目标检测 |
您所在的位置:网站首页 › yolov3目标检测的准确率计算公式 › 目标检测 |
目标检测
|
论文:YOLOv3:An Incremental Improvement 作者:Joseph Redmon, Ali Farhadi 链接:https://arxiv.org/abs/1804.02767 代码:http://pjreddie.com/yolo/ YOLO系列算法解读: YOLOv1通俗易懂版解读、SSD算法解读、YOLOv2算法解读、YOLOv3算法解读、YOLOv4算法解读、YOLOv5算法解读、YOLOR算法解读、YOLOX算法解读、YOLOv6算法解读、YOLOv7算法解读、YOLOv8算法解读、YOLOv9算法解读、YOLOv10算法解读 PP-YOLO系列算法解读: PP-YOLO算法解读、PP-YOLOv2算法解读、PP-PicoDet算法解读、PP-YOLOE算法解读、PP-YOLOE-R算法解读 文章目录 1、算法概述2、YOLOv3细节2.1 Bounding Box Prediction2.2 Class Prediction2.3 Predictions Across Scales2.4 Features Extractor2.5 Training 3、实验4、创新点和不足 1、算法概述YOLOv3在前面YOLOv2的基础上做出重大改进,包括采用新设计的backbone,边界框预测方式和多尺度特征预测等等,总得来说,YOLOv3在吸收之前的检测算法经验对YOLOv2进行改进,直接上图: 与YOLOv2一样,网络为每个边界框预测四个坐标tx、ty、tw和th;假如图像左上角格子偏移量为(cx,cy),bounding box prior的宽高为pw,ph,则边界框的坐标可以通过公式计算为: 不再用softmax分类了,改为二元交叉熵损失,每个类独立使用logistic分类器;这样做的好处是训练的时候可以引入更复杂的数据集,不再受限制于他们的标签必须是独立互斥的关系。 2.3 Predictions Across ScalesYOLOv3这次结合3个不同尺度的特征图进行预测,每个尺度设置3个anchor boxes,对于在COCO数据集上的实验,NxN大小的特征图输出结果为NxNx[3x(4+1+80)],即每个grid设置3个anchor,每个anchor预测4个bounding box偏置和1个objectness分数以及80个类别分数。 最后的特征图还会经过x2倍上采样与上一个特征融合得到另一个较大尺度的特征图,从而丰富了语义特征;与YOLOv2一样,anchor也做了k-means聚类,得到9个anchor大小,用于设置在3个尺度特征图上。完整YOLOv3网络结构图如下(图片来自”A COMPREHENSIVE REVIEW OF YOLO: FROM YOLOV1 AND BEYOND”) YOLOv3设计了新的backbone用于提取特征,通过连续的设置3x3和1x1的卷积层,并且带一些跳转连接,总共包含53个卷积层,作者叫它Darknet-53。其结构如下: 用完整图像进行训练,不带有难度样本挖掘,多尺度训练,数据增强,batch normalization。 3、实验就COCO测试集上的平均AP指标而言,YOLOv3与SSD变体算法相当,但速度快3倍。过去,YOLO在处理小目标时遇到了困难。然而,现在我们看到了这一趋势的逆转。通过结合多尺度预测,我们看到YOLOv3具有相对较高的APs的性能。但是,它在中型和大型目标对象上的性能相对较差。 创新点: 1、基于v2的版本做了很多改进,设计了高效的Darknet-53网络,采用了多尺度特征预测,特征融合技术。 不足: 1、小目标方面,由于多尺度的预测有提升,中型目标和大型目标还不是很理想。 |
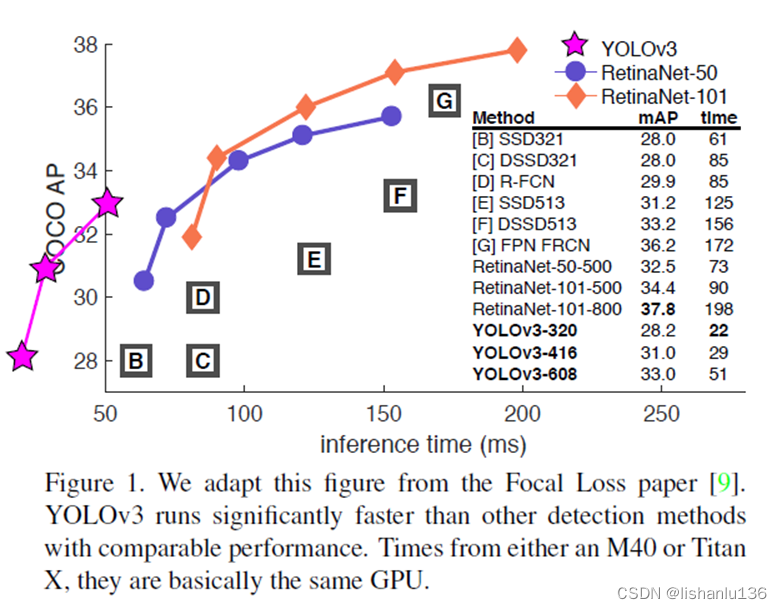 从图中可以看出,YOLOv3-320和SSD在相同输入尺度下,mAP相差不大,但推理速度,YOLOv3-320比SSD快3倍。
从图中可以看出,YOLOv3-320和SSD在相同输入尺度下,mAP相差不大,但推理速度,YOLOv3-320比SSD快3倍。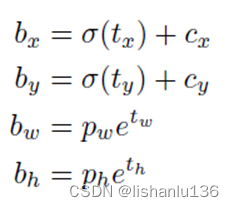 回归这四个坐标采用平方和误差(sum of squared error loss)。但是,这一次YOLOv3使用逻辑回归为每个边界框预测一个物体性分数(objectness score)。该分数对于与ground trunth box有最高重叠的锚框(bounding box prior)为1,对于其余锚框为0。与Faster R-CNN不同,YOLOv3仅为每个ground trunth box对象分配一个锚框。如果没有将锚框分配给ground trunth box对象,则该锚框不会对坐标或类预测造成损失,只会对对象(objectness)造成损失。
回归这四个坐标采用平方和误差(sum of squared error loss)。但是,这一次YOLOv3使用逻辑回归为每个边界框预测一个物体性分数(objectness score)。该分数对于与ground trunth box有最高重叠的锚框(bounding box prior)为1,对于其余锚框为0。与Faster R-CNN不同,YOLOv3仅为每个ground trunth box对象分配一个锚框。如果没有将锚框分配给ground trunth box对象,则该锚框不会对坐标或类预测造成损失,只会对对象(objectness)造成损失。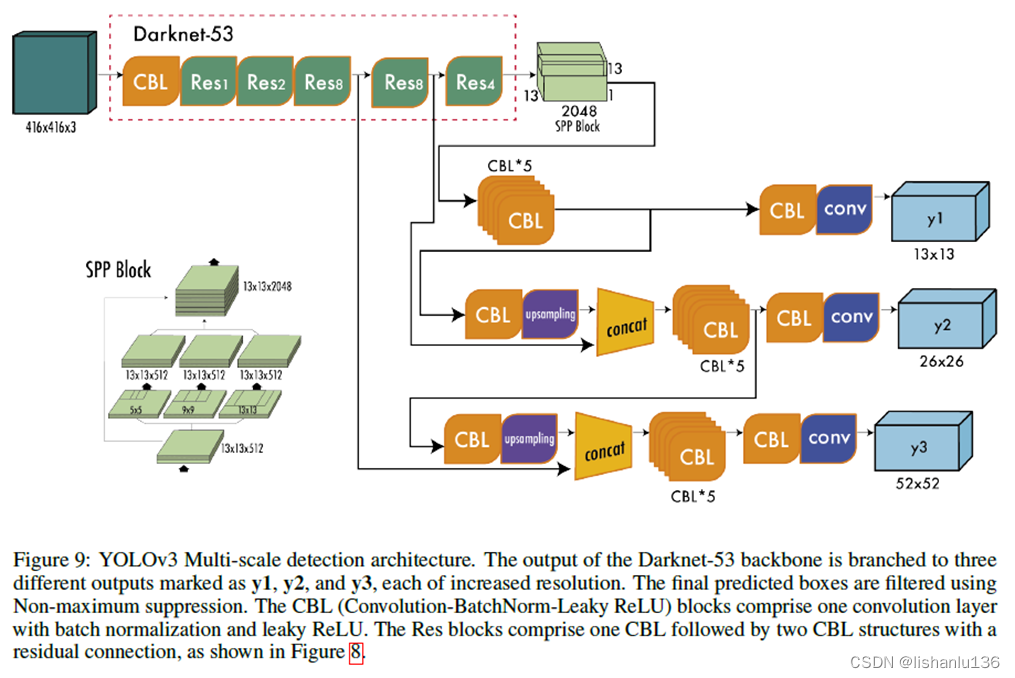
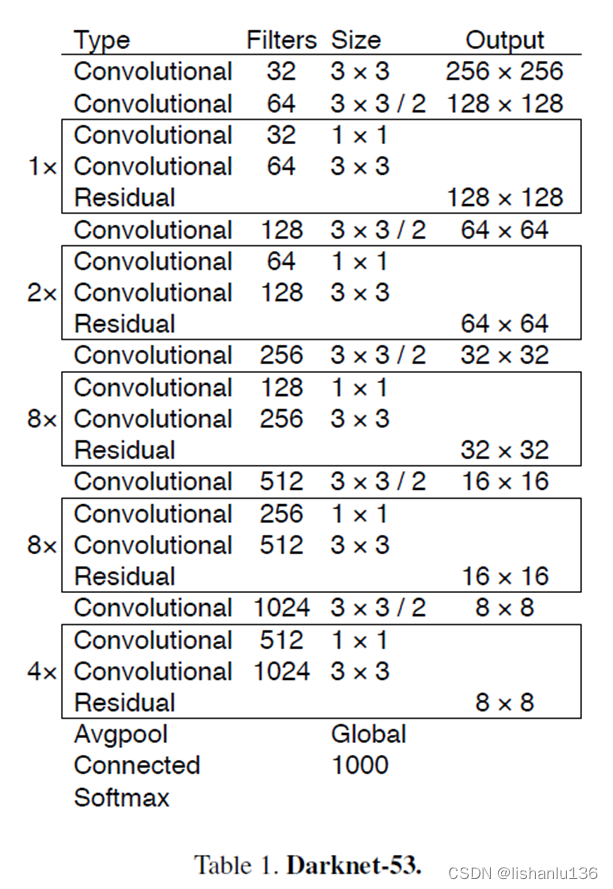 这个新网络比Darknet-19强大很多,而且比ResNet-101或ResNet-152更高效,在ImageNet数据集上的表现为:
这个新网络比Darknet-19强大很多,而且比ResNet-101或ResNet-152更高效,在ImageNet数据集上的表现为: 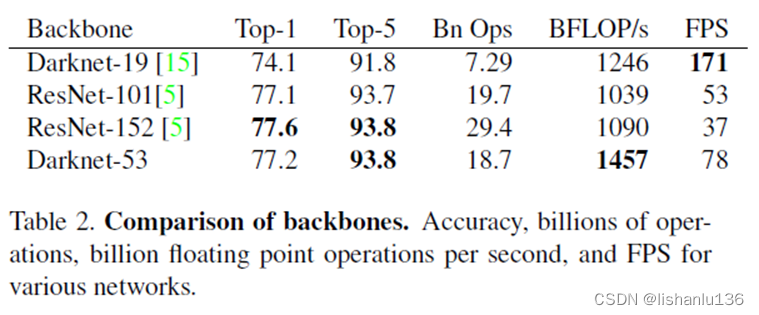 可以看到,Darknet-53骨干网络获得的Top-1和Top-5准确性与ResNet-152相当,但速度几乎快2倍。
可以看到,Darknet-53骨干网络获得的Top-1和Top-5准确性与ResNet-152相当,但速度几乎快2倍。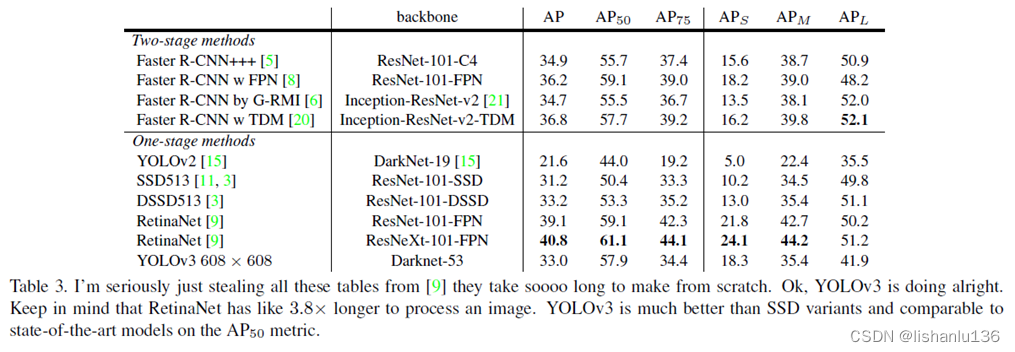
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |