|
多元线性模型的主要作用:(主要进行预测) 通过建模来拟合我们所提供的或是收集到的这些因变量和自变量的数据,收集到的数据拟合之后来进行参数估计。参数估计的目的主要是来估计出模型的偏回归系数的值。估计出来之后就可以再去收集新的自变量的数据去进行预测,也称为样本量 
import pandas as pd
import numpy as np
import statsmodels.api as sm#实现了类似于二元中的统计模型,比如ols普通最小二乘法
import statsmodels.stats.api as sms#实现了统计工具,比如t检验、F检验...
import statsmodels.formula.api as smf
import scipy
np.random.seed(991)#随机数种子
x1 = np.random.normal(0,0.4,100)#生成符合正态分布的随机数(均值,标准差,所生成随机数的个数)
x2 = np.random.normal(0,0.6,100)
x3 = np.random.normal(0,0.2,100)
eps = np.random.normal(0,0.05,100)#生成噪声数据,保证后面模拟所生成的因变量的数据比较接近实际的环境
X = np.c_[x1,x2,x3]#调用c_函数来生成自变量的数据的矩阵,按照列进行生成的;100×3的矩阵
beta = [0.1,0.2,0.7]#生成模拟数据时候的系数的值
y = np.dot(X,beta) + eps#点积+噪声
X_model = sm.add_constant(X)#add_constant给矩阵加上一列常量1,主要目的:便于估计多元线性回归模型的截距,也是便于后面进行参数估计时的计算
model = sm.OLS(y,X_model)#调用OLS普通最小二乘
results = model.fit()#fit拟合,主要功能就是进行参数估计,参数估计的主要目的是估计出回归系数,根据参数估计结果来计算统计量,这些统计量主要的目的就是对我们模型的有效性或是显著性水平来进行验证
results.summary()#summary方法主要是为了显示拟合的结果

一、回归系数的参数估计
1.1 最小二乘法实现参数估计——估计自变量X的系数

'''
回归系数的计算:X转置乘以X,对点积求逆后,再点乘X转置,最后点乘y
'''
beta_hat = np.dot(np.dot(np.linalg.inv(np.dot(X_model.T,X_model)),X_model.T),y)#回归系数
print('回归系数:',np.round(beta_hat,4))#四舍五入取小数点后4位
print('回归方程:Y_hat=%0.4f+%0.4f*X1+%0.4f*X2+%0.4f*X3' % (beta_hat[0],beta_hat[1],beta_hat[2],beta_hat[3]))

1.2 决定系数:R²与调整后R²
主要作用:检验回归模型的显著性
#因变量的回归值=np.dot(X_model,系数向量)
y_hat = np.dot(X_model,beta_hat)#回归值(拟合值)的计算
y_mean = np.mean(y)#求因变量的平均值
sst = sum((y-y_mean)**2)#总平方和:即y减去y均值后差的平方和
ssr = sum((y_hat-y_mean)**2)#回归平方和:y回归值减去y均值后差的平方和
#sse = sum((y-y_hat)**2)#残差平方和:y值减去y回归值之差的平方和
sse = sum(results.resid**2)#结果和上面注释了的式子一样,或许有小数点的误差,但基本上可忽略不计
R_squared =1 - sse/sst#R²:1减去残差平方和除以总平方和商的差;求解方法二:R²=ssr/sst
#按照线性回归模型原理来说:[残差平方和+回归平方和=总平方和]→[R²=ssr/sst]
print('R方:',round(R_squared,3))
#调整后平方和:100表示样本数据总数(n),3表示自变量个数(p)
adjR_squared =1- (sse/(100-3-1))/(sst/(100-1))#1-(残差的平方和/残差的自由度)/(总平方和/无偏估计)
#残差的自由度也是残差方差的无偏估计
print('调整后R方:',round(adjR_squared,3))

0≤R²≤1 R²>8说明模型显著性强 60.05就说明显著性很低,上图截距项的p值=0.329远大于0.05,所以不能拒绝原假设,也就是可以去掉截距项
1.7 回归系数的置信区间

'''
回归系数置信区间计算公式:
betahat_i - t.ppf(1-alpha/2,n-p-1)*sigma_unb*C_diag[0]**(1/2)
< =beta_i 10即判定自变量存在多重共线性;StatsModels将阈值设为5。
'''
from statsmodels.stats.outliers_influence import variance_inflation_factor
for i in range(X.shape[1]):
print('x%d的VIF:%0.4f'%(i,variance_inflation_factor(X,i)))
#计算第i个自变量的VIF,比如i=1
k_vars = X.shape[1]#提取列数,即自变量个数
x_1 = X[:, 1]
mask = np.arange(k_vars) != 1
x_not1 = X[:, mask]
#以第i个自变量作为因变量,其他自变量作为自变量调用OLS,然后提取Rsquared_i
r_squared_1 = sm.OLS(x_1, x_not1).fit().rsquared
vif_i1= 1. / (1. - r_squared_1)
print('手动计算自变量VIF(x1):',vif_i1)

1.13 附录
'''
说明:查阅有关通过范数计算条件数的资料,都是用矩阵的范数乘以该矩阵逆的范数,都无开平方这个计算步骤。
statsmodels的开平方这个计算步骤不知是何用意?暂时还没弄明白。
示例:https://blog.csdn.net/qq_18343569/article/details/50404989
'''
m=np.array([[3,5,0],[2,10,4],[3,4,5]])
#m = np.asmatrix(a)
np.linalg.norm(m,ord=2)*np.linalg.norm(np.linalg.inv(m),ord=2)#norm(需要计算的矩阵,ord=2):计算矩阵的范数,ord表面使用的谱范数中的2-范数

'''
泛函分析中的范数计算.
谱范数的2-范数(注意与l2范数区别):等于矩阵的共轭转置和自身的点积生成矩阵的特征值中的最大值开平方。
很显然:np.linalg.norm(matrix,ord=2)等中的ord=2表示计算矩阵的2-范数。
'''
eigs_norm = np.sqrt(np.linalg.eigh(np.dot(m.T,m))[0])
print('矩阵m的2-范数(通过公式计算):',eigs_norm.max())
norm_2 = np.linalg.norm(m,ord=2)
print('矩阵m的2-范数(调用numpy函数):',norm_2)

'''
l2范数计算与谱范数的2-范数计算有区别:前者表示矩阵元素平方和,然后再开平方,如下例所示:
'''
l2norm_byhand = np.sqrt(np.sum(m**2))
print('手工计算l2norm:',l2norm_byhand)
l2norm_bynormfunc = np.linalg.norm(m)#如果ord为空,缺省即l2范数
print('通过norm函数计算l2norm:',l2norm_bynormfunc)

#多维数组,*乘法是逐个元素相乘
m*m

m@m#矩阵点积

m1 = np.asmatrix(m)
#如果将多维数组转换成矩阵,*乘法就是矩阵乘法——点积
m1*m1

#@也是矩阵乘法,对于多维数组和矩阵是一样的。
m1@m1
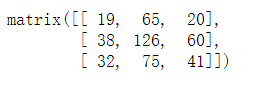
#多维数组支持转置但是不支持共轭转置。对于实数矩阵,转置和共轭转置的结果相同
print('多维数组的转置:', m.T)
m.H #求数组的共轭转置的话就会发生异常

#矩阵支持共轭转置
m1.H
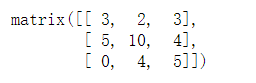
多元线性回归分析:归因和预测问题,y连续,x分类glm,R² 1、图形:散点图(y和x之间的关系)异常、线性关系、稀疏问题、相关强弱 2、相关:系数大小:0.1以上才有关系、 3、回归:R²(0.35-0.5),系数p,共线性超过900就要处理 4、残差:正态、异方差、异常值、内生性。 5、判断什么是主要原因1?——内生 6、处理内生性,——R²系数,残差 7、判断什么是主要原因2?——异常 8、处理异常值,——R²系数、残差
|