2017 |
您所在的位置:网站首页 › 世界各国gdp占世界比 › 2017 |
2017
|
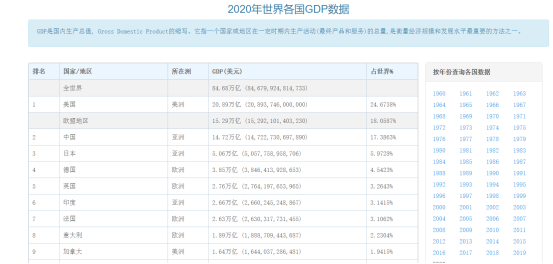
2017-2020年世界各国GDP数据爬取 一、选题的背景 通过爬取2017-2020年世界各国历年来的GDP数据,对爬取得到的数据进行数据清洗提取得到可以利用的数据,并绘制图表进行分析疫情前后的GDP走势,以及各大洲的GDP占比情况等,进一步探究世界各国、各大洲的发展情况,和研究疫情对各个国家、洲的影响程度。 二、设计方案 1.主题式网络爬虫名称: 2017-2020年世界各国GDP数据爬取 2.主题式网络爬虫爬取的内容与数据特征分析 爬取世界各国GDP网站得到国家、洲、GDP、世界占比、年份等数据,然后存储到csv文件中。 3.主题式网络爬虫设计方案概述 实现思路:先确定主题,数据的爬取,使用的是python里面的requests库,这个库可以对网站发起请求获取到对应的数据,再利用lxml库使用xpath技术解析出我们要的数据,再利用Matplotlib等库进行绘制可视化图,然后存储到本地。 技术难点:Html页面的解析及爬取过程中的文件保存。 三、主题页面的结构特征分析 1.主题页面的结构与特征分析 顺序结构:先通过requests爬取2017年-2020年世界全国GDP值,再用csv保存数据,最后读取数据进行可视化。 数据来源:https://www.kylc.com/stats/global/yearly/g_gdp/2020.html 该页面由div,td,tr等组成的世界各国GDP网html页面程序代码。 2.Htmls页面解析
所需页面代码:
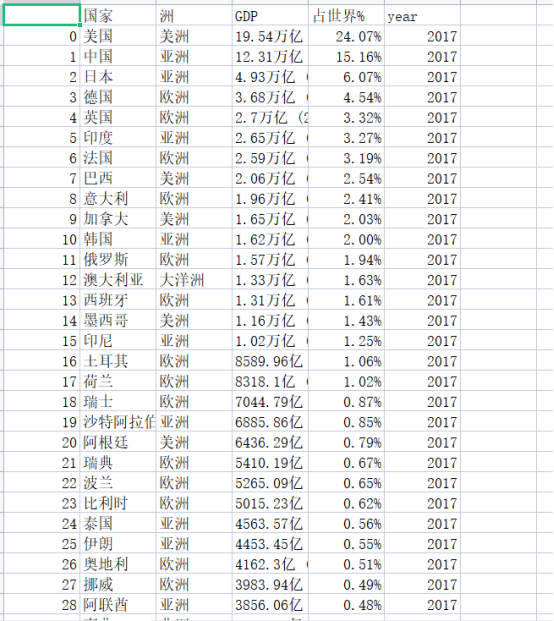
3.节点(标签)查找方法与遍历方法 查找方式:find 遍历方式:for循环 四、实现步骤及代码 1.数据爬取与采集 import requests from lxml import etree import pandas as pd import matplotlib.pyplot as plt import warnings #忽略警告 warnings.filterwarnings("ignore") #显示中文 plt.rcParams['font.sans-serif'] = ['SimHei'] #浏览器的UA headers = {'User-Agent':'Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)'} def get_data(url): for n in range(20): try: dfs=requests.get(url,headers=headers,timeout= 5,verify=False).text except Exception: pass else: break return dfs #新建表格存储数据 datas = pd.DataFrame() #循环爬取每一年的数据 for year in range(2017,2021): print(year) #构造链接 url1 = 'https://www.kylc.com/stats/global/yearly/g_gdp/'+str(year)+'.html' #获取网页源码 df1 = get_data(url1) #转化为HTML格式数据 html1 = etree.HTML(df1) #提取对应数据 df1 = html1.xpath('//tbody/tr/td[2]/text()') df2 = html1.xpath('//tbody/tr/td[3]/text()') df3 = html1.xpath('//tbody/tr/td[4]/text()') df4 = html1.xpath('//tbody/tr/td[5]/text()') #找到不要的数据标签 index1 = df1.index('全世界') #删除数据 del df1[index1] del df3[index1] del df4[index1] index2 = df1.index('欧盟地区') del df1[index2] del df3[index2] del df4[index2] print(df1) print(df2) print(df3) print(df4) #存入dataframe表格 data = pd.DataFrame() data['国家'] = df1 data['洲'] = df2 data['GDP'] = df3 data['占世界%'] = df4 data['year'] = year #合并到大表格 datas = pd.concat([datas,data]) datas.to_csv('D:/数据.csv') df=pd.read_csv('D:/数据.csv') df
爬取运行生成一个csv文件:
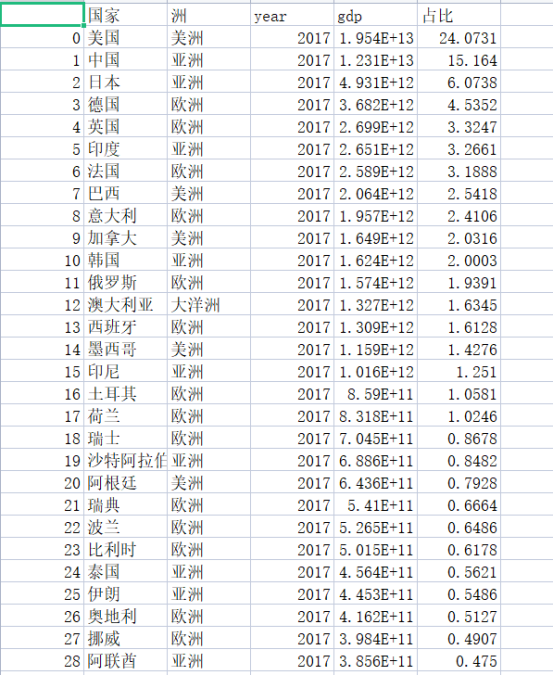
2.对数据进行清洗和处理 #清洗数据 datas['gdp']=datas['GDP'].map(lambda x:float(x.split('(')[-1].split(')')[0].replace(',',''))) #去掉占比的百分号 datas['占比'] = datas['占世界%'].map(lambda x:float(x.replace('%',''))) #去掉不要的列 datas.drop(['GDP','占世界%'],axis = 1,inplace = True) #存入csv中 datas.to_csv('D:/清洗后数据.csv') d=pd.read_csv('D:/清洗后数据.csv') d 清洗后得到的csv文件:
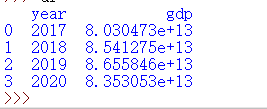
3.数据分析与可视化 df = datas.groupby('year')[['gdp']].sum().reset_index() df
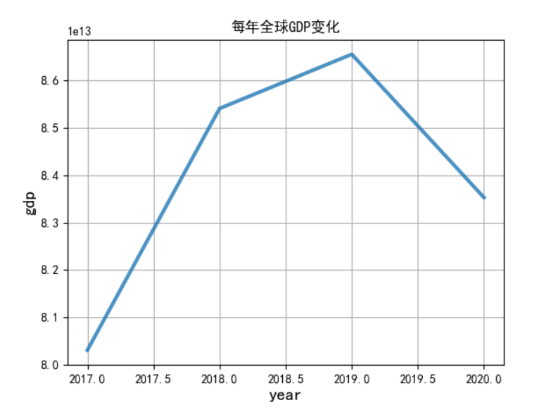
#绘制折线图x轴和y轴,透明度为0.8,线条宽度为3 plt.plot(df['year'],df['gdp'],alpha=0.8,linewidth = 3) #添加x轴标签、y轴标签和标签 plt.xlabel("year",fontsize=14) plt.ylabel('gdp',fontsize=14) plt.title('每年全球GDP变化') # 生成网格 plt.grid() #显示图像 plt.show()
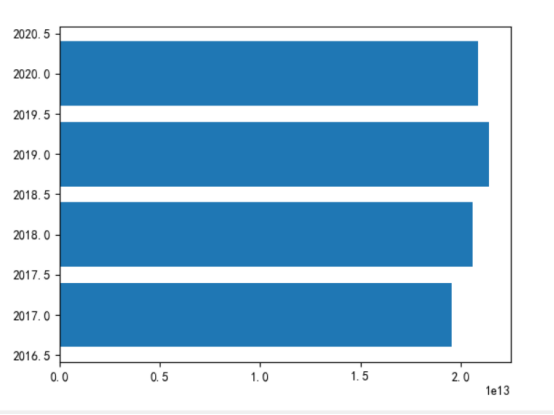
#绘制水平柱状图 plt.barh(d['year'],d['gdp'],label='2017年-2020年世界全国GDP值') #显示图像 plt.show()
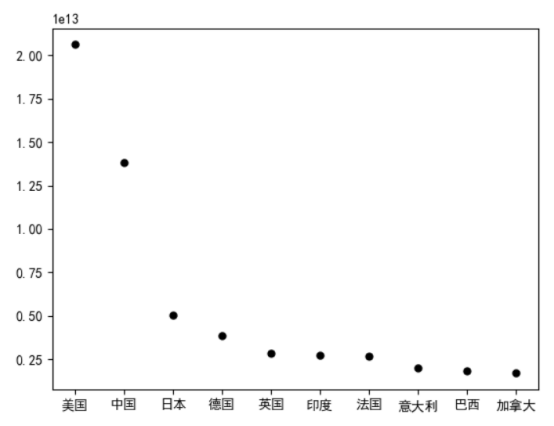
#看看历年gdp均值排名前10的国家 df1 = datas.groupby('国家')[['gdp']].mean().reset_index().sort_values(by = 'gdp',ascending = False).iloc[:10] df1
#绘制柱状图 #创建figure对象,宽10英寸,高6英寸 plt.figure(figsize = (10,6)) #绘制柱状图,透明度为0.8 plt.bar(df1['国家'],df1['gdp'],alpha=0.8) #添加x轴标签、y轴标签和标题标签 plt.xlabel("国家",fontsize=14) plt.ylabel('gdp',fontsize=14) plt.title('GDP均值国家排名TOP10') # 生成网格 plt.grid() #x轴标签旋转90度 plt.xticks(rotation=90) #显示图像 plt.show()
#绘制散点图 plt.scatter(df1['国家'],df1['gdp'],color='k',s=25,marker="o") #显示图像 plt.show()
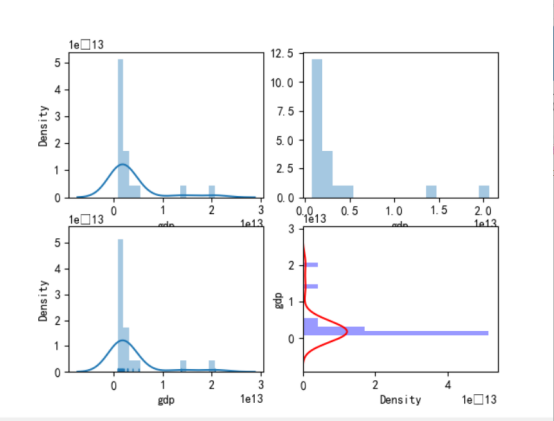
#绘制直方图 import seaborn as sns sns.distplot(df1['gdp']) fig,axes=plt.subplots(2,2) #默认绘图效果 sns.distplot(df1['gdp'],ax=axes[0][0]) #kde=False:不显示密度曲线 sns.distplot(df1['gdp'],kde=False,ax=axes[0][1]) #rug=True:在坐标轴上添加地毯图 sns.distplot(df1['gdp'],rug=True,ax=axes[1][0]) #调节vertical\hist_kws和kde_kws参数,改变直方图方向、坐标轴和密度曲线颜色 sns.distplot(df1['gdp'],vertical=True,hist_kws={'color':'blue','label':'hist'},kde_kws = {'color':'red','label':'KDE'},ax=axes[1][1]) #显示图像 plt.show()
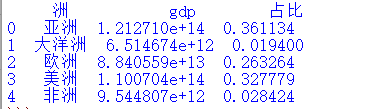
#五大洲历年GDP总和 df2 = datas.groupby('洲')[['gdp']].sum().reset_index() df2['占比'] = df2['gdp']/df2['gdp'].sum() df2
#绘制小提琴 sns.violinplot(df2['gdp']) #显示图像 plt.show()
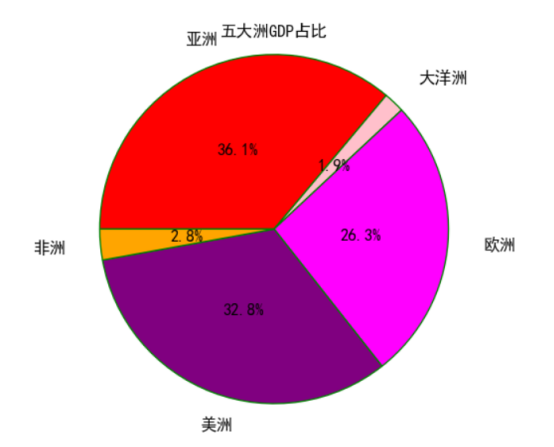
#绘制扇形图 #准备数据 values = list(df2['占比']) #准备标签 labels = list(df2['洲']) #使用自定义颜色 colors = ['red','pink','magenta','purple','orange'] #将横、纵坐标轴标准化处理,保证饼图是一个正圆,否则为椭圆 plt.axes(aspect='equal') #控制X轴和Y轴的范围(用于控制饼图的圆心、半径) plt.xlim(0,8) plt.ylim(0,8) #不显示边框 plt.gca().spines['right'].set_color('none') plt.gca().spines['top'].set_color('none') plt.gca().spines['left'].set_color('none') plt.gca().spines['bottom'].set_color('none') #绘制饼图 plt.pie(x=values, #绘制数据 labels=labels,#添加编程语言标签 colors=colors, #设置自定义填充色 autopct='%.1f%%',#设置百分比的格式,保留3位小数 pctdistance=0.5, #设置百分比标签和圆心的距离 labeldistance=1.2,#设置标签和圆心的距离 startangle=180,#设置饼图的初始角度 center=(4,4),#设置饼图的圆心(相当于X轴和Y轴的范围) radius=3.8,#设置饼图的半径(相当于X轴和Y轴的范围) counterclock= False,#是否为逆时针方向,False表示顺时针方向 wedgeprops= {'linewidth':1,'edgecolor':'green'},#设置饼图内外边界的属性值 textprops= {'fontsize':12,'color':'black'},#设置文本标签的属性值 frame=1)#是否显示饼图的圆圈,1为显示 #不显示X轴、Y轴的刻度值 plt.xticks(()) plt.yticks(()) #添加图形标题 plt.title('五大洲GDP占比') #显示图形 plt.show()
#绘制地图 import pygal import pygal_maps_world.maps from pygal.style import RotateStyle from pygal.style import LightColorizedStyle #创建一个字典 cy_GDP={} cy_GDP1,cy_GDP2,cy_GDP3={},{},{} #将df1中gdp存入cy_GDP cy_GDP=df1['gdp'] for c,GDP in cy_GDP.items(): if GDP |




【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |