Pandas之数据分箱/分组/聚合/透视表 |
您所在的位置:网站首页 › 分组词是什么啊 › Pandas之数据分箱/分组/聚合/透视表 |
Pandas之数据分箱/分组/聚合/透视表
No.1 数据分箱 No.2 数据分组 No.3 数据聚合 No.4 透视表 No.1 数据分箱说到数据分箱。其实每个人都很熟悉,大家在买苹果的时候啊,会知道,水果店会把不同大小的或者新鲜程度的各种苹果放在不同的箱子里面供你挑选,当然价格也会有所不同。 其实这就是数据分箱,再举例,学生的考试成绩,0-59分是不合格,60-69是合格,70-79是良好,80-100是优秀。那这其实也是数据分箱,说到这里数据分箱什么意思也就明白了。 那下面就用notebook写代码来演示数据分箱。 首先创建一个长度为20的,范围在30-100之间的学生分数的数组。  然后我们再设置分箱。  这就表示数据有0-59,59-70,70-80,80-100这几个等级。 下面把分箱和分数利用cut方法结合到一起。  这里表示0-59分的一共有12名同学,80-100有5名同学,下面以此类推。 下面就创建一个DataFrame,把数据放进去,再随机生成字符串表示学生姓名。  这下是不是很明白了,每个学生对于什么成绩,每个成绩对于什么等级都很清楚了,这里就是把分箱的几个范围用以易懂的低、中、高这样的字样来替代了而已。 No.2 数据分组数据分组的话其实应该更加熟悉,其实就是group by,这个在sql里面应该是常见的,比如随便写一个sql用group by 按照条件分组: select * from table_1 left join table_2 where xxx group by xxx看,其实这不就是数据分组,所以这里面要讲的数据分组和这个也是一个意思。 废话不多说,首先读取一个天气的csv文件进来。  数据里面有城市,有温度和风力数据,下面就用groupby来按照城市分组看看。  g.groups告诉我们分组的结果,按照城市分的很清楚。 但是这不是我们要的,我们要的是像sql一样得到一张新的表格。怎么操作呢?  是不是有了。熟悉的配方熟悉的味道。 我们还可以对这个新的数据做更多的操作,比如求个平均值,不仅仅可以求分组的平均值,这个原始数据平均值也可以直接求得。  是不是hin?比,还可以查看每一个城市的最大最小值。  还可以dict、list之间互相转换。 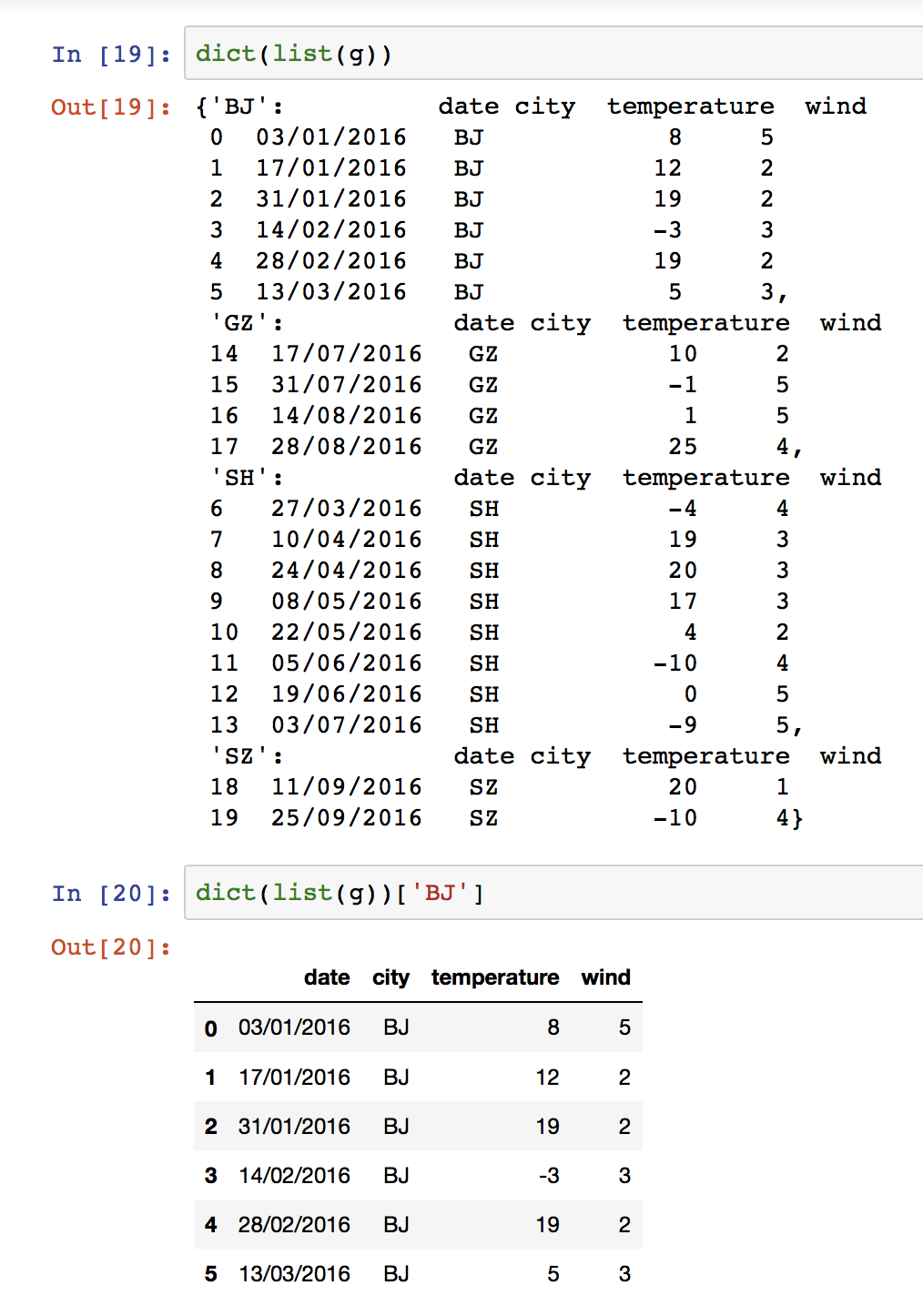 还可以有for循环。  到这里数据分组就写完了。 No.3 数据聚合其实就是agg聚合嘛,直接看代码吧。 还是基于天气数据,先把数据拿进来。  然后自定义一个函数,用来当作聚合函数。 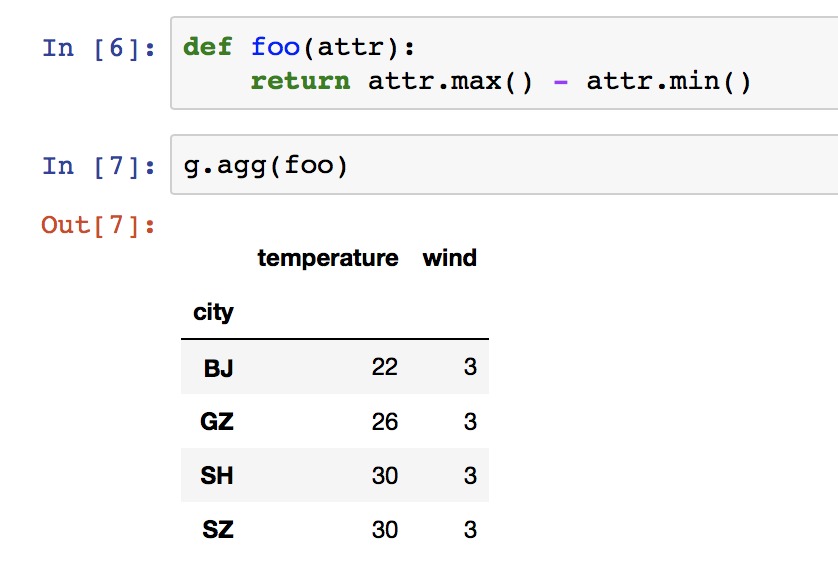 显然这里的聚合函数是用每个城市相应列的数据的最大值减去最小值。 下面再按照city和wind分组。  看看按照一个分组和两个分组的区别。  按照city和wind分组的就不能直接写BJ了,需要指定对应的风力值。 同样的你也可以for循环。  No.4 透视表 No.4 透视表其实透视表的概念来自于excel,先读一个excel表格进来。  那怎么根据这张表生成一个透视表呢?  透视表做出来了,我们仔细看一看这张表,其实就是按照Name把Account去重了,再把Price和Quantity做了一个平均值,其实就是聚合操作吗,我们看一下源码。  是不是一个agg操作,而且默认是mean也就是平均值,那其实可以更改这个agg函数,我们看。  是不是从平均值到求和了。还可以多添加几个透视表参数进去。  然后再按照Manager生成透视表。  好像和前面的不一样,因为每一个Manager下面可能会有好多个销售代表。 还可以指定想看的某一列value。  最后你还可以添加columns进去,比如。  这里是什么意思呢?首先看代码,还是按照两个字段做的透视表,聚合还是sum,添加了Product这一项,fill_value是因为可能有的销售没有卖到某个产品导致某个地方为NaN,所以可以填充数据。 然后看表格,前面都是一样的,加了Product之后可以看到,每一件产品的价格和销售数量以及对应的销售代表买了多少都很清楚的展示了出来,前面是价格后面是数量,所以这个功能还是很好的。 ----------------------------------------------------------------------------------- 到此,Pandas之数据分箱/分组/聚合/透视表就写完了。 
|
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |