数据结构(C++)图的数组存储、深度优先搜索(DFS)、广度优先搜索(BFS) |
您所在的位置:网站首页 › 二维数组dfs › 数据结构(C++)图的数组存储、深度优先搜索(DFS)、广度优先搜索(BFS) |
数据结构(C++)图的数组存储、深度优先搜索(DFS)、广度优先搜索(BFS)
|
图的特点:顶点之间的关系是m:n,即任何两个顶点之间都可能存在关系(边),无法通过存储位置表示这种任意的逻辑关系,所以,图无法采用顺序存储结构。 所以为了图的存储我们采用的是一个一维数组来存储每个顶点的信息。用一个二维数组(邻接矩阵)存储各顶点之间的邻接关系。 如果arc[i][j]==1则 i 与 j 之间一定有一条边相连。 vertex数组来存储每个顶点的信息,比如ABCDEFG、1234567 。 定义全局参数 MaxSize设置为顶点的最大值。visited数组用来表示该顶点是否已经被访问过,访问过为1,没有访问过为0 。在初始的时候设置visited数组全部为0 。注意:在深搜过后如果要进行广搜操作,必须把该数组重新设置! const int MaxSize = 11; int visited[MaxSize]; 邻接矩阵存储无向图的类:这里英文特别容易弄混,我都晕了一会。 vertexNum 表示 顶点个数。arcNum 表示 边的个数。 const int MaxSize = 10; template class Mgraph { public: MGraph(T a[], int n, int e); ~MGraph() void DFSTraverse(int v); void BFSTraverse(int v); private: T vertex[MaxSize]; int arc[MaxSize][MaxSize]; int vertexNum, arcNum; 构造函数 a数组表示每个顶点的信息,为vertexNum数组赋值。把所有的边都赋值为0,暂时默认所有的边都没有连接。以边数为循环条件,输入两顶点,然后赋值为1 。 Mgraph(T a[], int n, int e) { vertexNum = n; arcNum = e; for (int i = 1; i for (int j = 1; j int a, b; cin >> a >> b; arc[a][b] = arc[b][a] = 1; } } 深度优先搜索 该函数的参数v代表以v开始,搜索所有与v临界的顶点。循环然后进行判断,如果相连且未被访问过,则以此为顶点重新开始深搜。 void DFSTraverse(int v) { cout DFSTraverse(i); } } } 广度优先搜索 使用顺序队列进行操作,front与rear做头尾。先把v作为队列的头进行入队。每次循环v等于对头顶点,并以此为顶点,将所有 有 (与之相连边)的顶点入队,并且输出值,重新设置visited。头尾指针不相等,一直持续操作,知道头尾重合,遍历结束。 void BFSTraverse(int v) { int front = 0; int rear = 0; int q[MaxSize]; cout if (arc[v][i] == 1 && visited[i] == 0) { cout vertexNum = n; arcNum = e; for (int i = 1; i for (int j = 1; j int a, b; cin >> a >> b; arc[a][b] = arc[b][a] = 1; } } void DFSTraverse(int v) { cout DFSTraverse(i); } } } void BFSTraverse(int v) { int front = 0; int rear = 0; int q[MaxSize]; cout if (arc[v][i] == 1 && visited[i] == 0) { cout 0,1,2,3,4,5,6,7,8,9,10 }; int x, y; // x是点,y是边 cin >> x >> y; Mgraphm(a, x, y); cout |
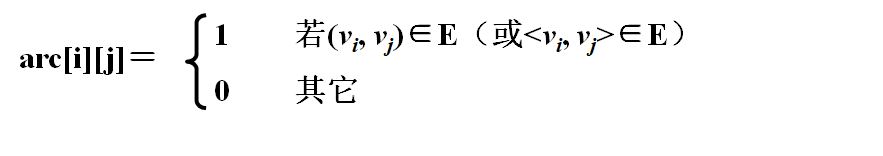 根据我们对于图的定义,我们通常使用简单无向图来表示,所以我们定义的图一定是:
根据我们对于图的定义,我们通常使用简单无向图来表示,所以我们定义的图一定是:【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |