词干 nltk |
您所在的位置:网站首页 › stem词干的定义 › 词干 nltk |
词干 nltk
|
When I was 14, I remember that was the age of yahoo mails. One day I received a mail claiming that I have won a car and all I have to do is to submit the money first to move forward. 当我14岁时,我记得那是Yahoo邮件的时代。 有一天,我收到一封邮件,声称我已经赢得了一辆汽车,而我所要做的就是先提交钱以继续前进。 The 14-year-old me started jumping in joy and shouting all around. This was an unusual event and everyone in my family came together. Then suddenly my uncle burst my bubble of happiness in 2 minutes. He told me, these are fake emails to grab money through illegal methods. 14岁的我开始欢欣鼓舞,到处喊。 这是不寻常的事件,我家中的每个人都聚在一起。 然后我的叔叔突然在2分钟内炸开了我的幸福泡泡。 他告诉我,这些是伪造的电子邮件,旨在通过非法手段来抢钱。 Recently, I watched Jamtara on Netflix(a must-watch series though!). I got intrigued by the series and decided to deep dive into combating spamming emails. As I am in the field of Data Science I decided to create a guide on this. 最近,我在Netflix上观看了Jamtara (不过是必看的系列!)。 我对该系列感兴趣,并决定深入研究打击垃圾邮件。 当我在数据科学领域时,我决定就此创建指南。 入门基础- (Getting into the basics-)To begin with, let’s first understand NLP: 首先,让我们首先了解NLP: Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. 自然语言处理(NLP)是语言学,计算机科学和人工智能的一个子领域,与计算机和人类语言之间的相互作用有关,尤其是如何对计算机进行编程以处理和分析大量自然语言数据。 First things first, Spam Classifier falls under the category of Supervised Learning and it is a Classification Problem because the output is either Spam or ham(not spam). 首先,垃圾邮件分类器属于“监督学习”类别,这是一个分类问题,因为输出是垃圾邮件还是火腿(不是垃圾邮件)。 Coming back there are many things to learn and work: 回到这里,有很多东西要学习和工作: 1.nltk library: It is the platform that can help us work with human language, working with fundamentals of writing programs, working with the corpus (paragraph, sentences), categorizing text, analyzing linguistic structure, and more. 1.nltk库:该平台可以帮助我们使用人类语言,编写程序的基础知识,使用语料库(段落,句子),对文本进行分类,分析语言结构等。 #To import nltk library import nltk nltk.download('stopwords')Stopwords, are the words that have no significance in giving the sentence a meaning but just help in forming it so that they make sense. To make data processing easier we eradicate them. 停用词是在赋予句子某种意义上不重要的词,而只是有助于使之有意义。 为了简化数据处理,我们将其消除。 For example: “Hurray!! You have won a gift hamper worth 5000.” As you can analyze that ‘you, have, a’ are of no significance they are just adding weight-age to our data. 例如:“万岁! 您赢得了价值5000的礼物篮。” 正如您可以分析的那样,“您拥有”并不重要,它们只是在为我们的数据增加权重。 2. Stemming and Lemmatization: Coming in terms with the acronym(slang) that we people use these days is just hysterical to me as a person and also to a machine, so NLP has come up with the concept of stemming and lemmatization, let’s dig a little bit about it. 2.词干和词法化:用当今人们使用的首字母缩写来对我个人和机器都歇斯底里,所以NLP提出了词干和词法化的概念,让我们来进行挖掘一点点。 from nltk.corpus import stopwords from nltk.stem.porter import PorterStemmer ps = PorterStemmer()# also try with lemmatizerA word with the same meaning can be written in different ways which makes it tough for the machine to understand thus stemming and lemmatization works on the same line is that they find the stem of the concerned word. For Example: 具有相同含义的单词可以用不同的方式书写,这使机器难以理解,因此词干和词根化处理在同一行上是因为它们找到了所关注单词的词干。 例如: Playing, plays, played → play 播放,播放,播放→播放 One thing that should come under your notice is the difference between the two: 您应该注意的一件事是两者之间的区别: While stemming is just concern with giving you the stem word irrespective of its meaning, whereas lemmatization will give you a word that makes sense. For example: 词干只是要与词干的含义无关,而词干化将使您觉得有意义。 例如:In stemming, history, historical will have the stem word as histori 在词根中,历史将把词干称为histori In lemmatization, the stem word will be history 在词缀化中,词干将成为历史 Another one, the processing time for lemmatization is naturally more than the processing time for stemming because it gives you a word with a meaning (To find meaning in life we need time guys!)另一个是,去词素化的处理时间自然比词干的处理时间更长,因为它给您一个带有含义的词(要在生活中找到意义,我们需要时间的帮助!)3. Swiftly moving from my lame comments to another concept which is Vectorization, we need to first convert the paragraph/ sentences to words to vectors so that the machine can understand it. 3.从我la脚的评论Swift转向另一个概念,即Vectorization ,我们需要首先将段落/句子转换为向量的单词,以便机器能够理解它。 To sum up: Tokenization → Bag of words → Vectors 概括起来:标记化→单词袋→向量 Now, again there is more than one way to do it but here one can go with BOW(Bag Of Words) or TF-IDF(Term Frequency-Inverse Document Frequency) because here our data set is not large, go with Word2Vec or Sent2Vec when the dataset is large. 现在,再次有多种方法可以做到这一点,但是这里可以使用BOW(单词袋)或TF-IDF(术语频率-反文档频率),因为这里的数据集不大,请使用Word2Vec或Sent2Vec当数据集很大时。 #creating bag of wordsfrom sklearn.feature_extraction.text import CountVectorizer #(use tf-idf model too)Not going into the mathematical interpretation but summing up the idea of both, 不进行数学解释,而是总结两者的思想, BOW gives the representation of text into the simplest form. It creates a sequence of every word present in the sentence and gives equal weight (1 if the word is present and 0 if not). BOW以最简单的形式表示文本。 它为句子中存在的每个单词创建一个序列,并赋予相等的权重(如果存在单词则为1,否则为0)。 Eg: Consider these sentences- 例如:考虑这些句子- FRIENDS is an all-time fav TV series. 朋友是史无前例的电视连续剧。 This TV series is still not liked by many. 这部电视剧仍然不被很多人喜欢。 FRIENDS is available on Netflix. 朋友可以在Netflix上找到。We are now building a vocabulary based on all the unique words from the above sentences. 现在,我们根据以上句子中的所有唯一单词来构建词汇表。 The vocabulary consists of these 17 words: ‘FRIENDS’,’ is’,’ an’,’ all’,’time’, ’ fav’,’TV’,’ series’, this,’ still’,’ not’,’ liked’,’by’,’ many’,’ available’,’ on’,’Netflix’ 词汇表由以下17个单词组成:“ FRIENDS”,“ is”,“ an”,“ all”,“ time”,“ fav”,“ TV”,“ series”,this,“ still”,“ not”, “喜欢”,“按”,“很多”,“可用”,“上”,“ Netflix” We can now take each of these words and mark their occurrence in the three movie reviews above with 1s and 0s. This will give us 3 vectors for 3 sentences: 现在,我们可以将这些单词中的每一个都用1和0标记在上面的三个电影评论中。 这将给我们3个句子的3个向量: 
Vector of Sentence 1:[11111111000000000] 句子向量1:[11111111000000000] Vector of Sentence 2:[01001011011111000] 句子2的向量:[01001011011111000] Vector of Sentence 3:[11000000000000111] 句子3的向量:[11000000000000111] So this is the core idea behind the bag of words, now as you can see there is no ordering of words which is not making sense also any addition of word will keep on increasing the vector size. 因此,这是单词袋背后的核心思想,现在您可以看到没有单词的排序是没有意义的,而且任何单词的增加都会继续增加向量的大小。 The importance of a word is not visible through this process. 在此过程中,单词的重要性不明显。 TF-IDF, on the other hand, is Term Frequency–Inverse Document Frequency is a numerical statistic that reflects the importance of a word in each sentence, unlike BOW. 另一方面,TF-IDF是术语频率-逆文档频率是一种数值统计,反映了每个句子中单词的重要性,与BOW不同。 Not going into its mathematical explanation in this, because in my project I have used BOW as over here order doesn’t have a great role to play. 在此不进行数学解释,因为在我的项目中我使用了BOW,因为在这里,订单没有太大的作用。 4. Data Visualization: Now, after all the Data Cleaning we will move forward to Data Visualization. 4.数据可视化:现在,在完成所有数据清理之后,我们将继续进行数据可视化。 Summary statistics is not the only measure to understand data we need to visualize it for better understanding. 摘要统计并不是理解数据的唯一方法,我们需要对其进行可视化以更好地理解。 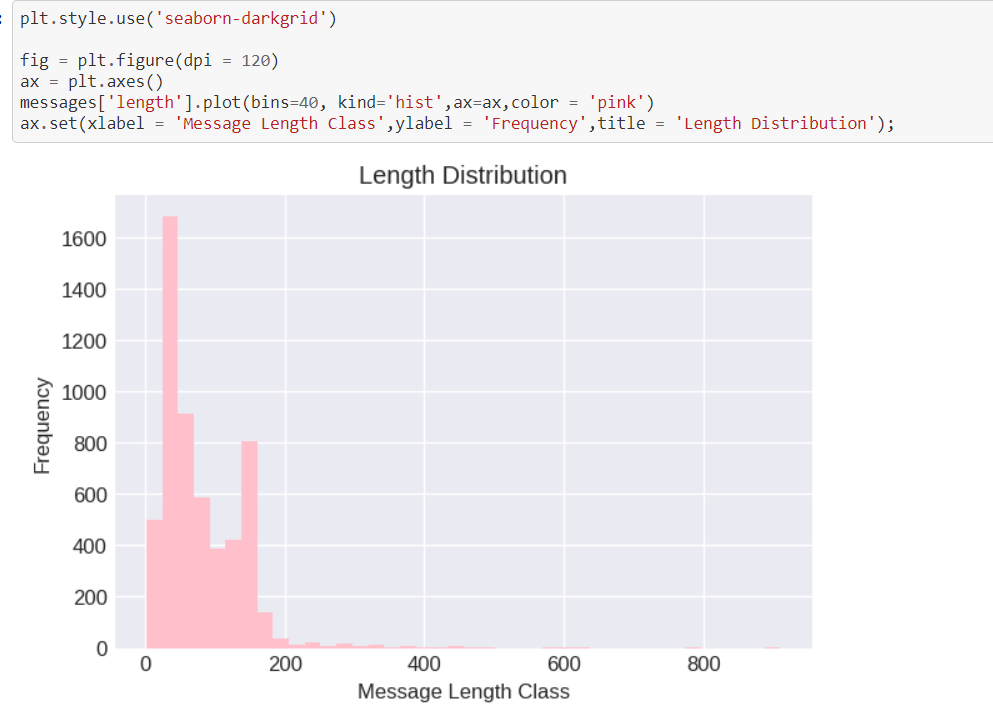
As you can see I have plotted the graph of Message Length Class v/s Frequency. It checks the frequencies of different message class lengths. 如您所见,我已经绘制了消息长度等级v / s频率的图表。 它检查不同消息类长度的频率。 As we can interpret the frequency of getting messages of length between 0 to 200 is maximum and it keeps on decreasing as the message length keeps on increasing. 正如我们可以解释的那样,获取长度在0到200之间的消息的频率是最大的,并且随着消息长度的不断增加,它不断减少。 A shorter mail is more likely to receive attention and response than a longer mail. The people reading have so much to dig through that, they’re likely to discard the message rather than read through the whole thing. 与较长的邮件相比,较短的邮件更可能引起关注和响应。 阅读的人有很多东西需要挖掘,他们很可能会丢弃信息,而不是通读整个内容。5. The final step is prediction. Here I am using Random Forest Classifier, it is the first step towards machine learning algorithms, it is an Ensemble Technique, which uses base learner (Decision Trees) where each base learner has a sample chosen by sampling with replacement technique and then the final output is given by the majority of all the base learners. 5.最后一步是预测。 在这里,我使用的是Random Forest Classifier ,这是迈向机器学习算法的第一步,它是一种集成技术,它使用基础学习器(决策树),其中每个基础学习器都有一个样本,该样本是通过使用替换技术进行采样来选择的,然后是最终输出由所有基础学习者中的大多数给予。 
Output: 输出: 
The utility of this project is we can deploy it and can check if the message or mail received is a spam or not. 该项目的实用程序是我们可以部署它,并且可以检查收到的消息或邮件是否为垃圾邮件。 I have the code for this but like me, I want you to do it first by yourself, my purpose for writing this article was to share my insights into this project. Trust me there are amazing Youtube videos and articles out there for the same. Do explore them too! 我有相应的代码,但像我一样,我希望您自己先做,我写这篇文章的目的是分享我对该项目的见解。 相信我,那里有许多出色的Youtube视频和文章。 也要探索它们! Thank you for reading this.💫 谢谢您阅读this。 LinkedIn ,email : [email protected] LinkedIn ,电子邮件: [email protected] |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |