Python爬取《流浪地球》豆瓣影评与数据分析可视化 |
您所在的位置:网站首页 › 《夺冠》豆瓣影评分析与评价 › Python爬取《流浪地球》豆瓣影评与数据分析可视化 |
Python爬取《流浪地球》豆瓣影评与数据分析可视化
|
大年初一《流浪地球》全国上映。在豆瓣评分上,首日开分站稳8分以上,延续了之前点映的高口碑。微博上跟着出现吴京客串31天与投资6000万的热搜。知乎上关于“如何评价刘慈欣小说改编的同名电影《流浪地球》”的回答引起了众多人关注,包括该片导演郭帆的最高赞回答。 本篇文章爬取了豆瓣网上《流浪地球》的部分影评,并进行数据分析及可视化处理。下面是爬取分析的整个过程,让我们愉快开始吧! 一、网页分析 豆瓣网从2017年10月开始全面禁止爬取数据。在非登录状态下仅仅可以爬取200条短评,登录状态下仅可以爬取500条数据。白天一分钟最多可爬40次,晚上60次,超过次数就会封IP地址。小本聪爬取数据获得400条时被封了IP,账号被强制下线封号,之后发短信账号恢复,因此不建议多次爬取(另外,有很多解决方法,请自行搜索)。 获取对象 评论用户 评论内容 评分 评论日期 用户所在城市
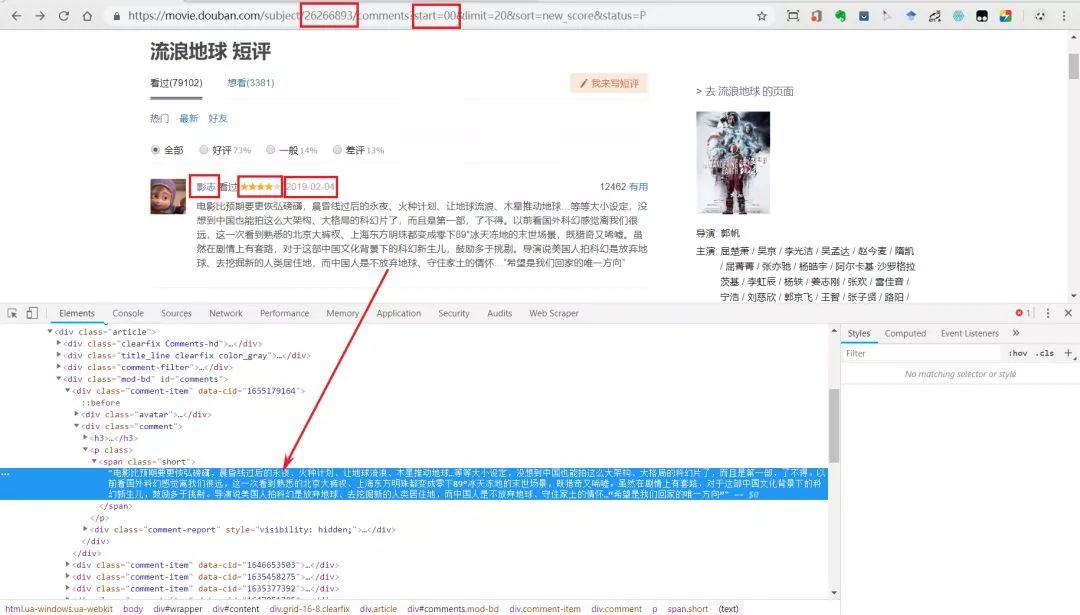
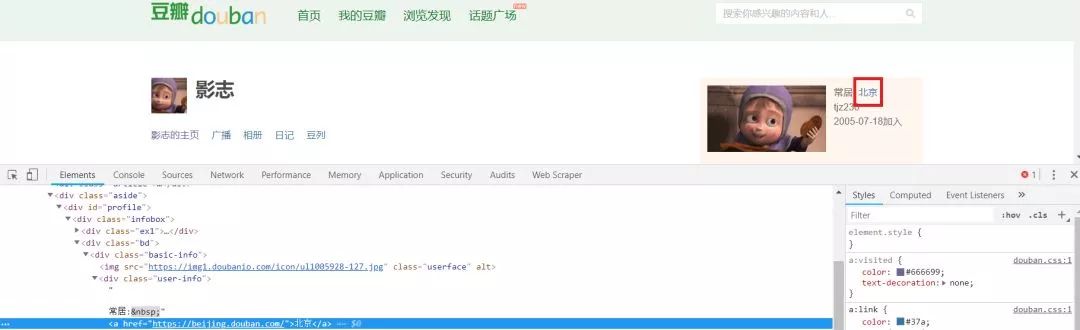
值得注意的是,在地址栏我们会发现电影名字的ID编号为26266893(其他电影只需更换ID即可),并且每页有20条短评,因此我爬取了20页。评论页面没有用户所在城市,需要进入用户页面获取信息。
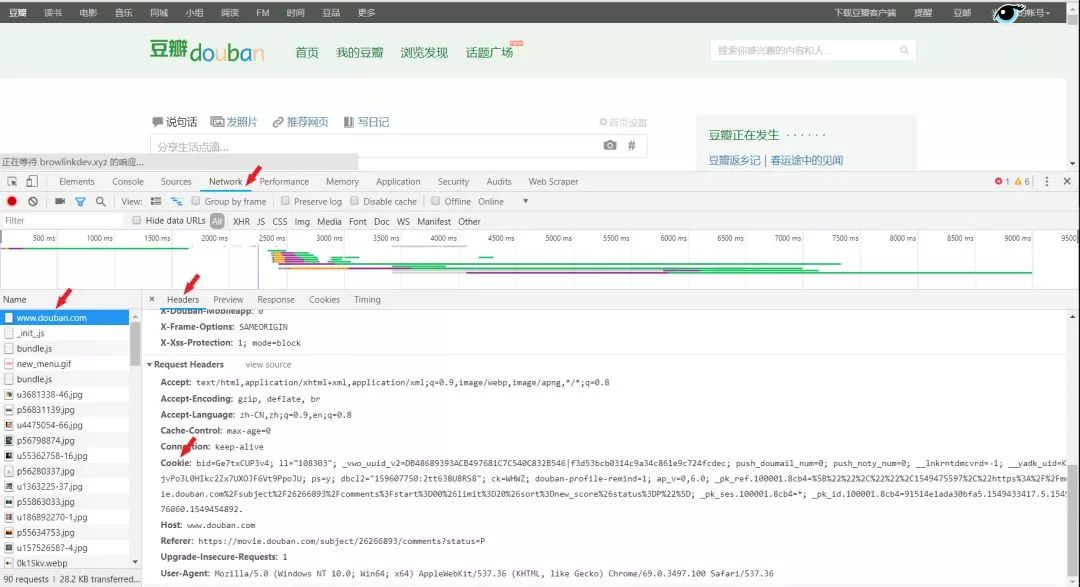
二、数据获取与存储 1 获取cookies 小本聪用的是Chrome浏览器,Ctrl+F12进入开发者工具页面。F5刷新一下出现数据,找到cookies、headers。
2 加载headers、cookies,并用requests库获取信息 def get_content(id, page): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'} cookies = {'cookie': 'bid=GOOb4vXwNcc; douban-fav-remind=1; ps=y; ue="[email protected]"; push_noty_num=0; push_doumail_num=0; ap=1; ll="108288"; dbcl2="181095881:BSb6IVAXxCI"; ck=Fd1S; ct=y'} url = "https://movie.douban.com/subject/" + str(id) + "/comments?start=" + str(page * 10) + "&limit=20&sort=new_score&status=P" res = requests.get(url, headers=headers, cookies=cookies) [/code] **3 解析需求数据** 此处运用xpath解析。发现有的用户虽然给了评论,但是没有给评分,所以score和date这两个的xpath位置是会变动的。因此需要加判断,如果发现score里面解析的是日期,证明该条评论没有给出评分。 ```code for i in range(1, 21): # 每页20个评论用户 name = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/text()'.format(i)) # 下面是个大bug,如果有的人没有评分,但是评论了,那么score解析出来是日期,而日期所在位置spen[3]为空 score = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[2]/@title'. |

【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |