【深度学习】:Softmax实现手写数字识别 |
您所在的位置:网站首页 › 使用numpy实现手写数字识别 › 【深度学习】:Softmax实现手写数字识别 |
【深度学习】:Softmax实现手写数字识别
|
清华大学驭风计划课程链接 学堂在线 - 精品在线课程学习平台 (xuetangx.com) 代码和报告均为本人自己实现(实验满分),只展示任务实验结果,如果需要报告或者代码可以私聊博主 有任何疑问或者问题,也欢迎私信博主,大家可以相互讨论交流哟~~ Softmax实现手写数字识别 相关知识点: numpy科学计算包,如向量化操作,广播机制等 1 简介本次案例中,你需要用python实现Softmax回归方法,用于MNIST手写数字数据集分类任务。你需要完成前向计算loss和参数更新。 你需要首先实现Softmax函数和交叉熵损失函数的计算。
在更新参数的过程中,你需要实现参数梯度的计算,并按照随机梯度下降法来更新参数。
具体计算方法可自行推导 MNIST数据集MNIST手写数字数据集是机器学习领域中广泛使用的图像分类数据集。它包含60,000个训练样本和10,000个测试样本。这些数字已进行尺寸规格化,并在固定尺寸的图像中居中。每个样本都是一个784×1的矩阵,是从原始的28×28灰度图像转换而来的。MNIST中的数字范围是0到9。下面显示了一些示例。
a) 记录训练和测试的准确率。画出训练损失和准确率曲线; b) 比较使用和不使用momentum结果的不同,可以从训练时间,收敛性和准确率等方面讨论差异; c) 调整其他超参数,如学习率,Batchsize等,观察这些超参数如何影响分类性能。写下观察结果并将这些新结果记录在报告中。 3.实验结果 a) 记录训练和测试的准确率 。 画出训练损失和准确率曲线;这里是使用原始提供的代码画出的图像
 b) 比较使用和不使用 momentum 结果的不同, 可以从训练时间, 收敛性和准确率等方面讨论差异;
b) 比较使用和不使用 momentum 结果的不同, 可以从训练时间, 收敛性和准确率等方面讨论差异;
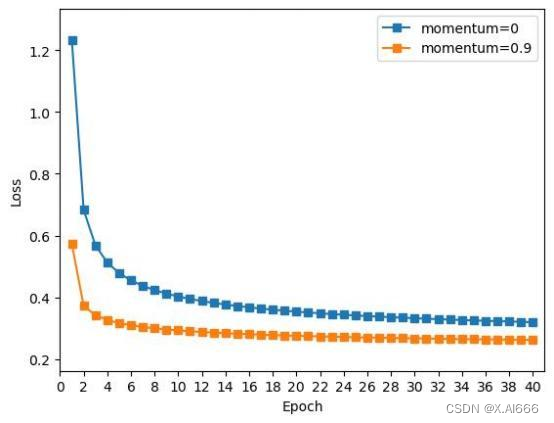
 训练时间
:达到相同准确率的情况下,使用动量的训练时间会更快,特别是陡峭的梯度
方向上,使得模型快速接近最优解附近。
收敛性
:不管使不使用动量都可以收敛,只不过使用动量后收敛会更快。
准确率
:为了看出差异我训练了
40
个周期,使用动量的优化算法有着更高的准确率,在
相同的训练周期可以看出使用了动量后准确率更高,即使在后期收敛正确率仍然有一定差距,
这说明使用动量容易跳出局部最优解。
c) 调整其他超参数 ,如学习率 ,Batchsize 等, 观察这些超参数如何影响分类性能 。
1,学习率
我把学习率分别调整为 1, 0.5, 0.1, 0.01, 0.001 这五个数值, 结果如下图所示
训练时间
:达到相同准确率的情况下,使用动量的训练时间会更快,特别是陡峭的梯度
方向上,使得模型快速接近最优解附近。
收敛性
:不管使不使用动量都可以收敛,只不过使用动量后收敛会更快。
准确率
:为了看出差异我训练了
40
个周期,使用动量的优化算法有着更高的准确率,在
相同的训练周期可以看出使用了动量后准确率更高,即使在后期收敛正确率仍然有一定差距,
这说明使用动量容易跳出局部最优解。
c) 调整其他超参数 ,如学习率 ,Batchsize 等, 观察这些超参数如何影响分类性能 。
1,学习率
我把学习率分别调整为 1, 0.5, 0.1, 0.01, 0.001 这五个数值, 结果如下图所示

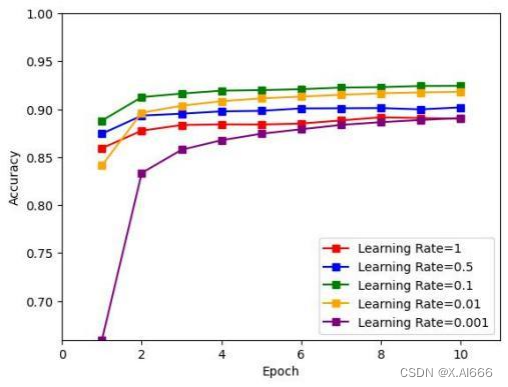 通过图像看出学习率为
0.1
的时候最优,拥有最高的正确率,学习率为
1
的时候发生震荡现
象,因此为
1
的时候学习率过大。当学习率为
0.001
的时候发现收敛速度过慢,可能需要更
多的迭代次数才能达到较高准确率。
2 ,Batchsize
通过图像看出学习率为
0.1
的时候最优,拥有最高的正确率,学习率为
1
的时候发生震荡现
象,因此为
1
的时候学习率过大。当学习率为
0.001
的时候发现收敛速度过慢,可能需要更
多的迭代次数才能达到较高准确率。
2 ,Batchsize

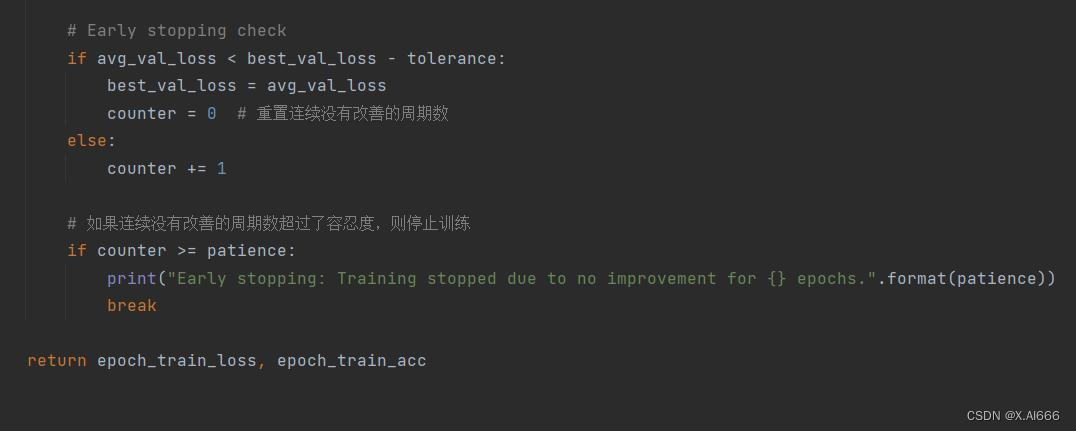 其余部分和原代码一样
其余部分和原代码一样
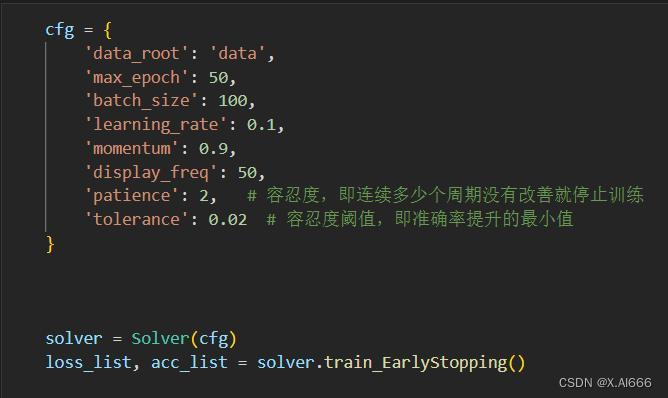
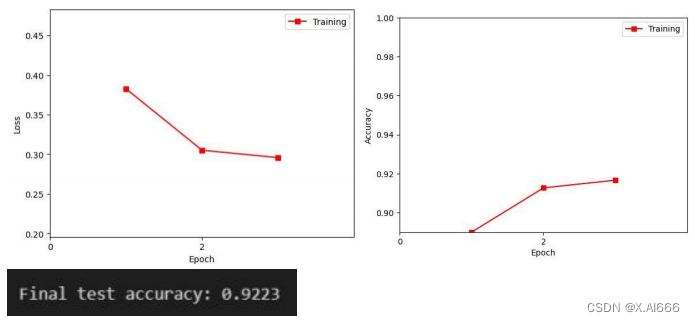 通过对容忍度的调整,发现等于
2
的时候也就是
2
个周期准确度没有提升
0.02
以上就停止
训练,结果最优为
0.9223(在尽量少训练时间的情况下)
通过对容忍度的调整,发现等于
2
的时候也就是
2
个周期准确度没有提升
0.02
以上就停止
训练,结果最优为
0.9223(在尽量少训练时间的情况下)
|
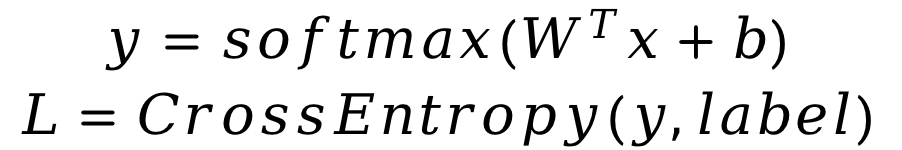
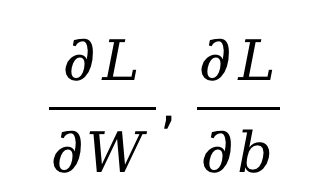




【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |