根据时间戳,增量同步数据的解决办法 |
您所在的位置:网站首页 › 仔仔的ID怎么取 › 根据时间戳,增量同步数据的解决办法 |
根据时间戳,增量同步数据的解决办法
|
由于markdown的样式太丑了,懒得再调整了,我另外再贴一个github的博客该文的 github链接 前言最近在工作中遇到一个比较棘手的问题,客户端从服务端同步数据的问题。 背景简介:客户端有N个,客户端上的同步时间,各不相同。同步的时候,是一次获取10条数据,多批次获取。即分页获取。 在代码中存在两种同步的方式: 全量同步。同步过程是从服务端拉取全部的数据;依赖具有唯一约束的ID来实现同步。只适用于数据量小的表,浪费网络流量。 增量同步。从服务器拉取大于客户端最新时间的数据;依赖于时间戳,问题时间戳不唯一存在相同时间点下面多条数据,会出现数据遗漏,也会重复拉取数据,浪费网络流量。本文的所使用到的解决办法,就是结合了唯一ID和时间戳,两个入参来做增量同步。本文也只做逻辑层面的说明。 模拟场景表结构:ID 具有唯一约束, Name 姓名, UpdateTime 更新时间;现在问题的关键是ID为3,4,这两条时间点相同的数据。 假如一次只能同步一条数据,如何同步完ID 2后,再同步 ID 3。 ID Name UpdateTime 1 张三 2018-11-10 2 李四 2018-12-10 3 王五 2018-12-10 4 赵六 2018-11-20 5 金七 2018-11-30 解决思路 生成新的唯一标识通过 UpdateTime 和 ID 这两种数据,通过某种运算,生成新的数。而这个新的数具备可排序和唯一;同时还要携带有ID和UpdateTime的信息。 简单表述就是,具有一个函数f: f(可排序A,可排序唯一B) = 可排序唯一C 。 C 的唯一解是 A和B。RSA加密算法 我想出了一个方法,也是生活中比较常用的方法: 先把 UpdateTime 转变成数字。如: 字符串 2018-12-10 -> 数字 20181210; 然后 UpdateTime 乘以权重,这个权重必须大于ID的可能最大值。如: 20181210 * 100 = 2018121000,Max(ID) sync_time LIMIT 10 但是情景2的情况不能使用大于>这个条件。假如使用了大于>这个条件,情景2就会变成情景1或情景3或图3这种情况。不是包含部分了,需要额外特别处理。 注:图3的结束点 ]不重要,下面情景5有解释。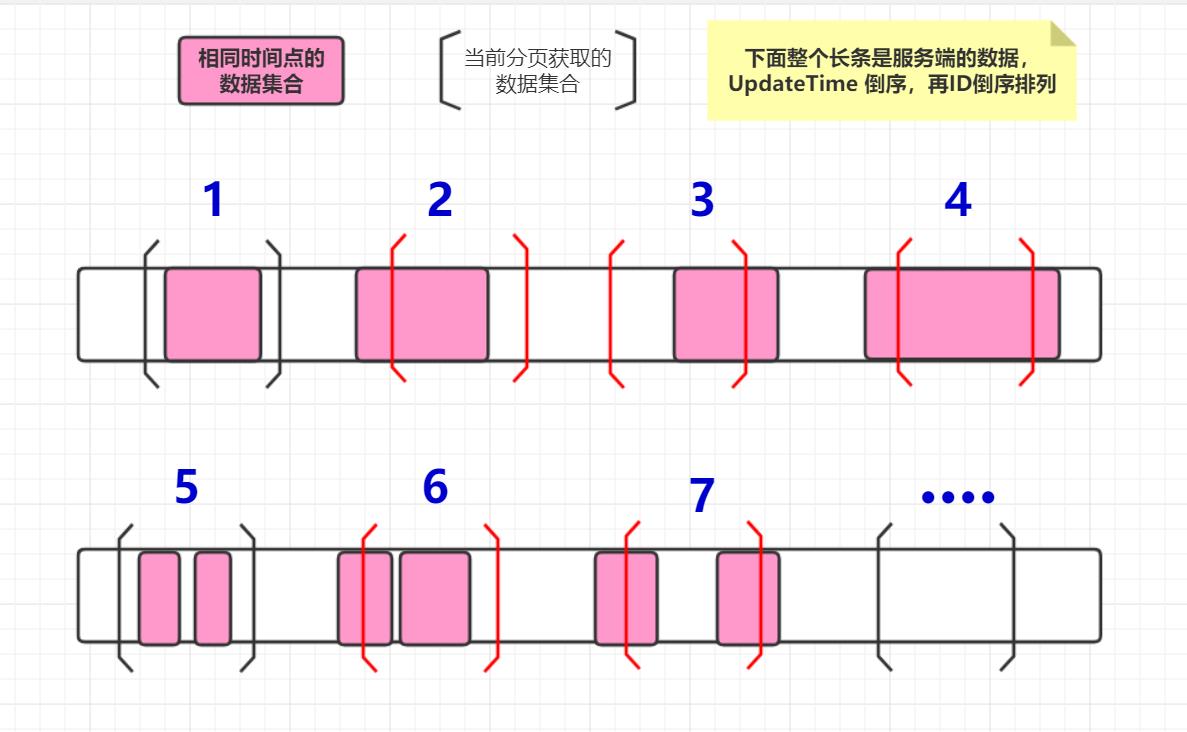 情景2部分情况,提取的起始点
情景2部分情况,提取的起始点
提取的起始点:也就是说图中[左中括号的位置,需要准确定位这个位置。 至于结束点:图中]右中括号的位置是在哪里。这个就不重要了,因为下一次的分页提取的起始点,就是上一次的结束点。只需要关注起始点就足够了。 而根据起始点,又可以把情景2,再做一次简化: 情景4。起始点在相同时间点集合内的;图2,图4,图6,图7 情景5。起始点不在相同时间点集合内的;图3,针对情景4。这个时候,时间戳sync_time一个入参就不够了,还额外需要唯一键ID来准确定位。可以把查询写作:WHERE UpdateTime = sync_time AND ID > sync_id LIMIT 10。 如果查询的行数 等于 10,则是图4;小于 10,则是图2,图6,图7的情况。 针对情景5。依旧可以使用:WHERE UpdateTime > sync_time LIMIT 10 完整的分页过程完整的分页过程的步骤: 一、先用起始点来过滤:WHERE UpdateTime = sync_time AND ID > sync_id LIMIT 10,查询结果行数N。如果 N=10是图4的情况,则结束,并且直接返回结果。如果 0 |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |