单目标追踪 |
您所在的位置:网站首页 › 台风定位精度指标包括什么 › 单目标追踪 |
单目标追踪
|
目录
评估指标精确度(Precision)归一化的精确度(Norm. Prec)成功率(Success Rate/IOU Rate/AOS)EAOF-score
评估方法OPE(One-Pass Evaluation)TRE(Temporal Robustness Evaluation)SRE(Spatial Robustness Evaluation)OPER(One-Pass Evaluation with Restart)虚拟运行策略
SRER(Spatial Robustness Evaluation with Restart)VOT的短时追踪VOT的长时追踪
评估指标
精确度(Precision)
来源——OTB2013 预测框中心点与Ground Truth框的中心点的欧氏距离,通常阈值为20像素。即它们的欧氏距离在20像素之内就视为追踪成功。
缺点: 没有考虑到目标的大小,导致小目标即使预测框与Ground Truth框相距较远,但它们的欧式距离仍在20像素内。 来源——TrackingNet 考虑到Ground Truth框的尺度大小,将Precision 进行归一化,得到Norm. Prec,它的取值在[0, 0.5] 之间。即判断预测框与Ground Truth框中心点的欧氏距离与Ground Truth框斜边的比例。
来源——OTB2013 成功率计算是计算预测框与Ground Truth的真值框的区域内像素的交并比,即红色框与蓝色斜边区域的比值。公式如上图的S。 通常我们会看到论文中有一个AUC(Area under curve)分数,这个分数实际上算的是成功率曲线下的面积,达成的效果就相当于考虑到了不同阈值下的成功率分数。有的论文也会直接指定阈值(如0.5)。其实当成功率曲线足够光滑,取0.5对应的成功率分数和计算成功率的AUC分数是一样的【中值定理】。
来源——VOT2015 EAO是VOT的对短时跟踪的综合评价指标,它可以反应准确性(A)和鲁棒性(R),但不是由准确性(A)和鲁棒性(R)直接计算得到的。这和它的评估方法紧密相关,因为它的评估方法会产生许多个子序列。 精度是跟踪失败前帧上的平均IOU,在所有子序列上取平均值。鲁棒性是成功跟踪的子序列帧的百分比,在所有子序列上取平均值。跟踪失败被定义为地面真实值和预测目标位置之间的重叠降低到0.1以下,并且至少10帧后没有增加到该值以上的帧。该定义允许在短时跟踪器中进行短时故障恢复。符号定义: Φ i \Phi_i Φi表示计算的平均每一帧的IOU值,包括失败的帧。公式定义: 来源——THE LONG-TERM DATASET (LTB50) F-分数是引入了机器学习里的查准率、查全率和F1度量来分析长期跟踪器的跟踪和检测能力。其中有一些概念需要理清,比如准确性(precision)和召回率(recall)的定义方法。(公式来袭) 符号定义: G t G_t Gt表示真值框的目标位置,如果目标消失,则 G t = ∅ G_t = \empty Gt=∅ A t ( τ θ ) A_t(\tau_\theta) At(τθ)表示追踪器输出的预测框的位置, θ t \theta_t θt表示在第 t t t帧的预测确定性得分。(追踪器输出的预测框的确定性得分——有多少的把握这就是目标)。 τ θ \tau_\theta τθ表示分类的阈值。如果第 t t t帧的得分小于阈值,即 θ t \theta_t θt < τ θ \tau_\theta τθ, 那么 A t ( τ θ ) = ∅ A_t(\tau_\theta) = \empty At(τθ)=∅。 Ω ( A t ( τ θ ) , G t ) \Omega(A_t(\tau_\theta),G_t) Ω(At(τθ),Gt)表示预测框的位置与真值框的目标位置的交集。 τ Ω \tau_\Omega τΩ表示精确度的阈值。公式定义如下: 准确度(precision): 召回率(recall):
N
g
N_g
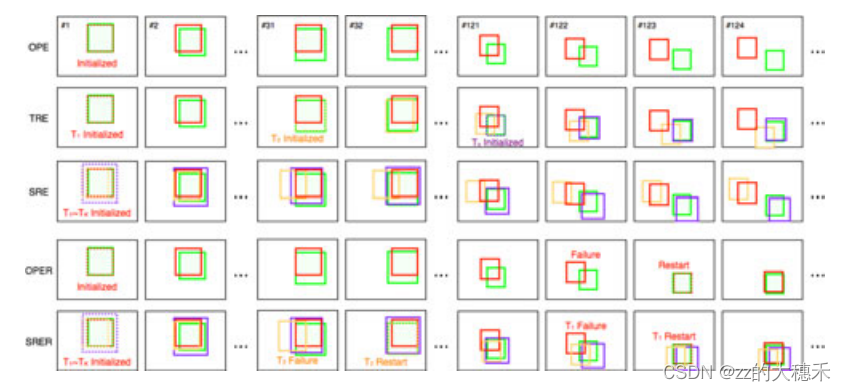
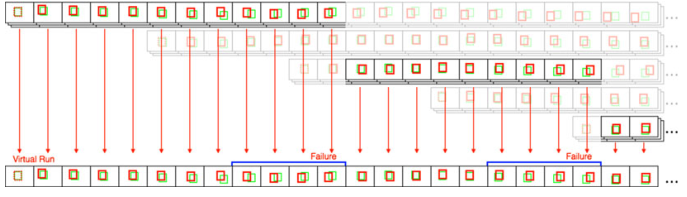
Ng是当Gound Truth集合不为空集的帧数和,即当某一帧的目标消失,就将这一帧的输出视为空集。所以这里的Re很像机器学习中的查全率。 F-分数(F-score):在实际的模型评估中,单用Precision或者Recall来评价模型是不完整的,评价模型时必须用Precision/Recall两个值。所以就有了F-分数。F-分数越大算法性能越好。所以vot在评估的时候摒弃了直接指定阈值的方式,对于不同的跟踪器,取它们F-分数最大的时候的准确度和召回率进行比较。 来源——OTB 评估指标: 精确度(Precision)、成功率(Success Rate) 评估算法: 在整个测试序列中运行跟踪器,给出第一帧的目标真值初始化追踪器。期间不再初始化。 TRE(Temporal Robustness Evaluation)来源——OTB 评估指标: 精确度(Precision)、成功率(Success Rate) 评估算法: 从时间上(即从不同帧开始)将序列划分为20段,在每个分段上评估跟踪器,分析跟踪器对初始化的鲁棒性。 出发点: 如果序列的早期部分更为重要,因为一次跟踪失败后的帧结果没有提供信息,TRE解决了这个问题。 SRE(Spatial Robustness Evaluation)来源——OTB 评估指标: 精确度(Precision)、成功率(Success Rate) 评估算法: 从空间上(从不同的初始框位置)分析跟踪器对初始化的鲁棒性。每个追踪器要在每个序列上运行12次,其中使用8个空间偏移(4个中心偏移和4个角偏移)+ 4个尺度变化(补充)。位移量为目标大小的10%,尺度比与地面真值的比例分别为0.8、0.9、1.1、1.2。 出发点: 在实践中,由于探测器或手动标记造成的错误,很难将目标准确框住。所以这个评价方法是为了评估跟踪方法是否对初始化错误敏感。 OPER(One-Pass Evaluation with Restart)来源——OTB2015 虚拟运行策略理想情况下,当故障发生时,应在帧处重新启动跟踪方法。然而,需要考虑一些潜在的问题。首先,为了分析跟踪器的行为,我们改变重叠阈值;因此,跟踪失败发生在不同的帧上。然而,对于TB-50或TB-100基准数据集的每个图像序列,评估具有不同阈值和参数(以及SRER中的空间扰动)的所有可能场景是不切实际的。其次,许多跟踪算法都是用二进制代码分发的,不可能检测到故障并在某些特定帧重新启动跟踪器。因此,我们使用虚拟运行来近似一组实际实验生成的特定参数设置。 评估指标: 精确度(Precision)、成功率(Success Rate)、故障总数(failure) 评估算法: 在整个测试序列中运行跟踪器,当追踪失败,就在下一帧使用相应的Gound-truth对追踪器进行重新初始化。平均重叠分数(Success Rate)和故障总数表明了跟踪算法的准确性和稳定性。这里有个超参数
ω
\omega
ω控制对瞬时故障的敏感性,即当
ω
\omega
ω帧失败(确定性分数低于阈值)才判定为故障。 来源——OTB2015 评估指标: 精确度(Precision)、成功率(Success Rate) 评估算法: 对于空间扰动
δ
\delta
δ,整个序列按照每隔
τ
\tau
τ帧生成一个个到整个序列结尾的子序列。追踪器在所有子序列上运行。这里也有个超参数
ω
\omega
ω控制对瞬时故障的敏感性,即当
ω
\omega
ω帧失败(确定性分数低于阈值)才判定为故障。 来源——VOT2021 评价指标: 精度(Accuracy)、鲁棒性(Robustness)、EAO(Expected Average Overlap) 评估方法: 要求在序列中的多个帧处初始化跟踪器,这些帧称为锚定点,间隔约50帧。跟踪器从序列前半部分的每个锚点向前运行,对于后半部分的锚点向后运行,直到第一帧。 VOT的长时追踪来源——VOT2021 【短时(ST)和长时(LT)跟踪器之间的一个主要区别是,需要LT跟踪器来处理目标可能离开视野更长时间的情况。这意味着LT跟踪器的自然评估协议是无重置协议。】 评估指标: 精度(Pr)【查准率】、召回率(Re)【查全率】、F-分数。 评估方法: 需要在序列的第一帧初始化跟踪器,并运行它直到序列结束。跟踪器需要报告每个帧中的目标位置,以及反映目标在该位置的确定性的分数。Pr、Re和F-分数的最终值是通过选择最大化跟踪器特定F-measure的确定性阈值来获得的。这避免了在主要性能度量中手动设置的所有阈值【那么对于每个追踪器它的取阈值的点就不一样了】。 接下来就是整理单目标的一些经典算法了~Fighting with CuteQiang |
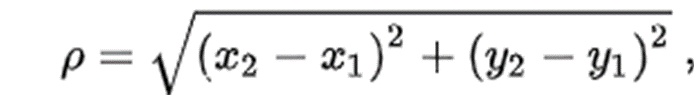

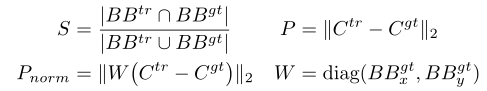

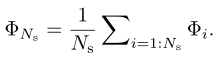 Φ
N
s
\Phi_{N_{s}}
ΦNs就是期望平均重叠(expected average overlap,EAO),即计算从第1帧到一个期望的极大值(
N
s
N_s
Ns)对应的
Φ
i
\Phi_i
Φi 求个平均,就是期望平均覆盖率。
Φ
N
s
\Phi_{N_{s}}
ΦNs就是期望平均重叠(expected average overlap,EAO),即计算从第1帧到一个期望的极大值(
N
s
N_s
Ns)对应的
Φ
i
\Phi_i
Φi 求个平均,就是期望平均覆盖率。 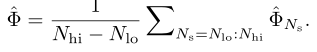 但是VOT中EAO计算并不是
N
s
=
1
:
N
m
a
x
N_s = 1 : N_{max}
Ns=1:Nmax,而是
N
s
=
N
l
o
w
:
N
h
i
g
h
N_s = N_{low} : N_{high}
Ns=Nlow:Nhigh。
Φ
^
\widehat{\Phi}
Φ
是期望平均重叠的度量(expected average overlap measure)追踪器在
N
s
=
N
l
o
w
:
N
h
i
g
h
N_s = N_{low} : N_{high}
Ns=Nlow:Nhigh上运行的平均EAO分数。
但是VOT中EAO计算并不是
N
s
=
1
:
N
m
a
x
N_s = 1 : N_{max}
Ns=1:Nmax,而是
N
s
=
N
l
o
w
:
N
h
i
g
h
N_s = N_{low} : N_{high}
Ns=Nlow:Nhigh。
Φ
^
\widehat{\Phi}
Φ
是期望平均重叠的度量(expected average overlap measure)追踪器在
N
s
=
N
l
o
w
:
N
h
i
g
h
N_s = N_{low} : N_{high}
Ns=Nlow:Nhigh上运行的平均EAO分数。 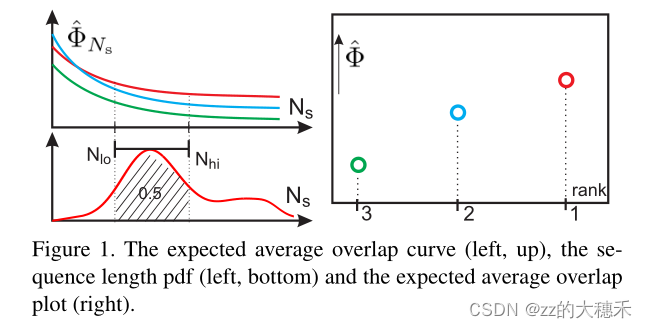
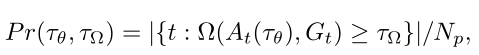 其中,
N
p
N_p
Np是当预测集合不为空集的帧数和,即当某一帧的追踪预测框的确定性分数(prediction certainty score)小于阈值,就将这一帧的输出视为空集。所以这里的Pr很像机器学习中的查准率。
其中,
N
p
N_p
Np是当预测集合不为空集的帧数和,即当某一帧的追踪预测框的确定性分数(prediction certainty score)小于阈值,就将这一帧的输出视为空集。所以这里的Pr很像机器学习中的查准率。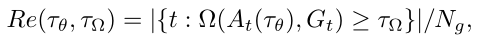
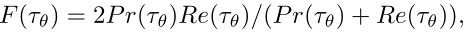
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |