十大经典排序算法【算法思想+图解+代码】【数据结构与算法笔记】 |
您所在的位置:网站首页 › 十大排序算法的比较方法 › 十大经典排序算法【算法思想+图解+代码】【数据结构与算法笔记】 |
十大经典排序算法【算法思想+图解+代码】【数据结构与算法笔记】
|
前言:文中大部分为本人收集整理,综合学习资料,个人理解……。希望能帮助你少掉些头发,早日走出理解的深渊。因为写作较为仓促文中内容难免会有纰漏,发现可评论区回复(无奖)。
排序(Sort)
分析排序算法的执行效率、内存消耗、稳定性(应对各种极端情况的时间空间复杂度波动) 有序度是数组中具有有序关系的元素对的个数 完全有序的数组的有序度叫满有序度,N*(N-1)/2 逆序度 = 满有序度 - 有序度 排序的过程就是一种增加有序度,减少逆序度的过程,最后达到满有序度,此时说明排序完成 排序是针对数据的排序,而常见数据的底层存储结构无非就是数组和链表,而这两种结构的排序实现虽然大同小异但各有各的优缺点。 补充:(和线性代数中的概念差不多) 满有序度:所有排列的个数 有序度:满足排序规则的排列个数 逆序度:未满足排序规则的排列个数 例: 有集合(5,6,9,0,2)可得以下有序排列 (5,6)、(5,9)、(5,0)、(5,2) (6,9)、(6,0)、(6,2) (9,0)、(9,2) (0,2) 以升序为排列规则得: 满有序度 = (n - 1)* n / 2 = (5 - 1) * 5 / 2 = 10 有序度 = 3 (红色标注部分) 逆有序度 = 10 - 3 = 7; 有序区、无序区:已经排序完成的部分就是有序区,还未排序的部分就是无序区。 十大经典排序算法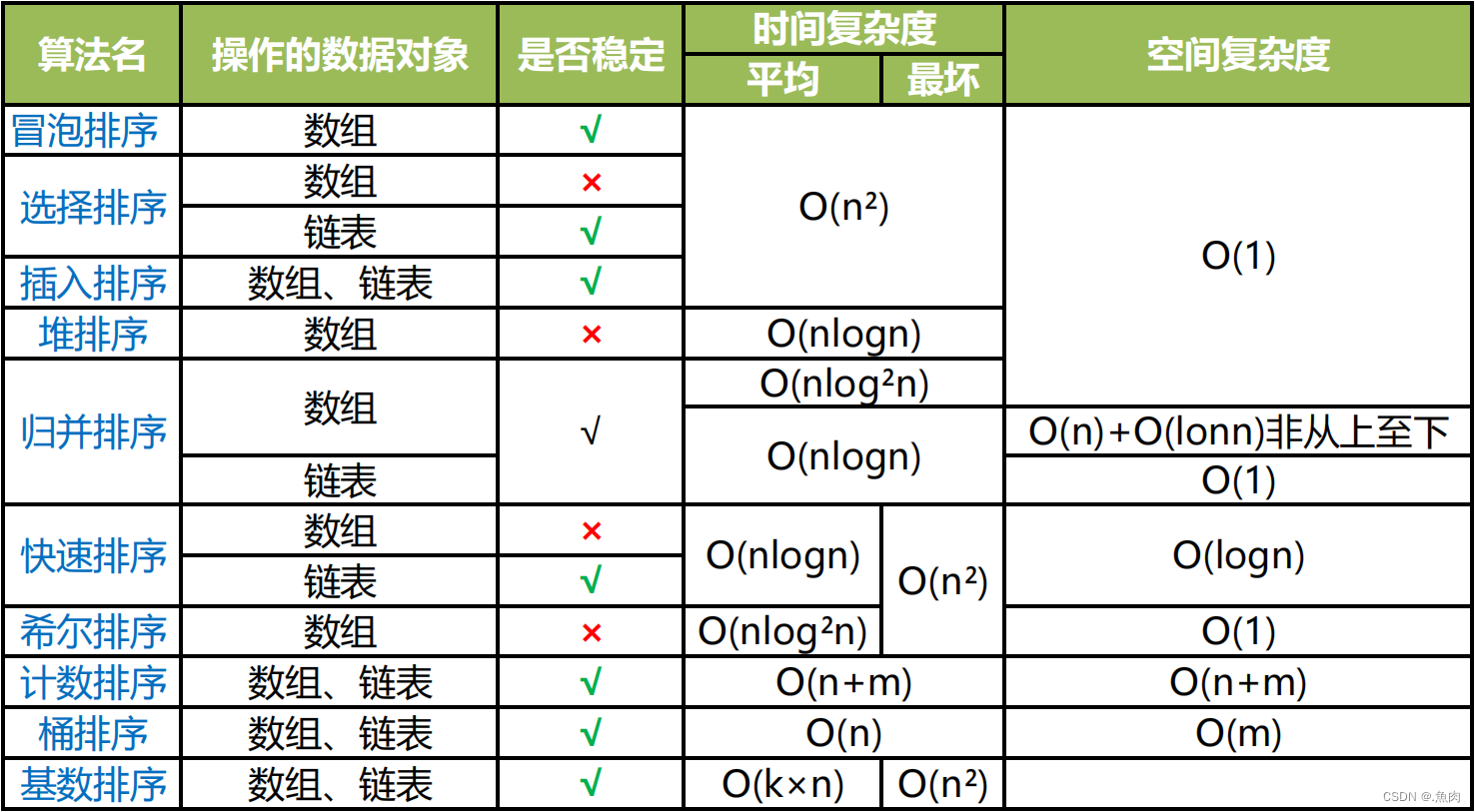 一、冒泡排序(Bubble Sort)
一、冒泡排序(Bubble Sort)
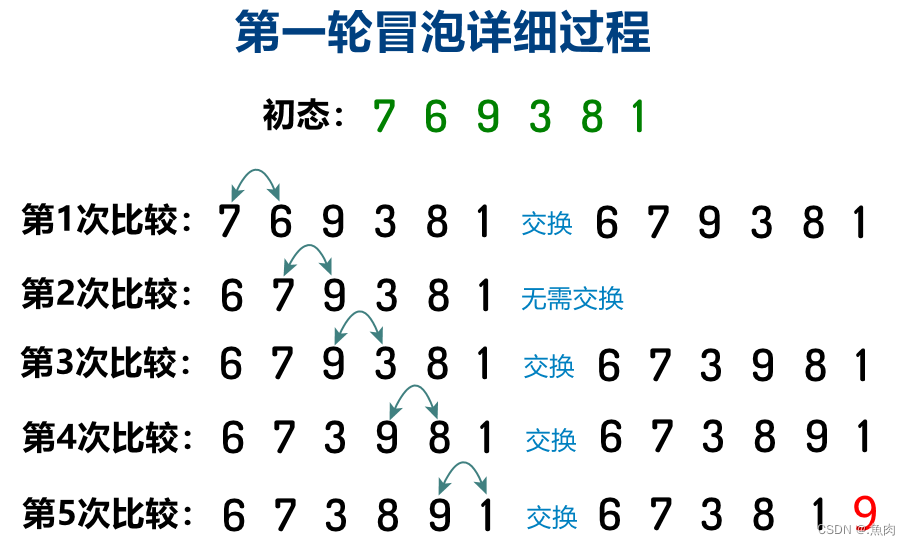
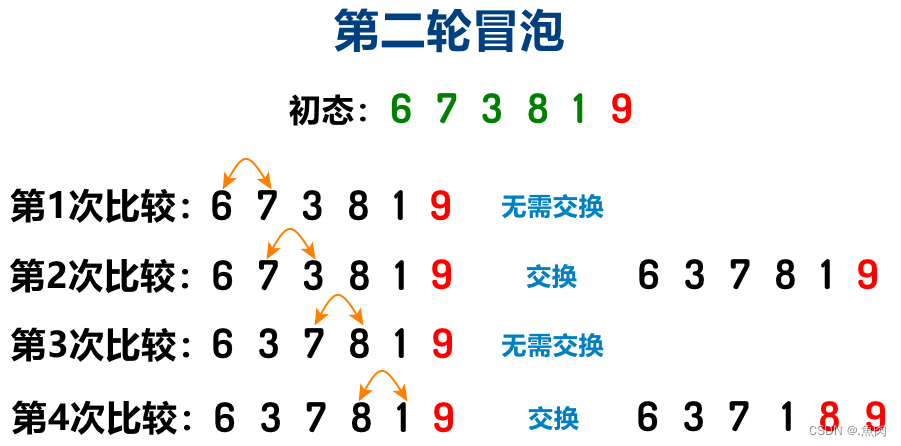
排序首先明确以何种规则排序(升序或降序,本文均默认采用了升序排列) 算法思想:一组待排序数中,每次从第一个数开始将其和其后的一个数进行比较,如果前数大则交换两数,交换后后挪一个位置继续比较,每次将最大数交换至相对靠后的位置上,往复比较直到这组数的倒数第一个和倒数第二个数比较、交换结束,至此第一轮结束,我们将最大的数已经放在了最后的位置上。接下来是第二轮,还是从第一个数开始俩俩比较、交换位置,不过这次的比较次数比第二轮会少一次(因这一轮中最后的一个数已经排序完成),同理再进行第三轮(这一轮又会比第三轮少比较一次,因为这一轮汇总最后两个数已经排序完成,无需让他们参与比较)、第四轮…… 排序终止条件就是总共比较了(n-1)+(n-2)+ …… + 1次。故其时间复杂度为O(n²)(默认均为最坏情况)。 算法图解:
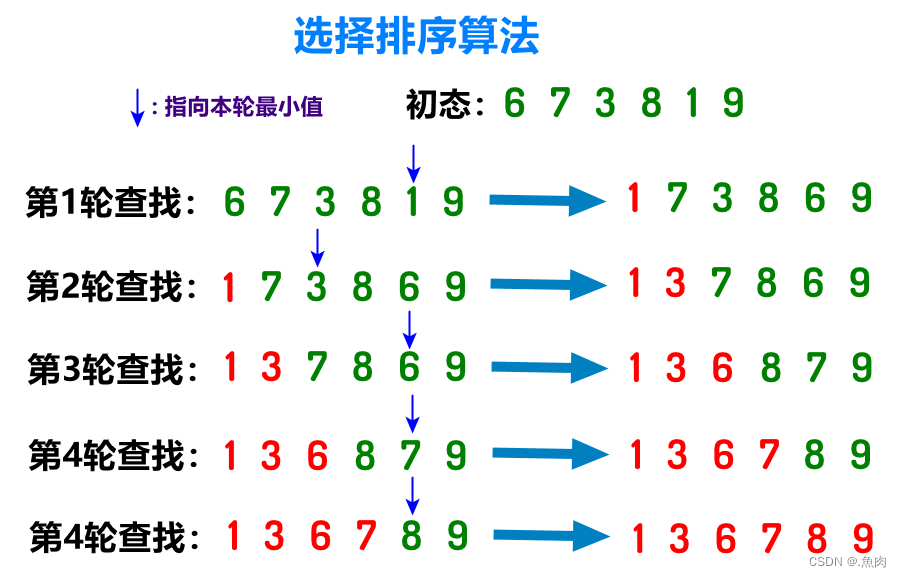
算法实现: void BubbleSort(int* arr, int arrLen) { //需要传入数组引用以及,数组长度 int i, j; for(i = 0; i < arrLen - 1; ++i) //控制比较的轮数 for(j = 0; j < arrLen - i - 1; ++j) //控制每轮比较次数 if(arr[j] > arr[j+1]) //根据比较结果决定是否交换 swap(arr, j, j+1); }注:算法的可运行程序附在文章结尾 二、选择排序(Selection Sort)算法思想:这个算法就是我们笔算排序用的算法。在一组数中找出最小的一个排在第一个位置,然后在剩下的数中找一个次小的排在第二位,再找剩下元素中第三小…….很简单吧。用计算机实现其实还略微有点不同,我们要在原来的位置上交换,而非重新创建一个数组。 先从头遍历整数组,必然能从中找出最小的一个(相同的找到第一个最小的就行),然后将其和原来第一个位置上的数进行交换,然后重新遍历数组。这次从 第二个位置上开始遍历(因为第一个位置上已经排序完成,第二个数之前都是有序区,其后是无序区,),再找出一个最小数,将其和第二个位置上的数交换。再重新重第三个数遍历,找出…… 直到我们将要从倒数第一个数遍历时排序也就结束了。 算法图解:
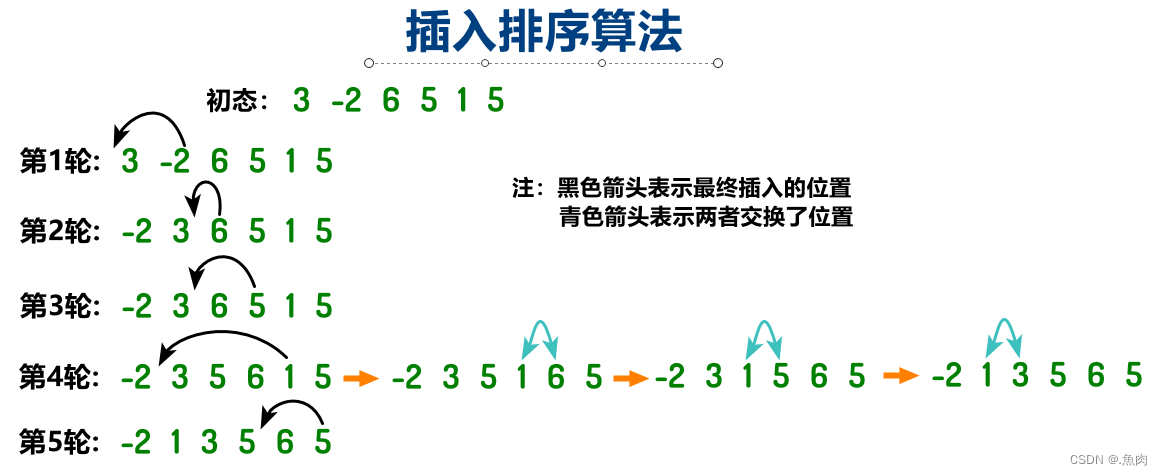
算法实现: void SelectionSort(int* arr,int arrLen) { int i, j; int minElemIndex; //存每一轮最小元素索引 for(i = 0; i < arrLen; ++i) { minElemIndex = i; for(j = i + 1; j < arrLen; ++j) //在本轮中找出最小元素 if(arr[j] < arr[minElemIndex] ) minElemIndex = j; //更新最小元素索引值 if(i != minElemIndex) //是否有必要交换 swap(arr, i, minElemIndex); //将本轮最小元素与对应位置上的元素交换 } } 三、插入排序(Insertion Sort)算法思想:将原来待排序的数组划分成两个区域,即无序区和有序区,有序区开始只包含第一个元素,其右侧剩下的元素均处于无序区。每次对无序区第一个元素进行排序,即将无序区第一个元素和有序区最后一个元素比较(由后向前比较),如果比较过程中出现两者比较后需要交换位置则交换其位置,然后向前移一位继续俩俩比较,直到前面没有可以比较元素则停止,排序结束;或者出现某次比较后无需交换,则此时停止比较,排序结束。以上是一轮排序结束,每一轮结束都可以将无序区中的第一个元素排好序,然后无序区减少一个元素,有序区增加了一个元素,接着只需要用 同样的方法将屈无序区中的全部元素都排序即可。 算法图解:
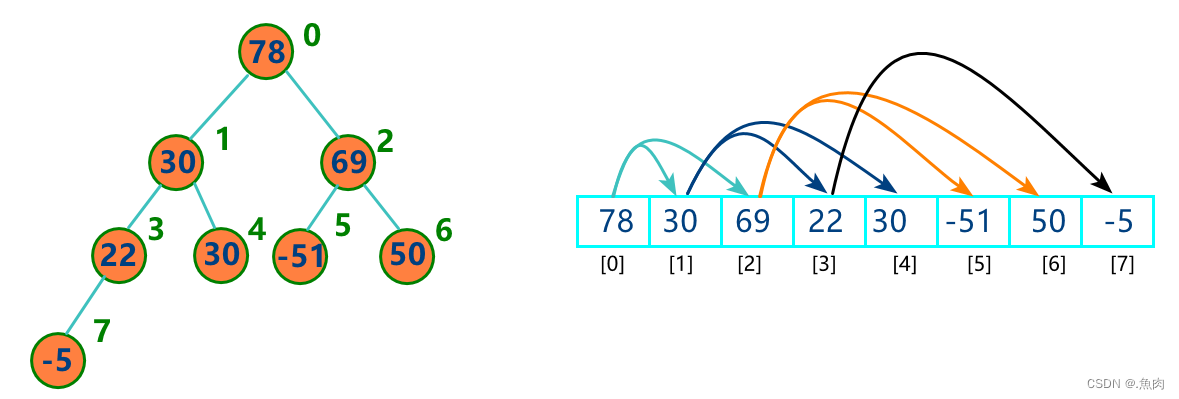
算法实现: void InsertionSort(int arr[], int arrLen) { int i, j; for (i = 1; i < arrLen; ++i) for (j = i; j > 0; --j) // 从第二个位置开始判断,每次前移一位继续比较 if (arr[j] < arr[j - 1]) //相邻的俩俩比较 swap(arr, j, j - 1); else break; } 四、堆排序(Heap Sort)堆(Heap): 堆是一种完全二叉树 特性:堆中每个节点的值都不小于(或不大于)其子树中任何节点的值 分类:大顶堆(上大下小)、小顶堆(上小下大)。除此之外的堆是“不成熟”的堆,即还在堆化的路上 堆化:顺着节点所在路径,向下或向上比较,然后交换节点 堆的数组存储形式:
算法思想:首先将n个元素的数组构造成一个大顶堆,然后将堆顶元素(0号元素)与最后一个元素交换,这样就将最大值放在了数组最后(n-1的位置),然后把数组长度减1,再将这n-1长度的数组重新构造成大顶堆,再把堆顶元素与新长度的数组最后的元素进行交换(n-2的位置)元素交换位置,如此往复最后就能将原数组从后向前的排序完成。其难点是堆的重构部分。 算法图解:(制作粗糙,但关键在于理解)
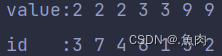
算法实现: //堆化:构建大顶堆 void ShiftDown(int *arr, int heapSize, int k) { while (2 * k + 1 < heapSize) { // 在 k节点的所有子元素中执行一下步骤 int i = 2 * k + 1; // i为k的左孩子 if (i + 1 < heapSize && (arr[i + 1] > arr[i])) // 如果其右孩子在需排序的长度范围内,且左孩子小于右孩子 i += 1; //该节点遍历结束, if (arr[k] >= arr[i]) //当k结点大于该节点终止循环 break; swap(arr, k, i); //不符合堆定义,交换元素位置 k = i; //更新节点交换后的位置 } } void HeadSort(int *arr, int arrLen) { int i; for (i = (arrLen - 1) / 2; i >= 0; --i) ShiftDown(arr, arrLen, i); // 建立初始堆 for (i = arrLen - 1; i > 0; --i) { swap(arr, 0, i); //交换首尾元素,第i次排序完成 ShiftDown(arr, i, 0); // 重构堆(i记录了上次发生交换的结点) } }堆排序是一种不稳定的排序算法。那什么是排序算法的稳定性? 假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。 例:[1,6,3,4,6,5,4]经过排序算法后结果是[1,3,4,4,5,6,6],两个4和两个6的相对位置都没有发生改变,则这样的排序算法就是稳定的。还是上面的算法稍加修改代码就可以验证堆排序是不稳定的:
算法思想: 归并排序采用了分治法(典型有汉诺塔问题,想了解可戳:点我看视频讲解)。首先将待排序的数组拆分成两数组,两个拆四个,直到最后每个数组都只由一个元素组成的(这样的每个数组都是有序的),然后俩俩“合并”,此合并非彼合并,我们仍需遍历两个数组,在这两个数组中的几个元素中重新排序(这个重新排序的结果需要临时保存在大小合适的新数组中),不过因为原来两个数组都是有序的,所以当我们操作完其中一个数组的全部元素后,如果另一个数组还有剩余的元素,直接将它们放在后面即可。俩俩合并最终我们得到了排序好的数组。将一个数组排序的事分成两个数组排序,而这两个数组各自又想分成俩个数组……直到最后数组只剩下一个元素(这个数组天然是有序的),这样再由下向上回归。简而言之就是同样的方法套娃,直到最后可以被很容易的解决。好一个釜底抽薪! 算法图解:
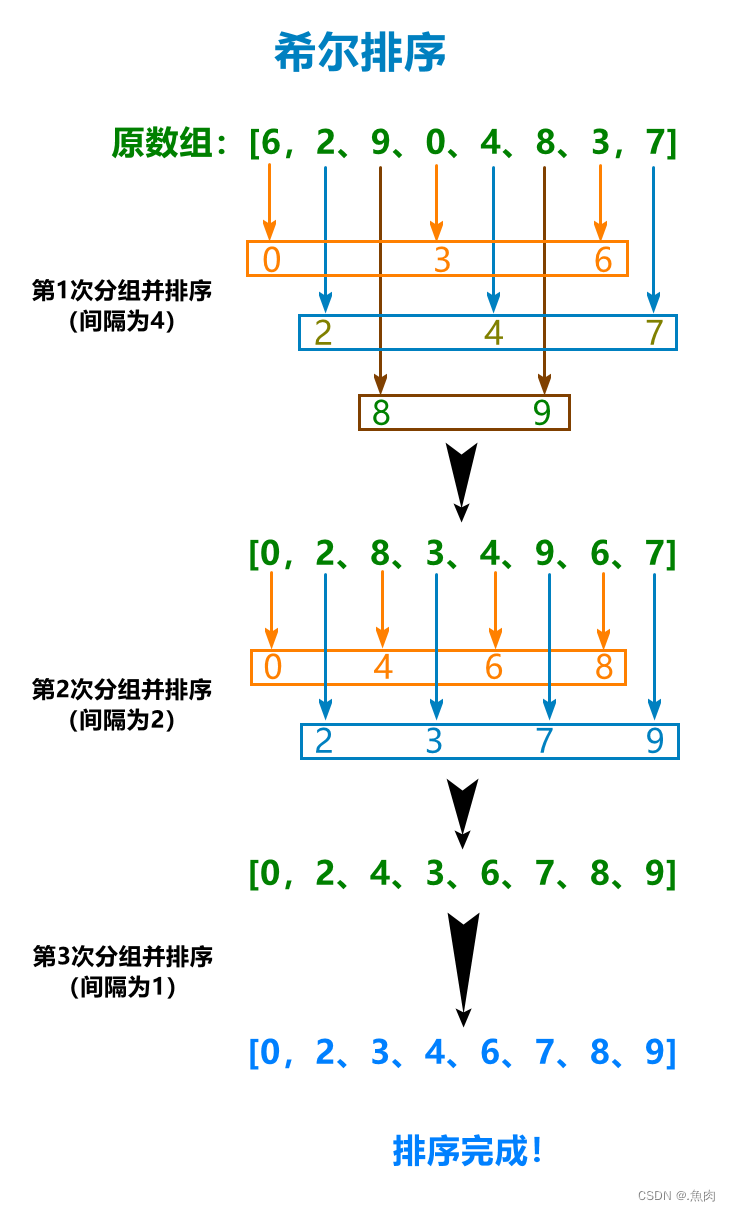
算法实现: int Merge(int *arr, int left, int mid, int right) { int i = left, j = mid, index = 0; int *temp = (int *) malloc(sizeof(int) * (right - left)); // 创建辅助数组 while (i < mid && j < right) temp[index++] = arr[i] < arr[j] ? arr[i++] : arr[j++]; // 比较大小,将较小元素并入辅助数组 while (i < mid) //并入左侧数组剩余元素 temp[index++] = arr[i++]; while (j < right) //并入右侧数组剩余元素 temp[index++] = arr[j++]; for (i = 0; i < index; ++i) //辅助数组数据写回原数组(重要) arr[left + i] = temp[i]; free(temp); // 释放辅助数组内存空间 } void MergeSort(int *arr, int left, int right) { // 1.递归拆分原数组 if (right - left = right) //参数校验 return; int index = Partition(arr, left, right); //获取新分区节点的位置(索引) QuickSort(arr, left, index - 1); //左分区 QuickSort(arr, index + 1, right); //右分区 }随机优化快速排序: int Partition(int *arr, int left, int right) { swap(arr, right, rand() % (right - left) + left); // =====随机选取基准值===== int pivot = arr[right], i = left; for (int j = left; j < right; ++j) { if (arr[j] < pivot) { if (i != j) swap(arr, i, j); i++; } } swap(arr, i, right); return i; } void QuickSort(int *arr, int left, int right) { if (left >= right) return; int index = Partition(arr, left, right); QuickSort(arr, left, index - 1); QuickSort(arr, index + 1, right); } 七、希尔排序(Shell Sort)算法思想:希尔排序其实是插入排序的改版。首先我们将数组按照一定的间隔分组,比如长度为8的数组我们第一次设置的间隔就为4(一般为数组长度的一半,即同一组数中间间隔4-1个数),这样就就分成了[0],[4],[8](表示下标)、[1][5]、[2][6]、[3][7]四组,然后这四组单独排序(使用的是插入排序),排序完成后我们重新设置间隔设为2(减半),采取同样的方法,再次分组、排序。直到最后分组间隔为1,再最后一次排序之后就完成整个数组的排序工作了(可能你有疑问:既然最后间隔是1,不就是整体排序吗,那前面那么多次排序何必?其实不然,如果你稍微去研究一下插入排序的具体步骤,你就会发现它在数组相对有序是,性能是很不错的,所以前面的多次排序其实都是为了最后一步而铺垫的)。 算法图解:
算法实现: void ShellSort(int *arr, int arrLen) { int i, j, group; for (group = arrLen / 2; group > 0; group /= 2) { //分组 for (i = group; i < arrLen; ++i) { //排序遍历从分组间隔数开始(不会取到 int temp = arr[i]; for (j = i; j >= group && temp < arr[j - group]; j -= group) //组内排序 arr[j] = arr[j - group]; //就是在前面找到了一个合适的位置交换了元素,像不像插入排序?? arr[j] = temp; } } } 八、桶排序(Bucket Sort)算法思想:是一种解决大文件排序的方法。将数据根据大小范围分到不同的“桶”中,再对每个桶排序,最后依次倒出桶中的元素就是有序的了。应用前提:排序的数据容易划分到m个桶中,各个桶内的数据量相差不大。对用于对大文件的排序,你很清楚的直到计算机需要操作的数据都是需要先加载到内存,现在的内存也就十几、几十个G,如果要排序的文件大小远超内存大小那么如何排序呢?桶排序,先将数据分成几桶,然后依次加载每桶的数据进行排序,这样就可以把整个大文件进行排序。 算法图解:
算法实现: 比较简单,此处略。 九、计数排序(Counting Sort)算法思想:我们直到数组的通过索引访问是很快的,那么我们就利用这一个特点,比较要排序的数字和和下标都是数字,创建一个长度为数组中最大值+1的新数组,先初始化每一个元素,将其赋0,然后遍历待排序数组,将其对应下标的元素值+1,这样一直将每一个数出现的次数都统计好。因为下标是天然有序的,然后我们从头到尾访问这个统计数字出现次数的数组,将其下标对应的数输出小标对应元素值那么多次,至此排序完成。该算法有一个明显的缺点,处理离散数据时占用空间大,还有就是“没办法对负数排序”,毕竟下标都是自然数,办法总比困难多,我们只需再求出原数组的最小值(负数。正数也行,解决最小值与0相差较大的正数数组排序),将其设置为一个偏移量。例如最小值为-8,设置其偏移量为8,即所有数在统计前先+8,这样就能让统计结果全部落在自然数范围内(当然开辟统计数组的大小就不是用最大值了,而是最大值最小值两者绝对值之和)。 算法图解:
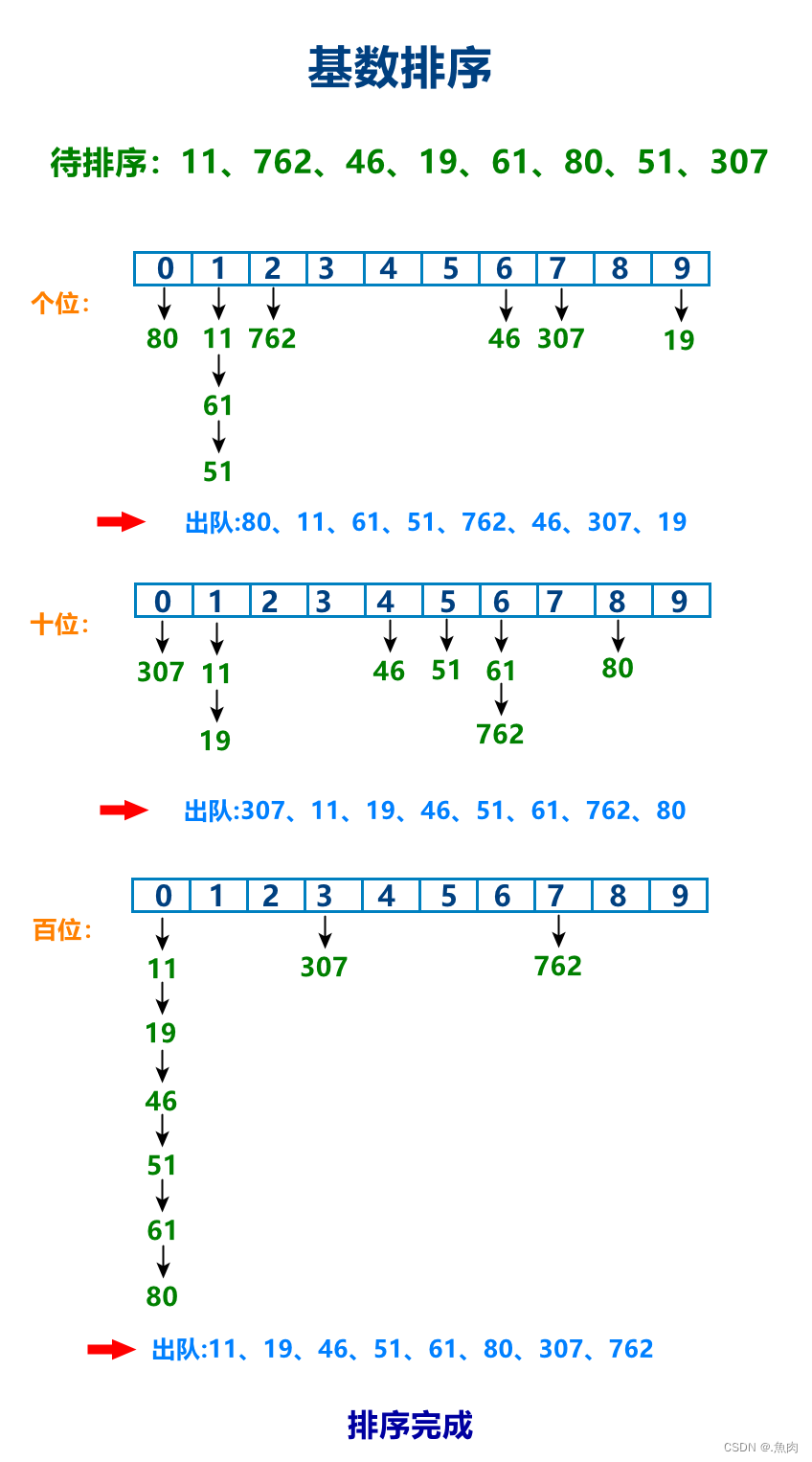
算法实现: void CountingSort(int *arr, int arrLen) { int length = GetMax(arr, arrLen) + 1, i, j, k; int *counting = (int *) malloc(sizeof(int) * length); //开辟一个长度为最大值+1的数组 for (i = 0; i < arrLen; ++i) //数组初始化 counting[i] = 0; for (i = 0; i < arrLen; ++i) //开始计数 counting[arr[i]]++; for (i = 0, j = 0; j < length; ++j) { if (counting[j] != 0) for (k = 0; k < counting[j]; ++k) //安装counting计数结果重新将数据写回数组(即排序) arr[i++] = j; } free(counting); } 十、基数排序(Radix Sort)算法思想:不管多大多小的数,都是由0~9这十个基本数字组成的,不同的数只是位数不同或同一位(权值)上的基数不同。借此,我们先从每个数的最低位(如个位)开始比较,将它们分类(借助队列),然后依次取出再比较上一位(如十位),还是同样的方法,直到最后所有数最高位均为0时排序结束。 为什么从低位到高位比较? 权值,基数的排列顺序构成了不同的数,越低位其权值越低,影响越小。所以从低位开始排,然后到高位时显然很可能会打乱前一步排序结果,但因为其权值高影响大,所以实际不会影响最终结果。例如86、49,先从高位排,8>4,所以结果为49、86,然后排低位,9>6,所以结果为49、86,显然很荒唐。 想排负数,行,同样设置偏移量,每个数都加上最小负数的绝对值,然后当做正数排就好。 算法图解:
算法实现: /*基数排序*/ void RadixSort(int *arr, int arrLen) { int flag, k, weight, radix, i; int *temp = (int *) malloc(sizeof(int) * arrLen); //这里是直接把双重队列用一个数组代替 // 从低位到高位,weight表示权值 for (weight = 1;; weight *= 10) { //radix就是9个基数,每次按顺序取一个基数 for (radix = 0, k = 0; radix < 10; ++radix) { //遍历待排序数组,寻找特定位数上基数匹配的数 for (i = 0, flag = 0; i < arrLen; ++i) { if (arr[i] / weight % 10 == radix) //取出该数指定位置上的数与本轮拿到的基数比较 temp[k++] = arr[i]; //匹配后将该数写入所谓的双重队列数组(不同权值时temp数组刷新,重新写) if (arr[i] / weight % 10 == 0) { //记录每次发生该位上的数字为0的次数 ++flag; if (flag == arrLen) { //如果出现的次数等于数组长度,上次已经比较完了最高位 free(temp); //释放内存占用 return; //算法结束 } } } } //将临时数组写回(保存本轮成果) for (int i = 0; i < arrLen; ++i) arr[i] = temp[i]; } } QQ音乐歌单附完整程序: #include #include #include void swap(int *arr, int i, int j) { int t = arr[i]; arr[i] = arr[j]; arr[j] = t; } void Print(int *arr, int arrLen) { int i; for (i = 0; i < arrLen; ++i) printf("%d ", arr[i]); printf("\n"); } // ///*冒泡排序*/ void BubbleSort(int *arr, int arrLen) { //需要传入数组引用以及,数组长度 int i, j; for (i = 0; i < arrLen - 1; ++i) //控制比较的轮数 for (j = 0; j < arrLen - i - 1; ++j) //控制每轮比较次数 if (arr[j] > arr[j + 1]) //根据比较结果决定是否交换 swap(arr, j, j + 1); } /*选择排序*/ void SelectionSort(int *arr, int arrLen) { int i, j; int minElemIndex; //存每一轮最小元素索引 for (i = 0; i < arrLen; ++i) { minElemIndex = i; for (j = i + 1; j < arrLen; ++j) //在本轮汇总找出最小元素 if (arr[j] < arr[minElemIndex]) minElemIndex = j; //更新最小元素索引值 if (i != minElemIndex) //是否有必要交换 swap(arr, i, minElemIndex); //将本轮最小元素与对应位置上的元素交换 } } /*插入排序*/ void InsertionSort(int arr[], int arrLen) { int i, j; // 注意索引从1开始 for (i = 0; i < arrLen; ++i) for (j = i; j > 0; --j) // 从第二个位置开始判断,每次前移一位继续比较 if (arr[j] < arr[j - 1]) //相邻的俩俩比较 swap(arr, j, j - 1); else break; } /*堆排序*/ //堆化:构建大顶堆 void ShiftDown(int *arr, int heapSize, int k) { while (2 * k + 1 < heapSize) { // 在 k节点的所有子元素中执行一下步骤 int i = 2 * k + 1; // i为k的左孩子 if (i + 1 < heapSize && (arr[i + 1] > arr[i])) // 如果其右孩子在需排序的长度范围内,且左孩子小于右孩子 i += 1; //该节点遍历结束, if (arr[k] >= arr[i]) //当k结点大于该节点终止循环 break; swap(arr, k, i); //不符合堆定义,交换元素位置 k = i; //更新节点交换后的位置 } } void HeadSort(int *arr, int arrLen) { int i; for (i = (arrLen - 1) / 2; i >= 0; --i) ShiftDown(arr, arrLen, i); // 建立初始堆 for (i = arrLen - 1; i > 0; --i) { swap(arr, 0, i); //交换首尾元素,第i次排序完成 ShiftDown(arr, i, 0); // 重构堆(i记录了上次发生交换的结点) } } /*验证堆排序不稳定性*/ //typedef struct { // int id; // 数据编号(唯一) // int value; // 排序字段 // /*其他字段……*/ //} data; // //void swap(data *arr, int i, int j) { // data t = arr[i]; // 这里交换整个data而非排序字段 // arr[i] = arr[j]; // arr[j]= t; //} // //void ShiftDown(data *arr, int heapSize, int k) { // while (2 * k + 1 < heapSize) { // int i = 2 * k + 1; // if (i + 1 < heapSize && (arr[i + 1].value > arr[i].value)) // i += 1; // if (arr[k].value >= arr[i].value) // break; // swap(arr, k, i); // k = i; // } //} // //void HeadSort(data *arr, int arrLen) { // int i; // for (i = (arrLen - 1) / 2; i >= 0; --i) // ShiftDown(arr, arrLen, i); // 将当前 // for (i = arrLen - 1; i > 0; --i) { // swap(arr, 0, i); // ShiftDown(arr, i, 0); // } //} /*并归排序*/ int Merge(int *arr, int left, int mid, int right) { int i = left, j = mid, index = 0; int *temp = (int *) malloc(sizeof(int) * (right - left)); // 创建辅助数组 while (i < mid && j < right) temp[index++] = arr[i] < arr[j] ? arr[i++] : arr[j++]; // 比较大小,将较小元素并入辅助数组 while (i < mid) //并入左侧数组剩余元素 temp[index++] = arr[i++]; while (j < right) //并入右侧数组剩余元素 temp[index++] = arr[j++]; for (i = 0; i < index; ++i) //辅助数组数据写回原数组(重要) arr[left + i] = temp[i]; free(temp); // 释放辅助数组内存空间 } void MergeSort(int *arr, int left, int right) { // 1.递归拆分原数组 if (right - left = right) //参数校验 // return; // int index = Partition(arr, left, right); //获取新分区节点的位置(索引) // QuickSort(arr, left, index - 1); //左分区 // QuickSort(arr, index + 1, right); //右分区 //} /*随机优化快速排序*/ int Partition(int *arr, int left, int right) { swap(arr, right, rand() % (right - left) + left); // 随机选取基准值 int pivot = arr[right], i = left; //默认以每组最右元素为基准值 for (int j = left; j < right; ++j) { //从左向右遍历 if (arr[j] < pivot) { if (i != j) swap(arr, i, j); //将较小值放在靠前的位置 i++; } } swap(arr, i, right); //基准值插在最后一个较小值之后,这样其前面就是较小的分区,后面是较大的分区 return i; //返回新分区结点位置 } void QuickSort(int *arr, int left, int right) { if (left >= right) //参数校验 return; int index = Partition(arr, left, right); //获取新分区节点的位置(索引) QuickSort(arr, left, index - 1); //左分区 QuickSort(arr, index + 1, right); //右分区 } /*希尔排序*/ void ShellSort(int *arr, int arrLen) { int i, j, group; for (group = arrLen / 2; group > 0; group /= 2) { //分组 for (i = group; i < arrLen; ++i) { //排序遍历从分组间隔数开始(不会取到 int temp = arr[i]; for (j = i; j >= group && temp < arr[j - group]; j -= group) //组内排序 arr[j] = arr[j - group]; //就是在前面找到了一个合适的位置交换了元素,像不像插入排序?? arr[j] = temp; } } } /*桶排序*/ void BucketSort(int *arr, int arrLen) { } /*计数排序*/ int GetMax(int *arr, int arrLen) { int max = arr[0]; for (int i = 0; i < arrLen; ++i) if (arr[i] > max) max = arr[i]; return max; } void CountingSort(int *arr, int arrLen) { int length = GetMax(arr, arrLen) + 1, i, j, k; int *counting = (int *) malloc(sizeof(int) * length); //开辟一个长度为最大值+1的数组 for (i = 0; i < arrLen; ++i) //数组初始化 counting[i] = 0; for (i = 0; i < arrLen; ++i) //开始计数 counting[arr[i]]++; for (i = 0, j = 0; j < length; ++j) { if (counting[j] != 0) for (k = 0; k < counting[j]; ++k) //安装counting计数结果重新将数据写回数组(即排序) arr[i++] = j; } free(counting); } /*基数排序*/ void RadixSort(int *arr, int arrLen) { int flag, k, weight, radix, i; int *temp = (int *) malloc(sizeof(int) * arrLen); //这里是直接把双重队列用一个数组代替 // 从低位到高位,weight表示权值 for (weight = 1;; weight *= 10) { //radix就是9个基数,每次按顺序取一个基数 for (radix = 0, k = 0; radix < 10; ++radix) { //遍历待排序数组,寻找特定位数上基数匹配的数 for (i = 0, flag = 0; i < arrLen; ++i) { if (arr[i] / weight % 10 == radix) //取出该数指定位置上的数与本轮拿到的基数比较 temp[k++] = arr[i]; //匹配后将该数写入所谓的双重队列数组(不同权值时temp数组刷新,重新写) if (arr[i] / weight % 10 == 0) { //记录每次发生该位上的数字为0的次数 ++flag; if (flag == arrLen) { //如果出现的次数等于数组长度,上次已经比较完了最高位 free(temp); //释放内存占用 return; //算法结束 } } } } //将临时数组写回(保存本轮成果) for (i = 0; i < arrLen; ++i) arr[i] = temp[i]; } } int main() { int i, j; /*测试用例:*/ // int arr[] = {0, 3, -2, 6, 5, 1, 5}; // int arr[] = {78, 56, 36, 22, 19, 16, 5, 22}; // int arr[] = {9, 78, 29, 40, 33, 10, 56, 36, 22, 19, 16, 5, 82, 117}; int arr[] = {7, 6, 9, 3, 8, 1, 5, 0, 2, 4}; //适用计数排序 // int arr[] = {27, 16, 9, 33, 82, 5, 5, 10, 2, 54}; //适用计数排序 // data arr[] = {1,3, // 2,9, // 3,2, // 4,2, // 5,9, // 6,3, // 7,2}; int arrLen = sizeof(arr) / sizeof(arr[0]); // 计算数组大小 // BubbleSort(arr, arrLen); // SelectionSort(arr, arrLen); // InsertionSort(arr, arrLen); // HeadSort(arr, arrLen); // MergeSort(arr, 0, arrLen); // QuickSort(arr, 0, arrLen); // ShellSort(arr, arrLen); // BucketSort(arr, arrLen); // CountingSort(arr, arrLen); RadixSort(arr, arrLen); Print(arr, arrLen); /*验证堆排序不稳定性*/ // printf("value:"); // for (i = 0; i < arrLen; ++i) // printf("%d ", arr[i].value); // printf("\n"); // printf("id:"); // for (i = 0; i < arrLen; ++i) // printf("%d ", arr[i].id); } |


【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |