python爬虫抓取微信公众号文章(含全文图以及点赞数、在看数、阅读数) |
您所在的位置:网站首页 › 名医汇在线微信公众号 › python爬虫抓取微信公众号文章(含全文图以及点赞数、在看数、阅读数) |
python爬虫抓取微信公众号文章(含全文图以及点赞数、在看数、阅读数)
|
因工作需要写了一个微信公众号文章的爬虫程序,贴一下分享给需要的朋友。 首先是抓取文章的url链接,在反复研究之后找到的一个最简单的方法,不需要抓包工具。首先需要自己注册一个微信公众号,有微信即可绑定注册,很简单。打开浏览器搜索‘微信公众号’,按流程注册登录。注册完之后如图:
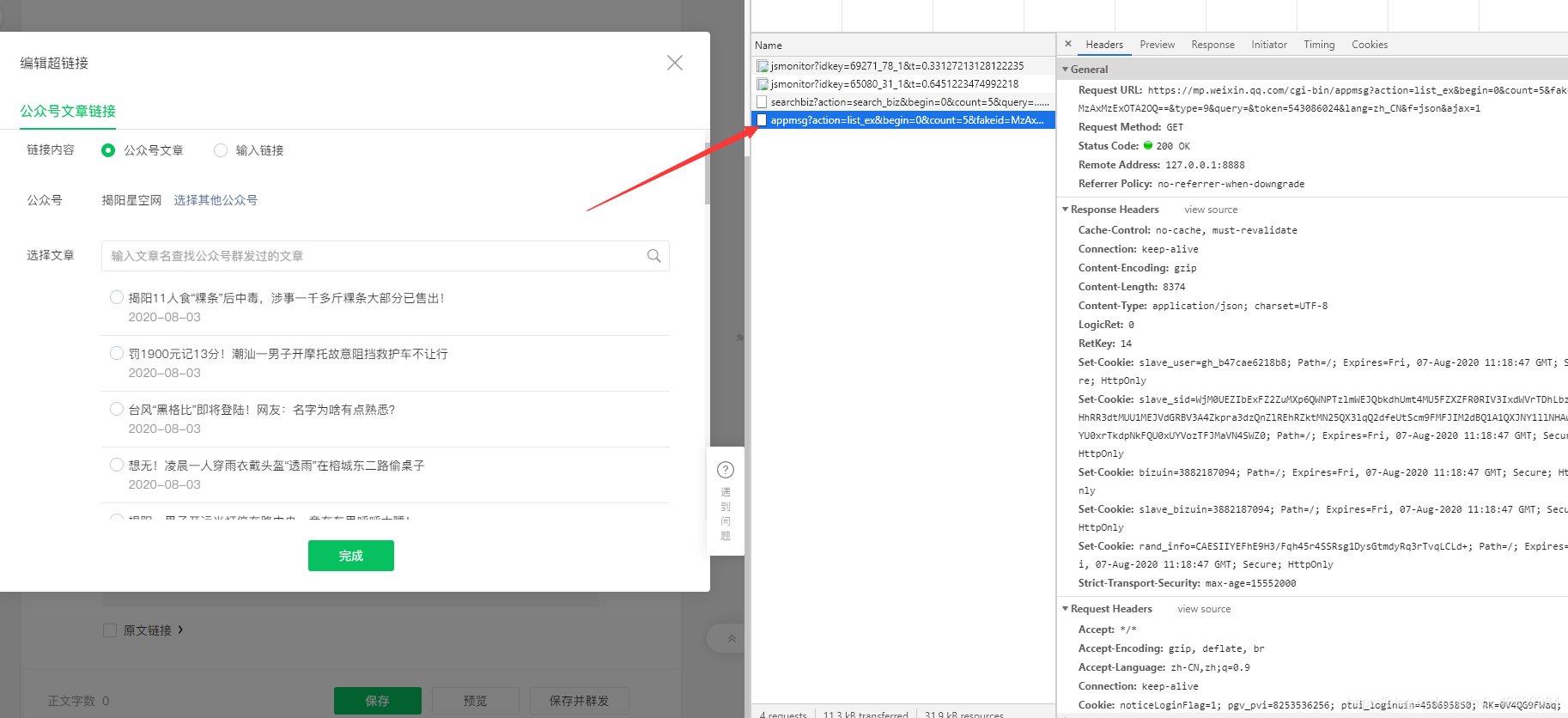
点击左下角‘素材管理’,然后‘新建图文消息’。再在新打开的页面里,最上方找到‘超链接’选项,点击。
在弹出的框中点击‘选择其他公众号’,然后就是输入你要爬取的公众号名称。 好了,到这里傻瓜式进程结束!正式进入爬虫阶段。。。
这里以‘揭阳星空网’公众号为例,这也是公司要求抓取的公众号之一。左边显示的就是公众号最新发布的一些文章,右边箭头指的就是这些文章相关的url,url、cookie、ua这些就不说了,懂一点爬虫的都应该懂。
点开preview,这是一个json格式的url,在这里就能找到我们需要的数据,包括标题,链接,封面图面以及发布时间。(发布时间是时间戳,要转换为常见时间格式。) emmmm。。然后开始码,先获取此页所有的url和标题
只做演示所以就只抓这一页的数据,如果要抓多页只需要修改url里的begin参数,begin=0是第一页,begin=5是第二页,以此类推!!!
我们随手打开一篇文章,大家如果有去研究就可以发现,不管是什么公众号什么文章,内容都是放在这个id=‘js_content’的div标签里的,因此我们只需要拿到这里面的内容就可以获取所有的文本和图片。(在这里扩展一下,有些文章里包含视频文件,视频文件大致分为两种,一种是腾讯视频的外部链接,一种应该是小编自行上传的视频文件。如果是自行上传的文件在这个页面也是可以拿到的,但是如果是腾讯视频的链接就是拿不到的,需要做另外处理!这个写不写看后面吧!!) 拿到所有的文章url之后就可以进行遍历获取响应了。
这里的title用了比较多的replace替换,原因在于这个title后面要作为输出word文件的标题,而标题是没办法包含这些特殊字符的,如果不替换掉会报错到令你崩溃。别问一定要这么写吗?反正我是只想到这个方法,一个一个替换!有更好的方法欢迎补充! 这里Document()是第三方库docx的方法,用来做word文档写入操作的。add_heading就是写入标题啦!
代码有点乱,将就看吧!还没时间整理 这里我用的是bs4获取,主要是因为bs4有一个比xpath,re都有优势的地方,那就是可以拿到子节点进行遍历。在拿到js_content的标签之后,就可以直接用soup.children遍历soup的子节点。对bs4不了解的自行百度吧!然后就是一个一个节点去循环遍历了,一般公众号的文字都是放在p标签里,有少部分会放在section标签里,所以是要判断if child.p or child.section,如果存在该标签,那么就current.add_paragraph(text=child.text),把文本写入word文档,再判断是否存在img标签,存在就匹配出img的url,进行下载,然后就是current.add_picture(pic)写入图片。视频没办法放入word,只能另外处理,还有一些表格啥的也是一样处理方法。遍历完之后就是current.save(你的存储位置)
写入完成效果是这样的
打开是这样的
虽然也保存了样式,不过放入word文档并不美观就是了。还做了去广告处理,这里没贴出来,有朋友需要再贴,反正思路就是找到特殊性。 原本以为到这里就结束了,没想到后面产品经理找我说,还要采文章的点赞数,在看数,阅读数。心里一万头草拟马在奔腾。然后默默回了一句‘好’。 然而在微信公众号平台打开的文章并没有这些参数,无奈只能在微信端试试看了,PC端微信文章打开是有这些数据的,但拿不到相关的参数,只能用抓包工具了,打开fidder,设置只抓微信的包。然后PC端打开一篇文章,在抓到的url里挨个点击寻找。然后。。。然后就找到了! 这里其实挺操蛋的,因为直接拿这里面的url去发送请求是拿不到数据的,这是一个post请求,也就意味着有一些data参数必须要传递上,多次尝试之后,直接贴代码!
没错,这些都是必须要携带的参数,大部分参数都是固定不变的,只有pass_ticket,appmsg_token,key这三个是变化的,因此每次请求可能都要手动更换这三个参数,最操蛋的就是key,基本上是二三十分钟更换一次,如果对数据采集量要求不大应该是足够用了。而且貌似破解不了(反正我破解不了,有大神请带带我)。带上这些必要参数就可以发送post请求拿到json格式的数据啦,然后就是转字典取值了,下面的代码就不贴了。搞完入库!
2020.08.18最新优化全代码,亲测可用!(参数自行输入) import json import re import time import pymysql import requests from lxml import etree import urllib3 urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) class Gzh_wz(object): def __init__(self): self.conn = pymysql.connect(xxx) self.cursor = self.conn.cursor() with open('标题.txt', 'r', encoding='utf-8')as r: titles = r.read().replace('\ufeff', '') self.title_l = titles.split('\n') self.cookie = input('cookie:') self.pass_ticket = input('pass_ticket:') self.url_dict = { '揭阳蓝城生活': 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=MzI0MTA2MDMwMA==&type=9&query=&token=abcd&lang=zh_CN&f=json&ajax=1', '揭东生活圈': 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=MzI0MzA1ODc0NQ==&type=9&query=&token=abcd&lang=zh_CN&f=json&ajax=1' } self.headers = { 'cookie': self.cookie, 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36', 'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&token=370616041&lang=zh_CN', } self.app_url = "http://mp.weixin.qq.com/mp/getappmsgext" phoneCookie = "rewardsn=; wxtokenkey=777; wxuin=1797234910; devicetype=Windows10x64; version=62090529; lang=zh_CN; pass_ticket=hjymD+nRjMwS6tz25jYr1rByJW9Yzu8L6Y+I6VDM8EK8bM7Ltcee1dTvMsr6A2I1; wap_sid2=CN7B/tgGElxnWXktSExLc0EyTVFVNGJMTjJ5eVhwSWNDQk5tRHhSd21NaGZNMUoxaWJRdzBlcUJxZG1XUEtuQ1JTekt4dXctS3hLaVFWU0xqdWQxNVJleFAxTGZ4akVFQUFBfjDi67T5BTgNQAE=" self.app_headers = { "Cookie": phoneCookie, "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.901.400 QQBrowser/9.0.2524.400" } self.data = { "is_only_read": "1", "is_temp_url": "0", "appmsg_type": "9", 'reward_uin_count': '0' } def get_link(self): for name, url in self.url_dict.items(): print(name) self.url = url.replace('abcd', '1897236457') res = requests.get(self.url, headers=self.headers, verify=False).text res_dict = json.loads(res) details = res_dict['app_msg_list'] self.appmsg_token = input('appmsg_token:') if self.appmsg_token == '1': continue self.key = input('key:') for detail in details: self.title = detail['title'] self.detail_url = detail['link'] self.get_response(detail) self.conn.close() def get_response(self, detail): self.detail_res = requests.get(self.detail_url, headers=self.headers, verify=False).text con = ''.join( re.findall(r' |













【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |