2 |
您所在的位置:网站首页 › 个推大数据官网 › 2 |
2
|
那些地方会用到post请求;
1 登陆,注册 2 需要传输大文本的时候 http://www.cnblogs.com/wupeiqi/articles/6283017.html最基本post方法: response = requests.post("http://www.baidu.com/", data = data)
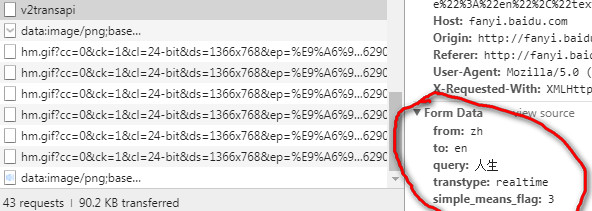
传入data数据对于 POST 请求来说,我们一般需要为它增加一些参数。那么最基本的传参方法可以利用 data 这个参数。 百度翻译案例需要传送的data
data = { 'from': 'zh', 'to': 'en', 'query': self.query_string, 'transtype': 'enter', 'simple_means_flag': '3' }   import requests
import json
# 发送请求
# 提取数据
class fanyi(object):
def __init__(self, query_sting):
self.url = 'http://fanyi.baidu.com/v2transapi'
self.query_string = query_sting
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
self.post_data = {
'from': 'zh',
'to': 'en',
'query': self.query_string,
'transtype': 'enter',
'simple_means_flag': '3'
}
# 发送请求
def send_request(self):
response = requests.post(self.url,headers=self.headers,data=self.post_data)
result = response.content.decode()
return result
# 提取数据
def get_result(self,respoonse):
dir_response = json.loads(respoonse)
ret = dir_response["trans_result"]["data"][0]["dst"]
print('{}中文的翻译的结果是:{}'.format(self.query_string,ret))
return ret
def run(self):
response = self.send_request()
result=self.get_result(response)
fan = fanyi('人生苦短,我用python')
fan.run()
View Code
import requests
import json
# 发送请求
# 提取数据
class fanyi(object):
def __init__(self, query_sting):
self.url = 'http://fanyi.baidu.com/v2transapi'
self.query_string = query_sting
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
self.post_data = {
'from': 'zh',
'to': 'en',
'query': self.query_string,
'transtype': 'enter',
'simple_means_flag': '3'
}
# 发送请求
def send_request(self):
response = requests.post(self.url,headers=self.headers,data=self.post_data)
result = response.content.decode()
return result
# 提取数据
def get_result(self,respoonse):
dir_response = json.loads(respoonse)
ret = dir_response["trans_result"]["data"][0]["dst"]
print('{}中文的翻译的结果是:{}'.format(self.query_string,ret))
return ret
def run(self):
response = self.send_request()
result=self.get_result(response)
fan = fanyi('人生苦短,我用python')
fan.run()
View Code
代理(proxies参数) 如果需要使用代理,你可以通过为任意请求方法提供 proxies 参数来配置单个请求: # 根据协议类型,选择不同的代理 proxies = { "http": "http://12.34.56.79:9527", "https": "http://12.34.56.79:9527", }
简单的实例 import requests url = 'http://www.baidu.com' # 代理的格式 proxies = { 'http': 'http://221.204.67.11:80' } r = requests.get(url=url, proxies=proxies) print(r.status_code) cookie和session区别:1 cookie数据存放在客户的浏览器上,session数据放在服务器上。 2 cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗。 3 session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能。 4 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。 带上cookie、session的好处:能够请求到登录之后的页面 带上cookie、session的弊端:一套cookie和session往往和一个用户对应 请求太快,请求次数太多,容易被服务器识别为爬虫 不需要cookie的时候尽量不去使用cookie 但是为了获取登录之后的页面,我们必须发送带有cookies的请求 处理cookies 、session请求requests 提供了一个叫做session类,来实现客户端和服务端的会话保持。 使用方法: 实例化一个session对象 让session发送get或者post请求 session = requests.session() response = session.get(url,headers) 动手尝试使用session来登录人人网: http://www.renren.com/PLogin.do 案例1 创建一个session类,来保存cookie的值 第二次是登陆个人主页的时候自动保存了,上次登陆的cookie值,在这里通过提取主页的关键字,确定访问成功
import requests
import re
url = "http://www.renren.com/PLogin.do"
post_data = {"email":"18001225173", "password":"zhangbiao"}
session=requests.session()
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
}
session.post(url,data=post_data,headers=headers)
r=session.get("http://www.renren.com/327550029/profile",headers=headers)
print(re.findall('张彪',r.content.decode()))
View Code
案例2 在请求的headers携带cookie取访问登陆后的页面 import requests import re url = 'http://www.renren.com/327550029/profile' headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36", "Cookie":'anonymid=j8k2lo0cxzvxt2; _r01_=1; springskin=set; depovince=BJ; ap=327550029; jebecookies=9ba25af9-0706-4623-9ea0-83d064f51d45|||||; JSESSIONID=abcWUIp_Z9JIM4_7ZqT9v; ick_login=dd642771-67fe-4c8d-8723-feba9f943b44; _de=4C18B740AFB5CCB88B0E53151F00BFFB; p=dc5a8371b38db2e3b0e8bea58df8a48b1; first_login_flag=1; ln_uact=18001225173; ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; t=00c94770db65dae5760421d21b56b2361; societyguester=00c94770db65dae5760421d21b56b2361; id=960734501; xnsid=92bc34e3; loginfrom=syshome; jebe_key=2ff56a05-2652-4c54-8909-d01e81823bdf%7C82e55f2a2ce39101d6374a335abf18de%7C1509366690724%7C1%7C1509366686405; wp_fold=0', } response=requests.get(url=url,headers=headers) print(re.findall('张彪',response.content.decode()))
案例 3 把cookies当做一个参数去访问登陆的页面 import requests import re url = 'http://www.renren.com/327550029/profile' headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36", } cookies = 'anonymid=j8k2lo0cxzvxt2; _r01_=1; springskin=set; depovince=BJ; ap=327550029; jebecookies=9ba25af9-0706-4623-9ea0-83d064f51d45|||||; JSESSIONID=abcWUIp_Z9JIM4_7ZqT9v; ick_login=dd642771-67fe-4c8d-8723-feba9f943b44; _de=4C18B740AFB5CCB88B0E53151F00BFFB; p=dc5a8371b38db2e3b0e8bea58df8a48b1; first_login_flag=1; ln_uact=18001225173; ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; t=00c94770db65dae5760421d21b56b2361; societyguester=00c94770db65dae5760421d21b56b2361; id=960734501; xnsid=92bc34e3; loginfrom=syshome; jebe_key=2ff56a05-2652-4c54-8909-d01e81823bdf%7C82e55f2a2ce39101d6374a335abf18de%7C1509366690724%7C1%7C1509366686405; wp_fold=0' cookies = { i.split('=')[0]:i.split('=')[-1] for i in cookies.split('; ')} response=requests.get(url=url,headers=headers,cookies=cookies) print(re.findall('张彪',response.content.decode()))
Requests也可以为HTTPS请求验证SSL证书:要想检查某个主机的SSL证书,你可以使用 verify 参数(也可以不写) import requests response = requests.get("https://www.baidu.com/", verify=True) # 也可以省略不写 # response = requests.get("https://www.baidu.com/") print r.text
如果SSL证书验证不通过,或者不信任服务器的安全证书,则会报出SSLError,据说 12306 证书是自己做的: 来测试一下: import requests r=requests.get("https://www.12306.cn/mormhweb/ ") print(r.content.decode()) 如果我们想跳过 12306 的证书验证,把 verify 设置为 False 就可以正常请求了。 import requests r=requests.get("https://www.12306.cn/mormhweb/ ", verify=False) # r=requests.get("https://www.12306.cn/mormhweb/ ") print(r.content.decode()) 设置超时配合状态码判断是否请求成功 response = requests.get(url,timeout=10) assert response.status_code == 200
# coding=utf-8
import requests
from retrying import retry
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"}
@retry(stop_max_attempt_number=3)
def _parse_url(url):
print("*"*10)
r = requests.get(url,headers=headers,timeout=5)
assert r.status_code == 200
return r.content.decode()
def parse_url(url):
try:
html = _parse_url(url)
except:
html = None
return html
if __name__ == '__main__':
# url = "https://www.baidu.com"
url = "www.baidu.com"
ret = parse_url(url)
if ret is not None:
print(ret[:100])
else:
print("error")
View Code
json的使用
import json
# 把字典转换成json的格式
json.loads()
# 把json的数据转换成字典
json.dumps()
爬取豆瓣的电影
找到豆瓣的返回的json数据 1 切换到手机的模式 2 获取json的数据地址 https://m.douban.com/rexxar/api/v2/subject_collection/movie_showing/items?os=ios&for_mobile=1&callback=jsonp1&start=0&count=18
import requests
import json
url = "https://m.douban.com/rexxar/api/v2/subject_collection/movie_showing/items?start=0&count=18"
response = requests.get(url)
# 这是一个字符串
r = response.content.decode()
# print(type(r))
# 把字符串转换成字典
dic_o = json.loads(r)
# print(type(dic_o))
with open('move.html','w') as f:
f.write(json.dumps(dic_o,ensure_ascii=False,indent=2))
with open('move.html','r') as f:
# 这里可以直接的print(f.read())打印的是字符串
t = json.loads(f.read())
print(type(t))
print(t)
View Code
|



【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |