_internal #外学生化残差 return stu_r #2.绘制学生化残差散点图 def plot_outlier(stu_r): """ hat:ndarray,1D,长度与data长度相同,每个元素对应每个样本的学生化残差 """ up_line = [2]*len(stu_r) #定义上限为2 down_line = [-2]*len(stu_r) #定义下限为-2 x = np.array(range(0,len(stu_r),1)) #定义散点图x轴序号 #画学生化残差散点图 plt.ylabel('hat values') plt.scatter(x, stu_r) plt.scatter(x,up_line) plt.scatter(x,down_line) plt.show() 3.强影响点检测强影响点的考察,综合考虑X空间中点的位置和强影响时的响应变量这两者;有以下二种常用的检测方法: Cook距离(Cook's D):Cook距离度量的是用全部数据和去掉第i个观测后的数据得到的回归系数(或拟合值)的估计之间的差异,通常Cook值与影响程度成正比,值越大越有可能是强影响点,如果 Di 大于 1,那么第i个观测值很可能就是强影响点;如果 Di 小于 0.5,那么第i个观测值不是强影响点;如果 Di 大于 0.5,需要对其进行进一步查看。其计算方式如下: 通常 Dffits:是一个与Cook距离类似的度量工具,其分别用全部数据和去掉第i个观测后的数据得到的拟合值之间的差异,在经过规范化后得到的;和Cook距离没有优劣之分,给的结果也是相似的,因此不展开讨论。 识别强影响点的Python脚本: #coding:utf-8 import pandas as pd import numpy as np from statsmodels.formula.api import ols import matplotlib.pyplot as plt #1.计算Cook距离 def cook(variables,data): """ variables:str,例 "y ~ x1 + x2 + x3" ,其中y是标签列的列名,x1~xn是自变量列的列名 data:dataframe,数据集,其中包含自变量和因变量 cooks:ndarray,1D,长度与data长度相同,每个元素对应每个样本的Cook距离 """ model= ols(formula=variables, data=data).fit() #回归模型 outcheck = model.get_influence() #异常值检测 cooks = outcheck.cooks_distance #cook距离 print("cooks:",cooks[0]) return cooks[0] #2.绘制Cook距离散点图 def plot_cook(cooks): """ cooks:ndarray,1D,长度与data长度相同,每个元素对应每个样本的Cook值 """ line_0p5 = [0.5]*len(cooks) #0.5节点 line_1 = [1]*len(cooks) #1节点 x = np.array(range(0,len(cooks),1)) #定义散点图x轴序号 #画Cook值散点图 plt.ylabel('hat values') plt.scatter(x, cooks) plt.scatter(x,line_0p5) plt.scatter(x,line_1) plt.show() 三 如何处理离群点、高杠杆点和强影响点对于离群点、高杠杆点和强影响点,我们应仔细检查其准确性(是否存在过失误差、抄录错误)、关联性(是否属于该数据集)、以及特殊含义(异常条件、独特状况);如果是高杠杆点但不是强影响点,一般不会引起什么问题,如果既是高杠杆点又是强影响点,应做进一步的研究;我们应该检查清楚它们为什么离群或具有强影响。基于这些检查,才能采取适当的,正确的措施,包括: 1.纠正错误数据 2.删除异常点 3.降低异常点的权重 4.变换数据 5.考虑不同的模型 6.重新设计实验或抽样 7.收集更多数据 参考文献:1.在统计学中,异常值,杠杆点,离群点,影响点有什么区别?又如何判断?在统计学中,异常值,杠杆点,离群点,影响点有什么区别?又如何判断? - 申请方 2.异常点VS高杠杆点VS强影响点(Outlier ,High Leverage Point,Influential Point)https://my.oschina.net/u/4397001/blog/3421364 3 《例解回归分析》(原书第五版)(美)Samprit Chatterjee Ali S.Hadi 著 4 《线性回归分析导论》(原书第五版)(美)Douglas C.Montgomery Elizabeth A.Peck G.Geoffrey Vining 著 |


【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |