Python实现时间序列ARIMA模型(附带超详细理论知识和完整代码实现) |
您所在的位置:网站首页 › r语言arima模型结果公式 › Python实现时间序列ARIMA模型(附带超详细理论知识和完整代码实现) |
Python实现时间序列ARIMA模型(附带超详细理论知识和完整代码实现)
|
文章目录
0 结果1 介绍2 建模2.1 预备知识2.1.1 ADF检验结果(单位根检验统计量)2.1.2 差分序列的白噪声检验(这里使用Ljung-Box检验)2.1.3 ARIMA模型(差分整合移动平均自回归模型)的三个参数:p,d,q2.1.4 自相关和偏自相关(用于识别ARMA模型)2.1.5 AIC与BIC(用于确定p,q参数)2.1.6 模型检验(残差检验, QQ图,Jarque-Bera检验,D-W检验)
2.2 建模详细过程
3 模型代码实现3.1 详细步骤3.2 完整代码
4 测试数据和完整代码5 拓展学习参考文章
0 结果
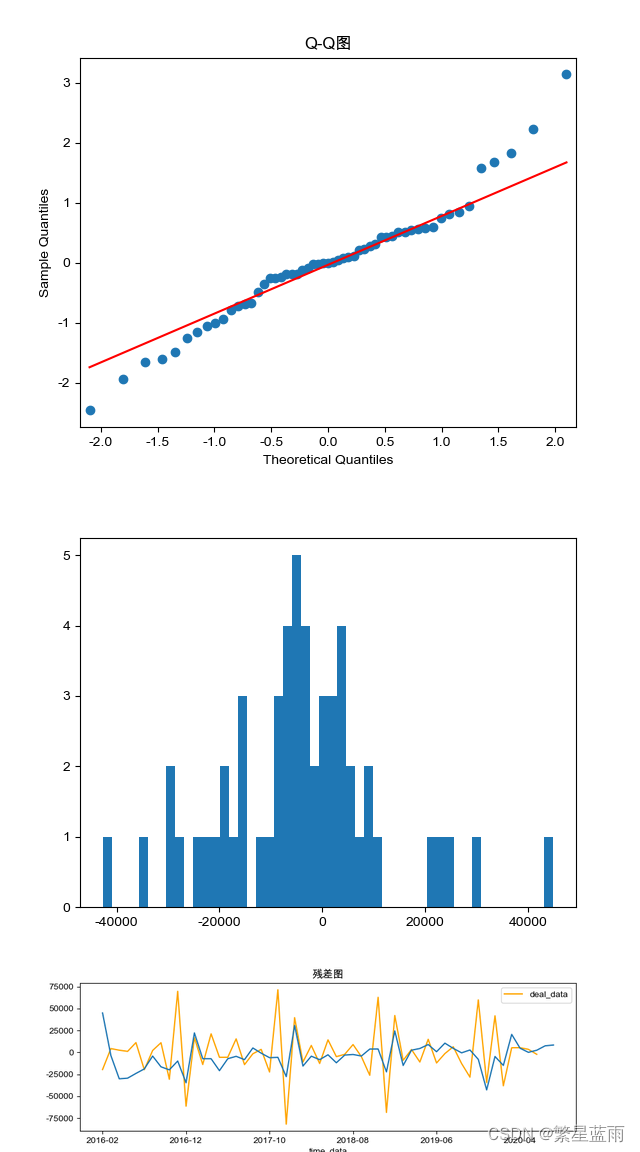
时间序列分析的基本思想:寻找系统的当前值与其过去的运行记录(观察数据)的关系,建立能够比较精确地反映时间序列中动态依存关系的数学模型,并借此对系统的未来行为进行预报。 ARIMA模型(Autoregressive Integrated Moving Average model,差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动)),是时间序列预测分析方法之一。ARIMA(p,d,q)中,AR是“自回归”,p为自回归项数;MA为“滑动平均”,q为滑动平均项数,d为使之成为平稳序列所做的差分次数(阶数)。“差分”一词虽未出现在ARIMA的英文名称中,却是关键步骤。 该模型十分简单,只需要带有时间的变量,但是 1.要求时序数据是稳定的(stationary),或者是通过差分化(differencing)后是稳定的。 2.本质上只能捕捉线性关系,而不能捕捉非线性关系。 注意⚠️:采用ARIMA模型预测时序数据,必须是稳定的,如果不稳定的数据,是无法捕捉到规律的。比如股票数据用ARIMA无法预测的原因就是股票数据是非稳定的,常常受政策和新闻的影响而波动。 2 建模 2.1 预备知识 2.1.1 ADF检验结果(单位根检验统计量)ADF检验结果作用: 1,ADF检验是一种检验时间序列是否平稳的方法,其原假设是存在单位根,即非平稳。根据ADF检验的结果,可以通过比较检验统计量和临界值,以及p值和显著性水平,来判断是否拒绝原假设。2,如果拒绝原假设,可以认为数据是平稳的;如果不拒绝原假设,可以认为数据是非平稳的,需要进行差分后再检验3,另外,还需要根据不同的模型,判断数据是趋势平稳、截距平稳还是不含截距和时间趋势的平稳。ADF检验结果的五个参数含义: 第一个参数:adt检验的结果,简称为T值,表示t统计量。 第二个参数:简称为p值,表示t统计量对应的概率值。p值表示在原假设(零假设)的条件下,样本发生或观测值出现的概率。若p值小于小概率事件的阈值(0.05或0.01),那么拒绝原假设(即数据是平稳的),否则接受原假设。 若P'2016-02': 44964.03, '2016-03': 56825.51, '2016-04': 49161.98, '2016-05': 45859.35, '2016-06': 45098.56, '2016-07': 45522.17, '2016-08': 57133.18, '2016-09': 49037.29, '2016-10': 43157.36, '2016-11': 48333.17, '2016-12': 22900.94, '2017-01': 67057.29, '2017-02': 49985.29, '2017-03': 49771.47, '2017-04': 35757.0, '2017-05': 42914.27, '2017-06': 44507.03, '2017-07': 40596.51, '2017-08': 52111.75, '2017-09': 49711.18, '2017-10': 45766.09, '2017-11': 45273.82, '2017-12': 22469.57, '2018-01': 71032.23, '2018-02': 37874.38, '2018-03': 44312.24, '2018-04': 39742.02, '2018-05': 43118.38, '2018-06': 33859.69, '201807': 38910.89, '2018-08': 39138.42, '2018-09': 37175.03, '2018-10': 44159.96, '2018-11': 46321.72, '2018-12': 22410.88, '2019-01': 61241.94, '2019-02': 31698.6, '2019-03': 44170.62, '2019-04': 47627.13, '2019-05': 54407.37, '2019-06': 50231.68, '2019-07': 61010.29, '2019-08': 59782.19, '2019-09': 57245.15, '2019-10': 61162.55, '2019-11': 52398.25, '2019-12': 15482.64, '2020-01': 38383.97, '2020-02': 26943.55, '2020-03': 57200.32, '2020-04': 49449.95, '2020-05': 47009.84, '2020-06': 49946.25, '2020-07': 56383.23, '2020-08': 60651.07} # 转换为Dataframe data = {'time_data': list(need_data.keys()), 'click_value_rate': list(need_data.values())} df = pd.DataFrame(data) df.set_index(['time_data'], inplace=True) # 设置索引 data = df 从excel中数据转换: path = '/Users/mac/Downloads/时间序列模型测试数据.xlsx' df=pd.read_excel(path) # 更改列名 df.rename(columns={'data':'deal_data', 'time':'time_data'}, inplace = True) # 设置索引 df.set_index(['time_data'], inplace=True) data = df3, 对原始数据进行绘图; # 绘制时序图 plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 用来正常显示中文标签 # plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 绘图 data.plot() # 图片展示 plt.show() # 绘制自相关图 plot_acf(data).show() # 绘制偏自相关图 plot_pacf(data).show() 平稳性检测 print(u'原始序列的ADF检验结果为:', ADF(data[u'deal_data']))下图为时序图: 由于p值为0.728584,不能拒绝原假设(数据不稳定)。 4,对原始数据进行差分,让数据变成平稳时间序列; tmp_data = data.diff().dropna() #一阶差分并去空列 D_data = tmp_data.diff().dropna() #二阶差分 tmp_data.columns = [u'用户转化率差分'] # 取列名 D_data.columns = [u'用户转化率差分'] # 时序图 D_data.plot() plt.show() # 自相关图 plot_acf(D_data).show() # 偏自相关图 plot_pacf(D_data).show() print(u'一阶差分序列的ADF检验结果为:', ADF(tmp_data[u'用户转化率差分'])) # 平稳性检测 print(u'二阶差分序列的ADF检验结果为:', ADF(D_data[u'用户转化率差分'])) # 平稳性检测下图时序图(从左到右,分别为原始数据,一阶差分,二阶差分): 可以看出数据逐渐趋于有规律 可以看的二阶差分后的数据的p值远远小于0.1,即可以拒绝原假设(数据不稳定),得到数据数据稳定。 5,差分序列的白噪声检验; print(u'差分序列的白噪声检验结果为:', acorr_ljungbox(D_data, lags=1)) # 返回统计量和p值运行结果 二阶差分序列的白噪声检验结果为: lb_stat lb_pvalue 1 33.952495 5.647422e-09这里得到的p值为5.647422e-09,即拒绝原假设,序列不是白噪声。 6,确定ARIMA的p,q参数; 方法一(使用BIC矩阵): pmax = int(len(D_data) / 10) # 一般阶数不超过length/10 qmax = int(len(D_data) / 10) # 一般阶数不超过length/10 bic_matrix = [] # BIC矩阵 # 差分阶数 diff_num = 2 for p in range(pmax): tmp = [] for q in range(qmax): try: tmp.append(ARIMA(D_data, order=(p, diff_num, q)).fit().bic) except Exception as e: print(e) tmp.append(None) bic_matrix.append(tmp) bic_matrix = pd.DataFrame(bic_matrix) # 从中可以找出最小值 p, q = bic_matrix.stack().idxmin() # 先用stack展平,然后用idxmin找出最小值位置。 print(u'BIC最小的p值和q值为:%s、%s' % (p, q))得到结果: BIC最小的p值和q值为:1、3方法二:使用AIC和BIC准则定阶 AIC = sm.tsa.stattools.arma_order_select_ic(D_data, max_ar=4, max_ma=4, ic='aic')['aic_min_order'] # BIC BIC = sm.tsa.stattools.arma_order_select_ic(D_data, max_ar=4, max_ma=4, ic='bic')['bic_min_order'] print('---AIC与BIC准则定阶---') print('the AIC is{}\nthe BIC is{}\n'.format(AIC, BIC), end='') p = BIC[0] q = BIC[1] diff_num = 2 ---AIC与BIC准则定阶--- the AIC is(0, 2) the BIC is(0, 2)7,模型预测; model = ARIMA(data, order=(p, diff_num, q)).fit() # 建立ARIMA(p, diff+num, q)模型 print('模型报告为:\n', model.summary()) print("预测结果:") print(model.forecast(forecast_num)) print("预测结果(详细版):\n") forecast = model.get_forecast(steps=forecast_num) table = pd.DataFrame(forecast.summary_frame()) print(table)8,模型检验 def Model_checking(model): # 残差检验:检验残差是否服从正态分布,画图查看,然后检验 # 绘制残差图 model.resid.plot(figsize=(10, 3)) plt.title("残差图") plt.show() print('------------残差检验-----------') # model.resid:残差 = 实际观测值 – 模型预测值 print(stats.normaltest(model.resid)) # QQ图看正态性 qqplot(model.resid, line="q", fit=True) plt.title("Q-Q图") plt.show() # 绘制直方图 plt.hist(model.resid, bins=50) plt.show() # 进行Jarque-Bera检验:判断数据是否符合总体正态分布 jb_test = sm.stats.stattools.jarque_bera(model.resid) print("==================================================") print('------------Jarque-Bera检验-----------') print('Jarque-Bera test:') print('JB:', jb_test[0]) print('p-value:', jb_test[1]) print('Skew:', jb_test[2]) print('Kurtosis:', jb_test[3]) # 残差序列自相关:残差序列是否独立 print('------DW检验:残差序列自相关----') print(sm.stats.stattools.durbin_watson(model.resid.values))结果: ------------残差检验----------- NormaltestResult(statistic=4.4959826117374515, pvalue=0.10561115214326909) ------------Jarque-Bera检验----------- Jarque-Bera test: JB: 4.0642468241648775 p-value: 0.13105693759455012 Skew: 0.33412880151714236 Kurtosis: 4.151920700073933 ------DW检验:残差序列自相关---- 1.71022123825392
由检测结果可以看出,模式良好。 3.2 完整代码 from __future__ import annotations import numpy as np import pandas as pd import matplotlib.pyplot as plt import statsmodels.api as sm from statsmodels.tsa.stattools import adfuller as ADF from statsmodels.stats.diagnostic import acorr_ljungbox from statsmodels.graphics.tsaplots import plot_acf, plot_pacf #ACF与PACF from statsmodels.tsa.arima.model import ARIMA #ARIMA模型 from statsmodels.graphics.api import qqplot #qq图 from scipy import stats import warnings warnings.filterwarnings("ignore") # 绘图设置(适用于mac) # plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 模型检测 def Model_checking(model) -> None: # 残差检验:检验残差是否服从正态分布,画图查看,然后检验 print('------------残差检验-----------') # model.resid:残差 = 实际观测值 – 模型预测值 print(stats.normaltest(model.resid)) # QQ图看正态性 qqplot(model.resid, line="q", fit=True) plt.title("Q-Q图") plt.show() # 绘制直方图 plt.hist(model.resid, bins=50) plt.show() # 进行Jarque-Bera检验:判断数据是否符合总体正态分布 jb_test = sm.stats.stattools.jarque_bera(model.resid) print("==================================================") print('------------Jarque-Bera检验-----------') print('Jarque-Bera test:') print('JB:', jb_test[0]) print('p-value:', jb_test[1]) print('Skew:', jb_test[2]) print('Kurtosis:', jb_test[3]) # 残差序列自相关:残差序列是否独立 print("==================================================") print('------DW检验:残差序列自相关----') print(sm.stats.stattools.durbin_watson(model.resid.values)) # 使用BIC矩阵计算p和q的值 def cal_pqValue(D_data, diff_num=0) -> List[float]: # 定阶 pmax = int(len(D_data) / 10) # 一般阶数不超过length/10 qmax = int(len(D_data) / 10) # 一般阶数不超过length/10 bic_matrix = [] # BIC矩阵 # 差分阶数 diff_num = 2 for p in range(pmax + 1): tmp = [] for q in range(qmax + 1): try: tmp.append(ARIMA(D_data, order=(p, diff_num, q)).fit().bic) except Exception as e: print(e) tmp.append(None) bic_matrix.append(tmp) bic_matrix = pd.DataFrame(bic_matrix) # 从中可以找出最小值 p, q = bic_matrix.stack().idxmin() # 先用stack展平,然后用idxmin找出最小值位置。 print(u'BIC最小的p值和q值为:%s、%s' % (p, q)) return p, q # 计算时序序列模型 def cal_time_series(data, forecast_num=3) -> None: # 绘制时序图 data.plot() # 存储图片 plt.savefig('/Users/mac/Downloads/1.png') plt.show() # 绘制自相关图 plot_acf(data).show() # 绘制偏自相关图 plot_pacf(data).show() # 时序数据平稳性检测 original_ADF = ADF(data[u'deal_data']) print(u'原始序列的ADF检验结果为:', original_ADF) # 对数序数据进行d阶差分运算,化为平稳时间序列 diff_num = 0 # 差分阶数 diff_data = data # 差分数序数据 ADF_p_value = ADF(data[u'deal_data'])[1] while ADF_p_value > 0.01: diff_data = diff_data.diff(periods=1).dropna() diff_num = diff_num + 1 ADF_result = ADF(diff_data[u'deal_data']) ADF_p_value = ADF_result[1] print("ADF_p_value:{ADF_p_value}".format(ADF_p_value=ADF_p_value)) print(u'{diff_num}差分的ADF检验结果为:'.format(diff_num = diff_num), ADF_result ) # 白噪声检测 print(u'差分序列的白噪声检验结果为:', acorr_ljungbox(diff_data, lags=1)) # 返回统计量和p值 # 使用AIC和BIC准则定阶q和p的值(推荐) AIC = sm.tsa.stattools.arma_order_select_ic(diff_data, max_ar=4, max_ma=4, ic='aic')['aic_min_order'] BIC = sm.tsa.stattools.arma_order_select_ic(diff_data, max_ar=4, max_ma=4, ic='bic')['bic_min_order'] print('---AIC与BIC准则定阶---') print('the AIC is{}\nthe BIC is{}\n'.format(AIC, BIC), end='') p = BIC[0] q = BIC[1] # 使用BIC矩阵来计算q和p的值 # pq_result = cal_pqValue(diff_data, diff_num) # p = pq_result[0] # q = pq_result[1] # 构建时间序列模型 model = ARIMA(data, order=(p, diff_num, q)).fit() # 建立ARIMA(p, diff+num, q)模型 print('模型报告为:\n', model.summary()) print("预测结果:\n", model.forecast(forecast_num)) print("预测结果(详细版):\n") forecast = model.get_forecast(steps=forecast_num) table = pd.DataFrame(forecast.summary_frame()) print(table) # 绘制残差图 diff_data.plot(color='orange', title='残差图') model.resid.plot(figsize=(10, 3)) plt.title("残差图") # plt.savefig('/Users/mac/Downloads/1.png') plt.show() # 模型检查 Model_checking(model) if __name__ == '__main__': # 数据测试1: need_data = {'2016-02': 44964.03, '2016-03': 56825.51, '2016-04': 49161.98, '2016-05': 45859.35, '2016-06': 45098.56, '2016-07': 45522.17, '2016-08': 57133.18, '2016-09': 49037.29, '2016-10': 43157.36, '2016-11': 48333.17, '2016-12': 22900.94, '2017-01': 67057.29, '2017-02': 49985.29, '2017-03': 49771.47, '2017-04': 35757.0, '2017-05': 42914.27, '2017-06': 44507.03, '2017-07': 40596.51, '2017-08': 52111.75, '2017-09': 49711.18, '2017-10': 45766.09, '2017-11': 45273.82, '2017-12': 22469.57, '2018-01': 71032.23, '2018-02': 37874.38, '2018-03': 44312.24, '2018-04': 39742.02, '2018-05': 43118.38, '2018-06': 33859.69, '2018-07': 38910.89, '2018-08': 39138.42, '2018-09': 37175.03, '2018-10': 44159.96, '2018-11': 46321.72, '2018-12': 22410.88, '2019-01': 61241.94, '2019-02': 31698.6, '2019-03': 44170.62, '2019-04': 47627.13, '2019-05': 54407.37, '2019-06': 50231.68, '2019-07': 61010.29, '2019-08': 59782.19, '2019-09': 57245.15, '2019-10': 61162.55, '2019-11': 52398.25, '2019-12': 15482.64, '2020-01': 38383.97, '2020-02': 26943.55, '2020-03': 57200.32, '2020-04': 49449.95, '2020-05': 47009.84, '2020-06': 49946.25, '2020-07': 56383.23, '2020-08': 60651.07} data = {'time_data': list(need_data.keys()), 'deal_data': list(need_data.values())} df = pd.DataFrame(data) df.set_index(['time_data'], inplace=True) # 设置索引 cal_time_series(df, 7) # 模型调用 # 数据测试2(从excel中读取): # path = '/Users/mac/Downloads/时间序列模型测试数据.xlsx' # df = pd.read_excel(path) # df.rename(columns={'data': 'deal_data', 'time': 'time_data'}, inplace=True) # df.set_index(['time_data'], inplace=True) # 设置索引 # cal_time_series(df, 7) # 模型调用 4 测试数据和完整代码网盘链接:提取码: o8po 5 拓展学习如果想使用其他时间序列模型,可以看看Facebook做的大规模时序预测Prophet。 参考文章图灵追慕者 SPSSPRO Github上facebook的prophet项目 Yuting_Sunshine 一眉师傅 English Chan Sany 何灿 机器之心 seriesc 北京大学《金融时间序列分析讲义》 Foneone statsmodels中文官网API |
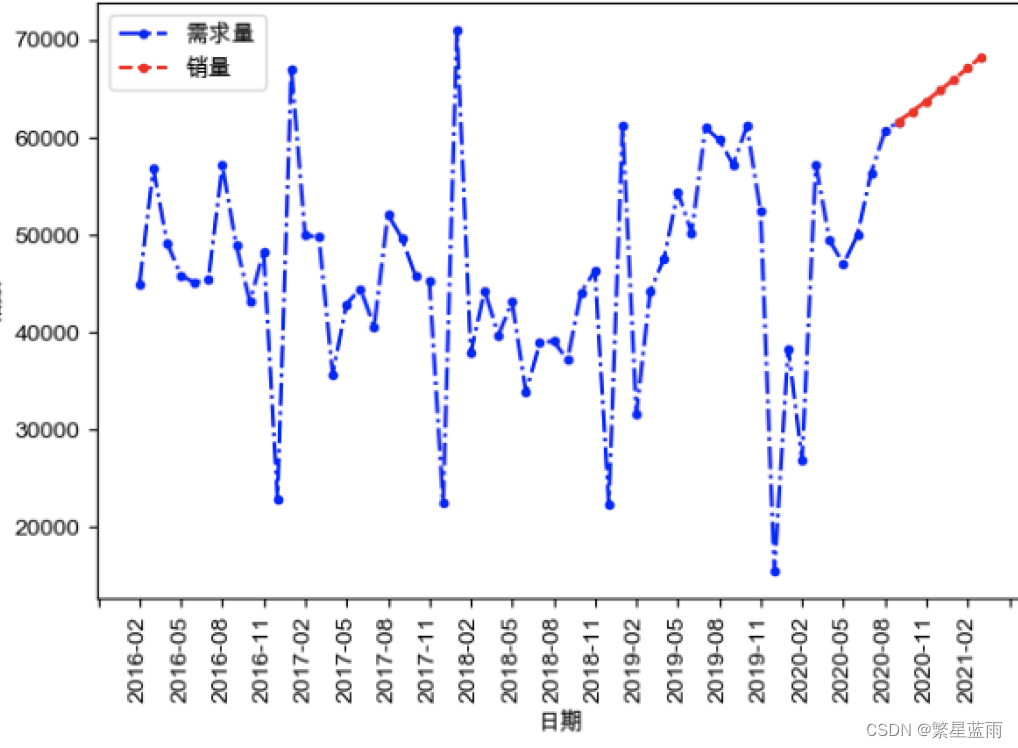
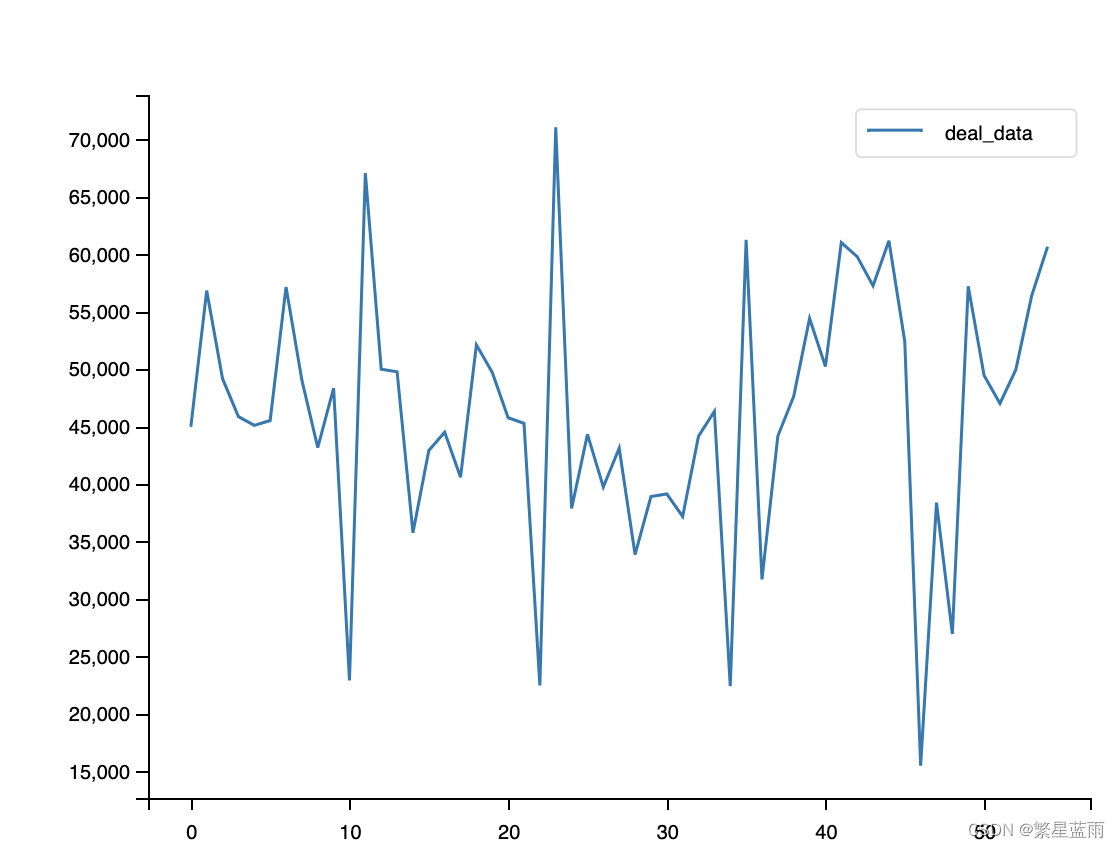 下图为自相关图:
下图为自相关图: 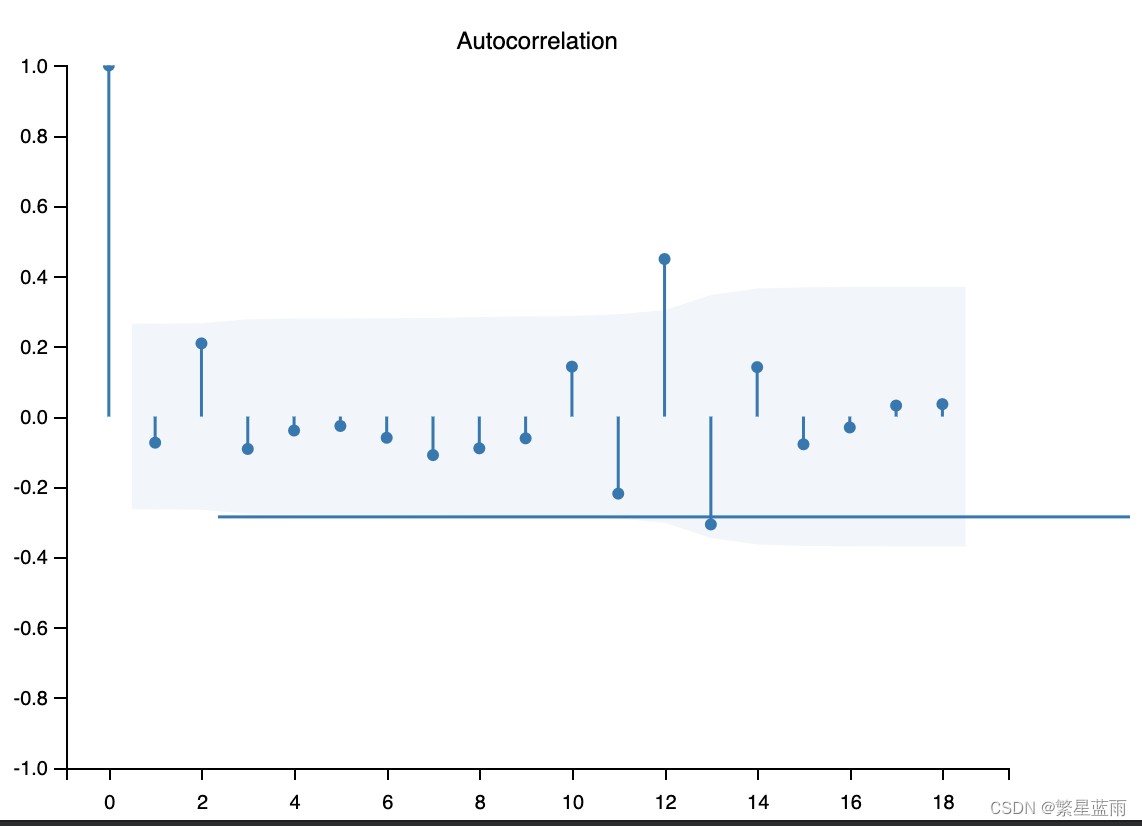
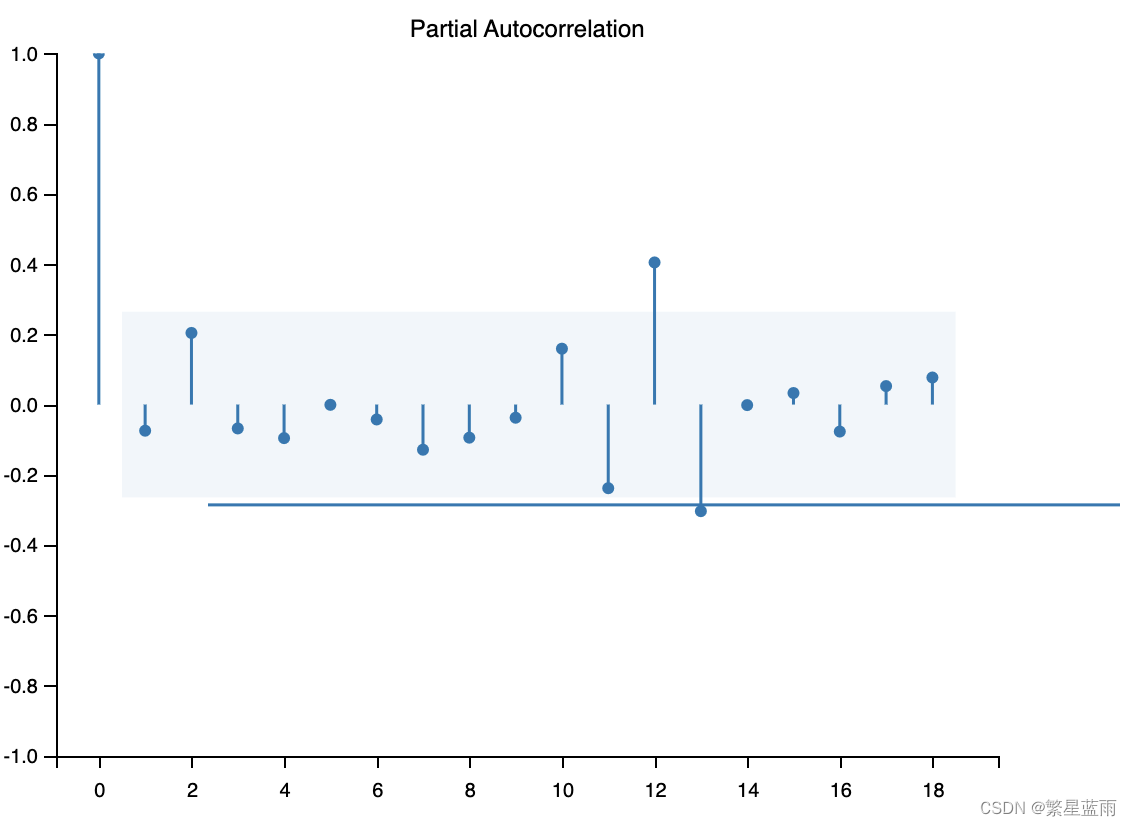 截尾
截尾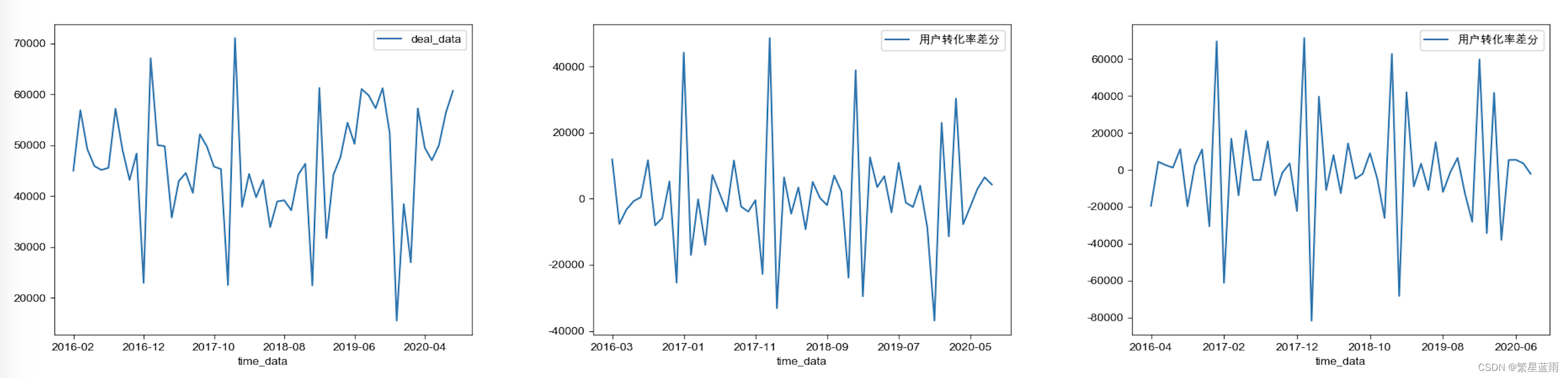 下图自相关图(从左到右,分别为原始数据,一阶差分,二阶差分):
下图自相关图(从左到右,分别为原始数据,一阶差分,二阶差分): 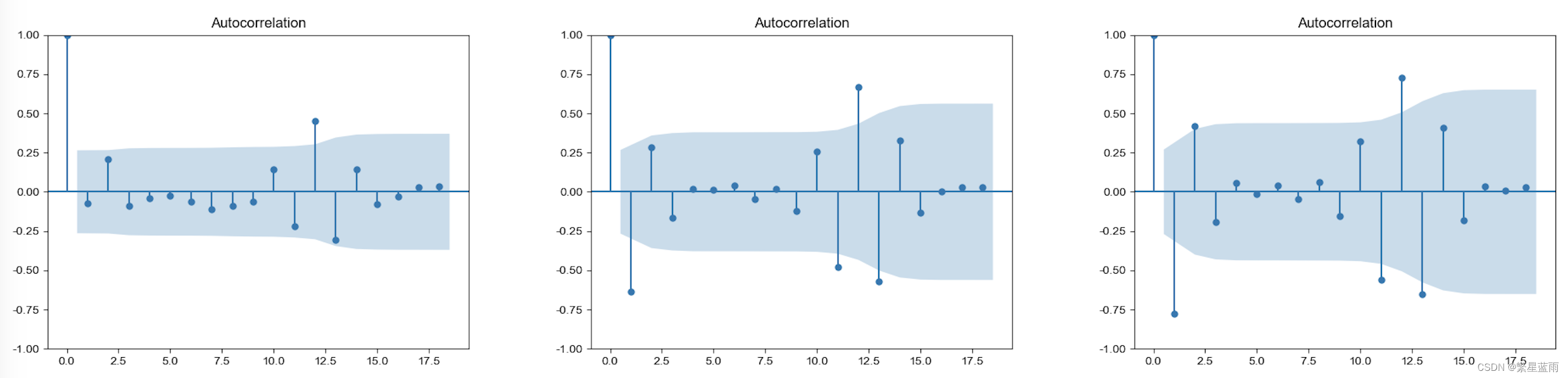 下图偏自相关图(从左到右,分别为原始数据,一阶差分,二阶差分):
下图偏自相关图(从左到右,分别为原始数据,一阶差分,二阶差分): 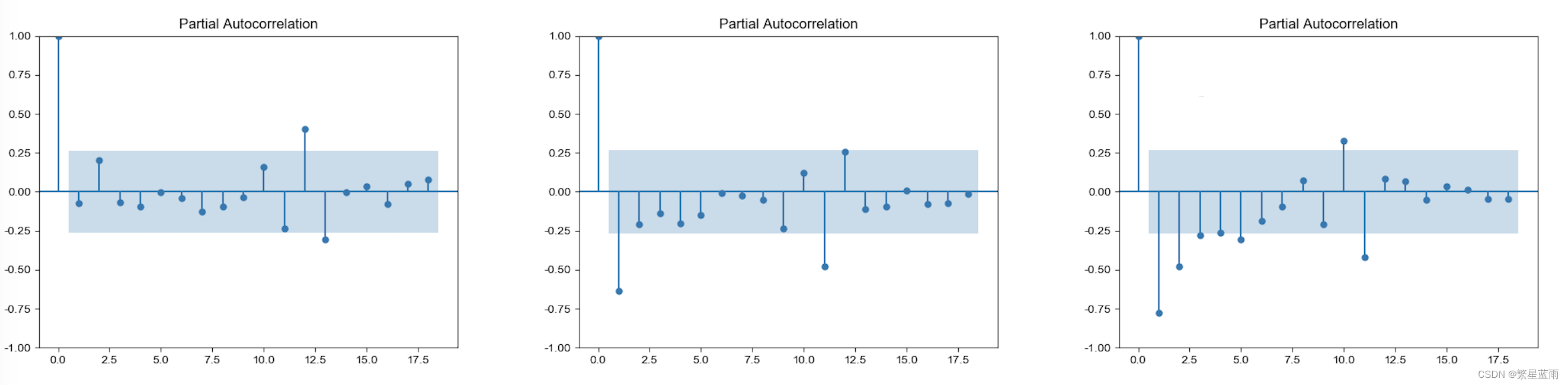 ADF检验结果:
ADF检验结果: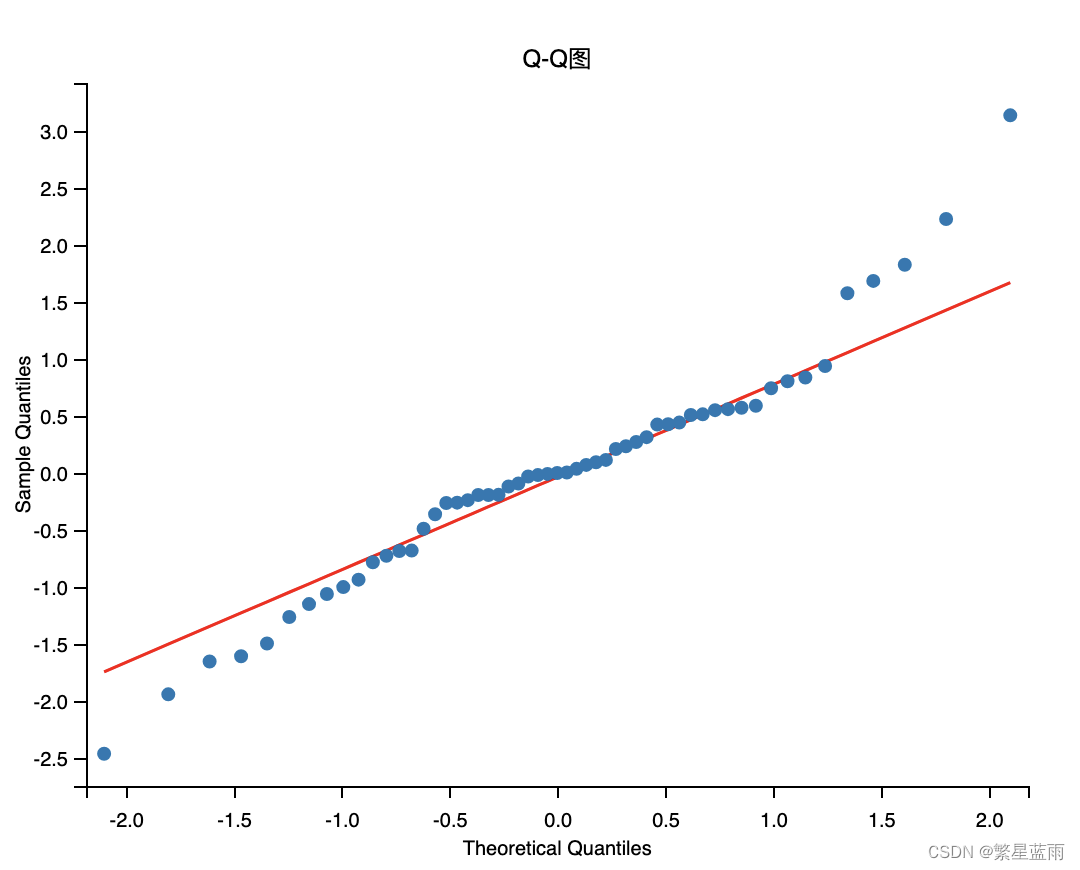
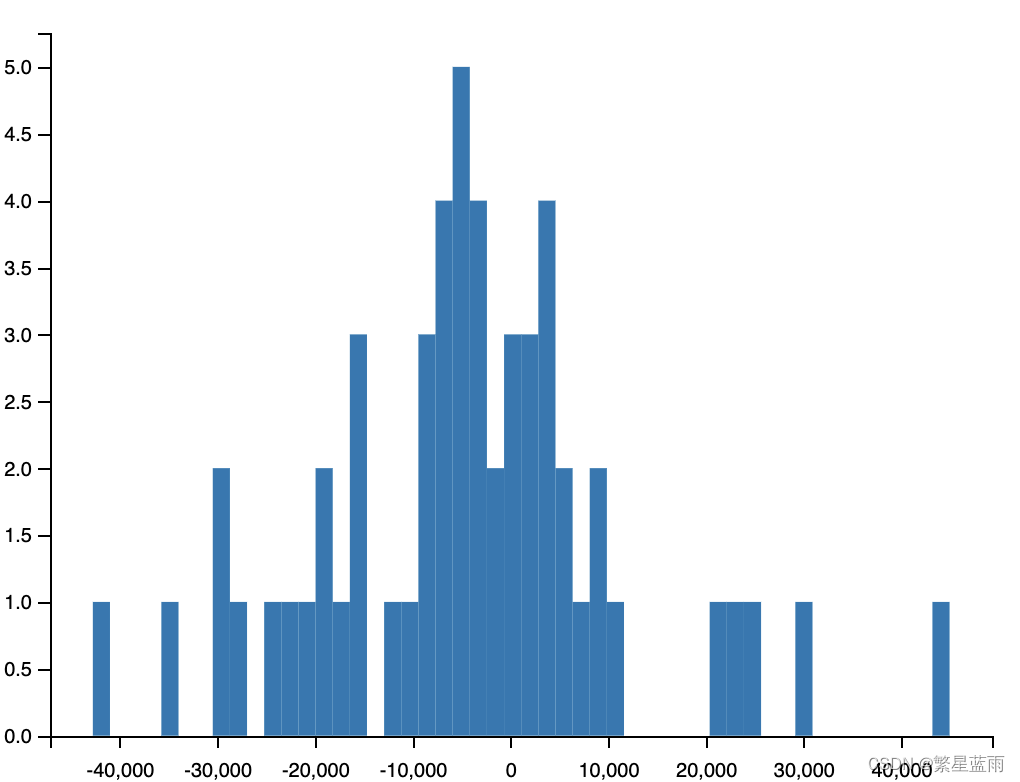
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |