机器学习十大算法案例 |
您所在的位置:网站首页 › 分类算法有哪些实际案例分析题目 › 机器学习十大算法案例 |
机器学习十大算法案例
|
机器学习十大算法与案例实现
监督学习1. 线性回归2. 逻辑回归3. 神经网络4. SVM支持向量机5. K邻近6. 贝叶斯7. 决策树8. 集成学习(Adaboost)
非监督学习9. 降维—主成分分析10. 聚类分析
监督学习
1. 线性回归
梯度下降一元线性回归 import numpy as np import matplotlib.pyplot as plt # 载入数据 data = np.genfromtxt("data.csv", delimiter=",") x_data = data[:,0] y_data = data[:,1] # 学习率learning rate lr = 0.0001 # 截距 b = 0 # 斜率 k = 0 # 最大迭代次数 epochs = 50 # 最小二乘法 def compute_error(b, k, x_data, y_data): totalError = 0 for i in range(0, len(x_data)): totalError += (y_data[i] - (k * x_data[i] + b)) ** 2 return totalError / float(len(x_data)) / 2.0 def gradient_descent_runner(x_data, y_data, b, k, lr, epochs): # 计算总数据量 m = float(len(x_data)) # 循环epochs次 for i in range(epochs): b_grad = 0 k_grad = 0 # 计算梯度的总和再求平均 for j in range(0, len(x_data)): b_grad += (1/m) * (((k * x_data[j]) + b) - y_data[j]) k_grad += (1/m) * x_data[j] * (((k * x_data[j]) + b) - y_data[j]) # 更新b和k b = b - (lr * b_grad) k = k - (lr * k_grad) return b, k print("Starting b = {0}, k = {1}, error = {2}".format(b, k, compute_error(b, k, x_data, y_data))) print("Running...") b, k = gradient_descent_runner(x_data, y_data, b, k, lr, epochs) print("After {0} iterations b = {1}, k = {2}, error = {3}".format(epochs, b, k, compute_error(b, k, x_data, y_data))) #画图 plt.plot(x_data, y_data, 'b.') plt.plot(x_data, k*x_data + b, 'r') plt.show()
逻辑回归原理与推导 梯度下降法-逻辑回归 import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import classification_report from sklearn import preprocessing # 数据是否需要标准化 scale = True # 载入数据 data = np.genfromtxt("LR-testSet.csv", delimiter=",") x_data = data[:,:-1] y_data = data[:,-1] def plot(): x0 = [] x1 = [] y0 = [] y1 = [] # 切分不同类别的数据 for i in range(len(x_data)): if y_data[i]==0: x0.append(x_data[i,0]) y0.append(x_data[i,1]) else: x1.append(x_data[i,0]) y1.append(x_data[i,1]) # 画图 scatter0 = plt.scatter(x0, y0, c='b', marker='o') scatter1 = plt.scatter(x1, y1, c='r', marker='x') #画图例 plt.legend(handles=[scatter0,scatter1],labels=['label0','label1'],loc='best') plot() #查看数据 plt.show()
神经网络 4. SVM支持向量机SVM-非线性 import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import classification_report from sklearn import svm # 载入数据 data = np.genfromtxt("LR-testSet2.txt", delimiter=",") x_data = data[:,:-1] y_data = data[:,-1] def plot(): x0 = [] x1 = [] y0 = [] y1 = [] # 切分不同类别的数据 for i in range(len(x_data)): if y_data[i]==0: x0.append(x_data[i,0]) y0.append(x_data[i,1]) else: x1.append(x_data[i,0]) y1.append(x_data[i,1]) # 画图 scatter0 = plt.scatter(x0, y0, c='b', marker='o') scatter1 = plt.scatter(x1, y1, c='r', marker='x') #画图例 plt.legend(handles=[scatter0,scatter1],labels=['label0','label1'],loc='best') plot() plt.show() # fit the model # C和gamma model = svm.SVC(kernel='rbf') model.fit(x_data, y_data) model.score(x_data,y_data) # 获取数据值所在的范围 x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1 y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1 # 生成网格矩阵 xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02)) z = model.predict(np.c_[xx.ravel(), yy.ravel()])# ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据 z = z.reshape(xx.shape) # 等高线图 cs = plt.contourf(xx, yy, z) plot() plt.show()
主要过程
设每个数据样本用一个n维特征向量来描述n个属性的值,即:X={x1,x2,…,xn},假定有m个类,分别用C1, C2,…,Cm表示。给定一个未知的数据样本X(即没有类标号),若朴素贝叶斯分类法将未知的样本X分配给类Ci,则一定是 P(Ci|X)>P(Cj|X) 1≤j≤m,j≠i from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.preprocessing import LabelEncoder import pandas as pd from numpy import * import operator #计算高斯分布密度函数的值 def calculate_gaussian_probability(mean, var, x): coeff = (1.0 / (math.sqrt((2.0 * math.pi) * var))) exponent = math.exp(-(math.pow(x - mean, 2) / (2 * var))) c= coeff * exponent return c #计算均值 def averagenum(num): nsum = 0 for i in range(len(num)): nsum += num[i] return nsum / len(num) #计算方差 def var(list,avg): var1=0 for i in list: var1+=float((i-avg)**2) var2=(math.sqrt(var1/(len(list)*1.0))) return var2 #朴素贝叶斯分类模型 def Naivebeys(splitData, classset, test): classify = [] for s in range(len(test)): c = {} for i in classset: splitdata = splitData[i] num = len(splitdata) mu = num + 2 character = len(splitdata[0])-1 #具体数据集,个数有变 classp = [] for j in range(character): zi = 1 if isinstance(splitdata[0][j], (int, float)): numlist=[example[j] for example in splitdata] Mean=averagenum(numlist) Var=var(numlist,Mean) a = calculate_gaussian_probability(Mean, Var, test[s][j]) else: for l in range(num): if test[s][j] == splitdata[l][j]: zi += 1 a=zi/mu classp.append(a) zhi = 1 for k in range(character): zhi *= classp[k] c.setdefault(i, zhi) sorta = sorted(c.items(), key=operator.itemgetter(1), reverse=True) classify.append(sorta[0][0]) return classify #评估 def accuracy(y, y_pred): yarr=array(y) y_predarr=array(y_pred) yarr = yarr.reshape(yarr.shape[0], -1) y_predarr = y_predarr.reshape(y_predarr.shape[0], -1) return sum(yarr == y_predarr) / len(yarr) #数据处理 def splitDataset(dataSet): #按照属性把数据划分 classList = [example[-1] for example in dataSet] classSet = set(classList) splitDir = {} for i in classSet: for j in range(len(dataSet)): if dataSet[j][-1] == i: splitDir.setdefault(i, []).append(dataSet[j]) return splitDir, classSet open('test.txt') df = pd.read_csv('test.txt') class_le = LabelEncoder() dataSet = df.values[:, :] dataset_train,dataset_test=train_test_split(dataSet, test_size=0.1) splitDataset_train, classSet_train = splitDataset(dataset_train) classSet_test=[example[-1] for example in dataset_test] y_pred= Naivebeys(splitDataset_train, classSet_train, dataset_test) accu=accuracy(classSet_test,y_pred) print("Accuracy:", accu)Accuracy: 0.65 7. 决策树决策树的分类模型是树状结构,简单直观,比较符合人类的理解方式。决策树分类器的构造不需要任何领域知识和参数设置,适合于探索式知识的发现。由于决策树分类步骤简单快速,而且一般来说具有较高的准确率,因此得到了较多的使用。 信息量 某事件发生所含有的信息量是该事件发生概率的函数:其中, p ( x i ) p(x_{i}) p(xi)是 x i x_{i} xi发生的概率, I ( x i ) I(x_{i}) I(xi)表示 x i x_{i} xi发生所含的信息量,称为 x i x_{i} xi的自信息量,单位是比特 ( b ) (b) (b) I ( x i ) = − log 2 p ( x i ) I(x_{i})=-\log_2 p(x_{i}) I(xi)=−log2p(xi) 信息熵 如果将信息源所有可能事件的自信息量进行平均,即可得到信息的“熵”。设信息源 X X X的符号集为 x i ( i = 1 , 2 , ⋯ , N ) x_{i}(i=1,2,\cdots,N) xi(i=1,2,⋯,N), x i x_{i} xi出现的概率为 p ( x i ) p(x_{i}) p(xi),则信息源 X X X的熵为: H ( X ) = ∑ i = 1 N p ( x i ) I ( x i ) = − ∑ i = 1 N p ( x i ) log 2 p ( x i ) H(X)=\sum_{i=1}^{N}p(x_{i})I(x_{i})=-\sum_{i=1}^{N}p(x_{i})\log_2 p(x_{i}) H(X)=i=1∑Np(xi)I(xi)=−i=1∑Np(xi)log2p(xi) ID3算法 ID3算法是Quinlan于1986年提出的,只能处理离散型描述属性,在选择根节点和各个内部节点上的分枝属性时,采用信息增益作为度量标准,选择具有最高信息增益的描述属性作为分枝属性。 假设 n j n_{j} nj是数据集 X X X中属于类别 c j c_{j} cj的样本数量,则各类别的先验概率为 p ( c j ) = n j t o t a l , j = 1 , 2 , ⋯ , m p(c_{j})=\frac{n_{j}}{total},j=1,2,\cdots,m p(cj)=totalnj,j=1,2,⋯,m。 数据集 X X X的期望信息为: I ( n 1 , n 2 , ⋯ , n m ) = − ∑ i = 1 N p ( c j ) log 2 p ( c j ) I(n_{1},n_{2},\cdots,n_{m})=-\sum_{i=1}^{N}p(c_{j})\log_2 p(c_{j}) I(n1,n2,⋯,nm)=−i=1∑Np(cj)log2p(cj) 由描述属性 A f A_{f} Af划分数据集 X X X所得的熵为: E ( A f ) = ∑ s = 1 q n 1 s + ⋯ + n m s t o t a l I ( n 1 s , ⋯ , n m s ) E(A_{f})=\sum_{s=1}^{q}\frac{n_{1s}+\cdots+n_{ms}}{total}I(n_{1s},\cdots,n_{ms}) E(Af)=s=1∑qtotaln1s+⋯+nmsI(n1s,⋯,nms) 其中: I ( n 1 s , ⋯ , n m s ) = − ∑ j = 1 m p j s log 2 p j s I(n_{1s},\cdots,n_{ms})=-\sum_{j=1}^{m}p_{js}\log_2 p_{js} I(n1s,⋯,nms)=−j=1∑mpjslog2pjs p j s = n j s n s p_{js}=\frac{n_{js}}{n_{s}} pjs=nsnjs Af划分数据集产生的信息增益为: G a i n ( A f ) = I ( n 1 , n 2 , ⋯ , n m ) − E ( A f ) Gain(A_{f})=I(n_{1},n_{2},\cdots,n_{m})-E(A_{f}) Gain(Af)=I(n1,n2,⋯,nm)−E(Af) 数据集介绍 本实验采用西瓜数据集,根据西瓜的几种属性判断西瓜是否是好瓜。数据集包含17条记录,数据格式如下: 色泽根蒂敲声纹理脐部触感好瓜青绿蜷缩浊响清晰凹陷硬滑是乌黑蜷缩沉闷清晰凹陷硬滑是乌黑蜷缩浊响清晰凹陷硬滑是 ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋯ \cdots ⋯实验 首先我们引入必要的库: import pandas as pd from math import log2 from pylab import * import matplotlib.pyplot as plt导入数据 读取csv文件中的数据记录并转为列表 def load_dataset(): # 数据集文件所在位置 path = "./西瓜.csv" data = pd.read_csv(path, header=0) dataset = [] for a in data.values: dataset.append(list(a)) # 返回数据列表 attribute = list(data.keys()) # 返回数据集和每个维度的名称 return dataset, attribute dataset,attribute = load_dataset() attribute,dataset (['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '好瓜'], [['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '是'], ['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '是'], ['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '是'], ['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '是'], ['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '是'], ['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '是'], ['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '是'], ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '是'], ['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '否'], ['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '否'], ['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '否'], ['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '否'], ['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '否'], ['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '否'], ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '否'], ['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '否'], ['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '否']])计算信息熵 def calculate_info_entropy(dataset): # 记录样本数量 n = len(dataset) # 记录分类属性数量 attribute_count = {} # 遍历所有实例,统计类别出现频次 for attribute in dataset: # 每一个实例最后一列为类别属性,因此取最后一列 class_attribute = attribute[-1] # 如果当前类标号不在label_count中,则加入该类标号 if class_attribute not in attribute_count.keys(): attribute_count[class_attribute] = 0 # 类标号出现次数加1 attribute_count[class_attribute] += 1 info_entropy = 0 for class_attribute in attribute_count: # 计算该类在实例中出现的概率 p = float(attribute_count[class_attribute]) / n info_entropy -= p * log2(p) return info_entropy数据集划分 def split_dataset(dataset,i,value): split_set = [] for attribute in dataset: if attribute[i] == value: # 删除该维属性 reduce_attribute = attribute[:i] reduce_attribute.extend(attribute[i+1:]) split_set.append(reduce_attribute) return split_set计算属性划分数据集的熵 def calculate_attribute_entropy(dataset,i,values): attribute_entropy = 0 for value in values: sub_dataset = split_dataset(dataset,i,value) p = len(sub_dataset) / float(len(dataset)) attribute_entropy += p*calculate_info_entropy(sub_dataset) return attribute_entropy计算信息增益 def calculate_info_gain(dataset,info_entropy,i): # 第i维特征列表 attribute = [example[i] for example in dataset] # 转为不重复元素的集合 values = set(attribute) attribute_entropy = calculate_attribute_entropy(dataset,i,values) info_gain = info_entropy - attribute_entropy return info_gain根据信息增益进行划分 def split_by_info_gain(dataset): # 描述属性数量 attribute_num = len(dataset[0]) - 1 # 整个数据集的信息熵 info_entropy = calculate_info_entropy(dataset) # 最高的信息增益 max_info_gain = 0 # 最佳划分维度属性 best_attribute = -1 for i in range(attribute_num): info_gain = calculate_info_gain(dataset,info_entropy,i) if(info_gain > max_info_gain): max_info_gain = info_gain best_attribute = i return best_attribute构造决策树 def create_tree(dataset,attribute): # 类别列表 class_list = [example[-1] for example in dataset] # 统计类别class_list[0]的数量 if class_list.count(class_list[0]) == len(class_list): # 当类别相同则停止划分 return class_list[0] # 最佳划分维度对应的索引 best_attribute = split_by_info_gain(dataset) # 最佳划分维度对应的名称 best_attribute_name = attribute[best_attribute] tree = {best_attribute_name:{}} del(attribute[best_attribute]) # 查找需要分类的特征子集 attribute_values = [example[best_attribute] for example in dataset] values = set(attribute_values) for value in values: sub_attribute = attribute[:] tree[best_attribute_name][value] =create_tree(split_dataset(dataset,best_attribute,value),sub_attribute) return tree tree = create_tree(dataset,attribute) tree {'纹理': {'清晰': {'根蒂': {'蜷缩': '是', '硬挺': '否', '稍蜷': {'色泽': {'青绿': '是', '乌黑': {'触感': {'软粘': '否', '硬滑': '是'}}}}}}, '模糊': '否', '稍糊': {'触感': {'软粘': '是', '硬滑': '否'}}}} # 定义划分属性节点样式 attribute_node = dict(boxstyle="round", color='#00B0F0') # 定义分类属性节点样式 class_node = dict(boxstyle="circle", color='#00F064') # 定义箭头样式 arrow = dict(arrowstyle=" |
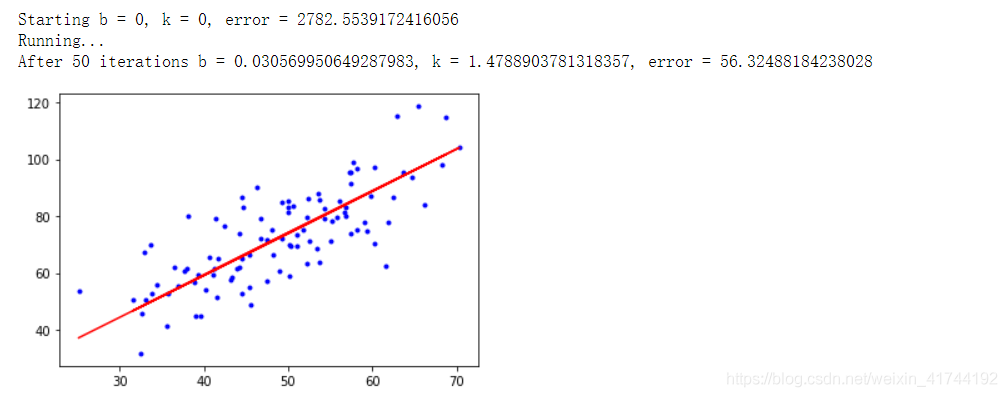 梯度下降法-多元线性回归
梯度下降法-多元线性回归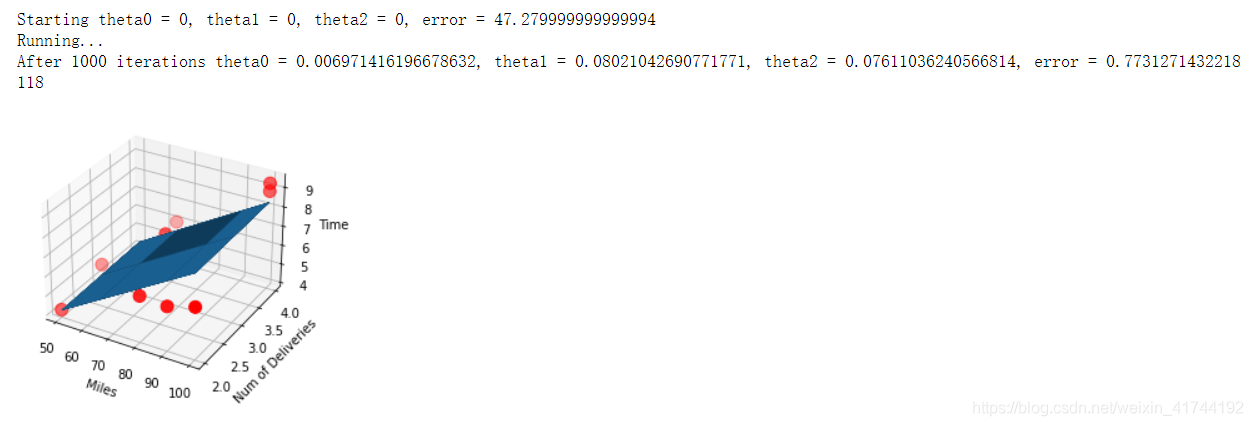
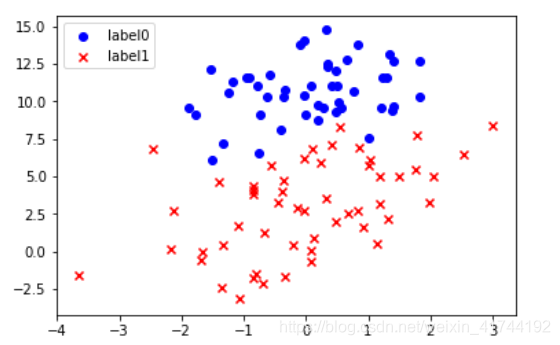
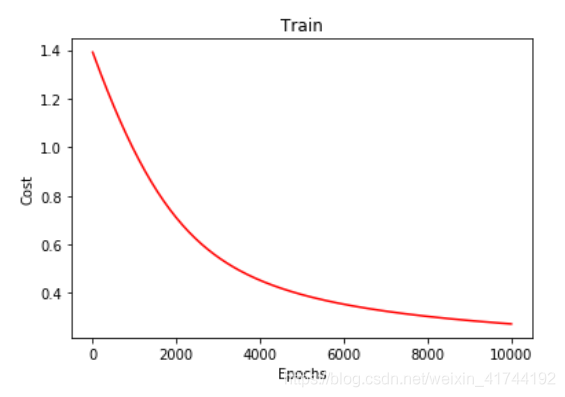
 梯度下降法-非线性逻辑回归
梯度下降法-非线性逻辑回归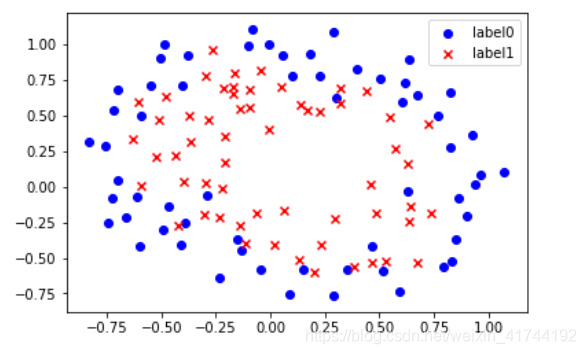
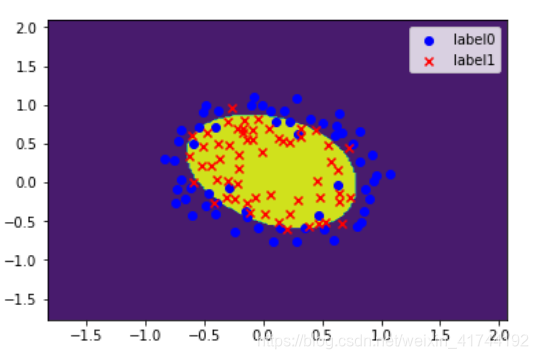
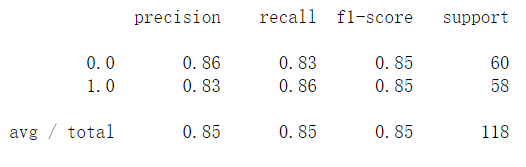
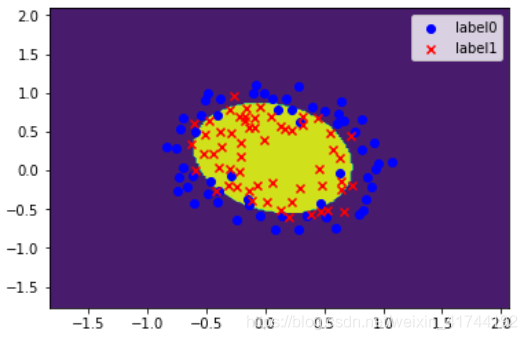

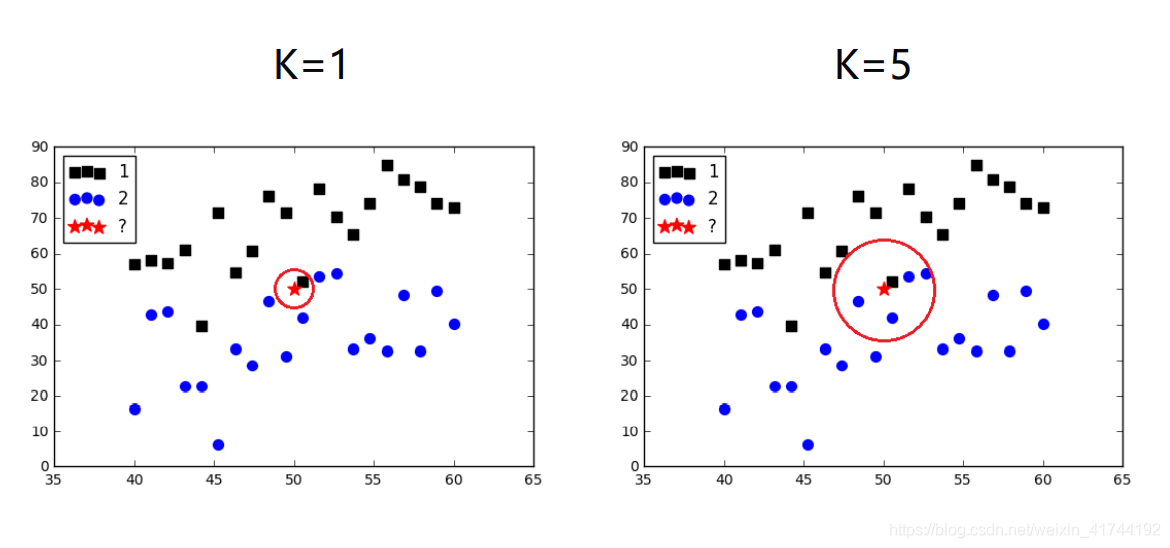 案例
案例
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |