爬取QQ音乐Last Dance的评论并进行情感分析(python+paddlehub) |
您所在的位置:网站首页 › qq音乐的推荐算法在哪设置 › 爬取QQ音乐Last Dance的评论并进行情感分析(python+paddlehub) |
爬取QQ音乐Last Dance的评论并进行情感分析(python+paddlehub)
|
关注“python趣味爱好者”公众号,回复“QQ音乐”获取源代码 首先明确目标:使用paddlehub的senta_lstm模型对歌曲的评论进行情感分析,在这里,我选择了里的歌:伍佰的Last Dance。 我们打开QQ音乐网页版,找到伍佰的Last Dance这首歌,看看评论在哪里,往下滑就可以看到: 确认了这个网页上有我们需要的东西以后,按F12: 爬虫程序还需要一个请求头文件来对抗反爬机制: # headers头部 headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:59.0) Gecko/20100101Firefox/59.0','Referer':"https://y.qq.com/n/yqq/song/0031TAKo0095np.html"}以下是获取评论的代码,注释写的很清楚,这里就不再过多地阐述了: def get_comment(self): # headers头部 headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:59.0) Gecko/20100101 Firefox/59.0','Referer': "https://y.qq.com/n/yqq/song/0031TAKo0095np.html"} # 请求的url url = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq.json&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=4928818&cmd=8&needmusiccrit=0&pagenum=0&pagesize=25&lasthotcommentid=&domain=qq.com&ct=24&cv=10101010' # print(url) # 将请求得到的页面赋值为req req = requests.get(url, headers=headers, verify=False) # 对获取到的内容进行utf-8编码 html = str(req.content, 'UTF-8') # 对非正规的json进行处理,去掉尾部多余的部分 html = html.replace(")", "") # 去掉两边的空格 html = html.strip() # 将处理后的json转为python的json data = json.loads(html) # print(data) # 获取json中评论的部分 list = data['comment']['commentlist'] # 每次都重新定义一个列表来存储每一页的评论 content = [] # 遍历当前页的评论并通过调用write()函数来保存 for item in list: # print(i) try: content.append(item['rootcommentcontent'].replace("[em]", "").replace("[/em]", "").replace("e400", "")) except KeyError: content = [] break return content接下来就可以开始对评论进行情感分析了: # 将当前页面的评论传递过来 def analysis(self, content): senta = hub.Module(name="senta_lstm") positive = 0 negative = 0我们分两类,一类积极,另一类消极,情感分析的模型是senta_lstm,安装这个模型需要用到paddlehub: 以下是示例代码: import paddlehub as hub senta = hub.Module(name="senta_lstm") test_text = ["看到李子维说:'是打给王诠胜的 不是打给我的'给我心疼死了喜欢黄雨萱的一直都是李子维啊"] input_dict = {"text": test_text} results = senta.sentiment_classify(data=input_dict) for result in results: print(result['text']) print(result['sentiment_label']) print(result['sentiment_key']) print(result['positive_probs']) print(result['negative_probs'])结果如下: 可以看到,在这里,我进行了计数,为的就是画个图表: 最后写出主函数: def main(): comment_analysis = COMMENT_ANALYSIS() comment_analysis.draw() if __name__ == "__main__": main()这里我讲一讲,程序的入口是函数draw(),画图需要得到两种情感的values,这个values可以通过运行函数self.analysis()获取,但是函数self.analysis()需要传一个参数进去,这个参数是评论,那么我们就需要启动爬虫的函数:self.get_comment(),这是一整个程序的核心思路。 可能有一点难度,我们来看看简化的版本: class COMMENT_ANALYSIS(object): def get_comment(self): #获取评论,把评论转载到content return content # 将评论传递过来进行分析 def analysis(self, content): #导入senta_lstm模型 senta = hub.Module(name="senta_lstm") positive = 0 negative = 0 #用for循环遍历评论,返回积极与消极评论的个数 return positive,negative def draw(self): #获取画图必备的数据 labels = 'Positive', 'Negative' values = self.analysis(self.get_comment()) sizes = [values[0], values[1]] #显示 plt.show() def main(): #实例化 comment_analysis = COMMENT_ANALYSIS() comment_analysis.draw() if __name__ == "__main__": main()简化的版本不能运行,但是能表达整个程序的思路,大家可以先从简化的版本开始编写该程序,如果能把代码复原,并成功得到输出结果: 关注“python趣味爱好者”公众号,回复“QQ音乐”获取源代码查看答案。 |
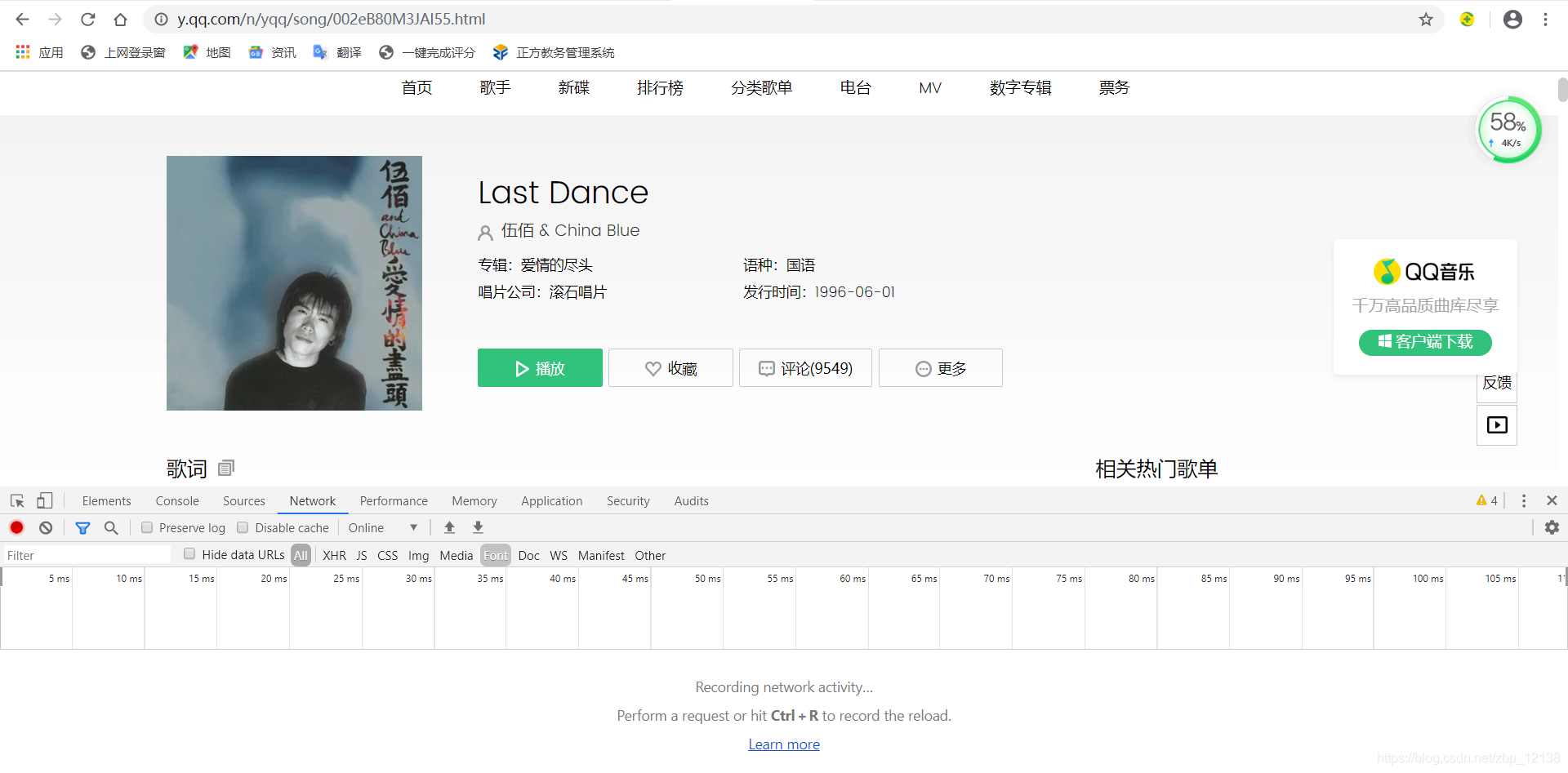 看英文提示,按住CTRL+R:
看英文提示,按住CTRL+R: 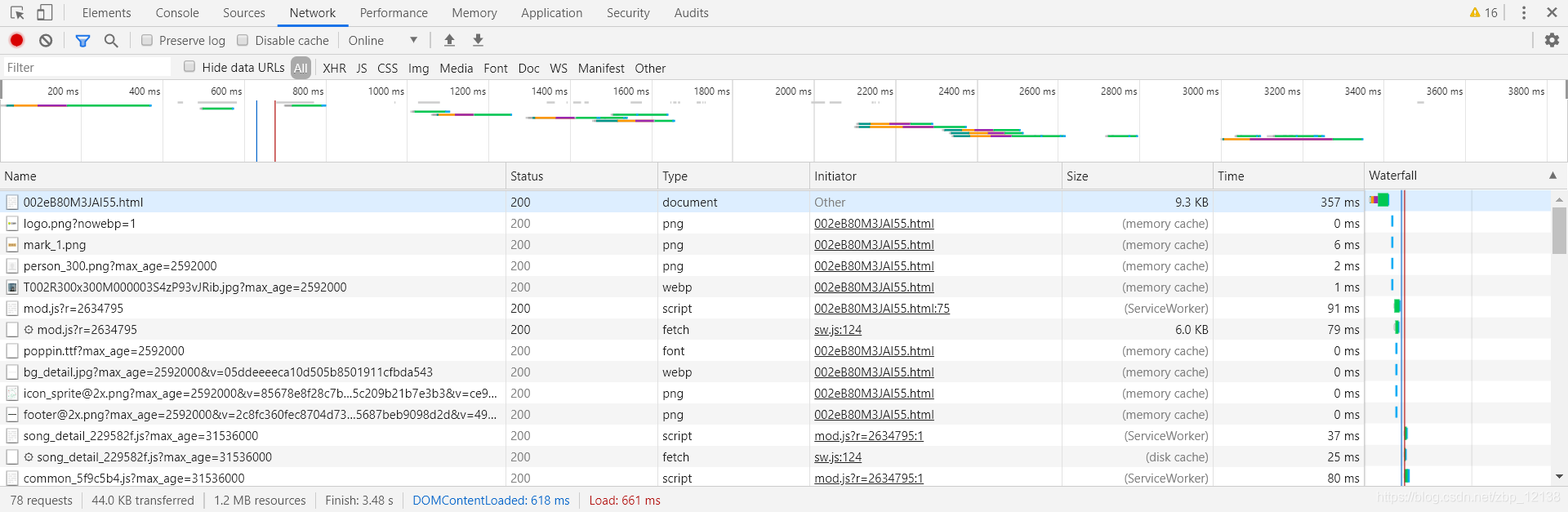 可以看到,这是网页返回的数据,我们需要找到存放评论的数据:
可以看到,这是网页返回的数据,我们需要找到存放评论的数据: 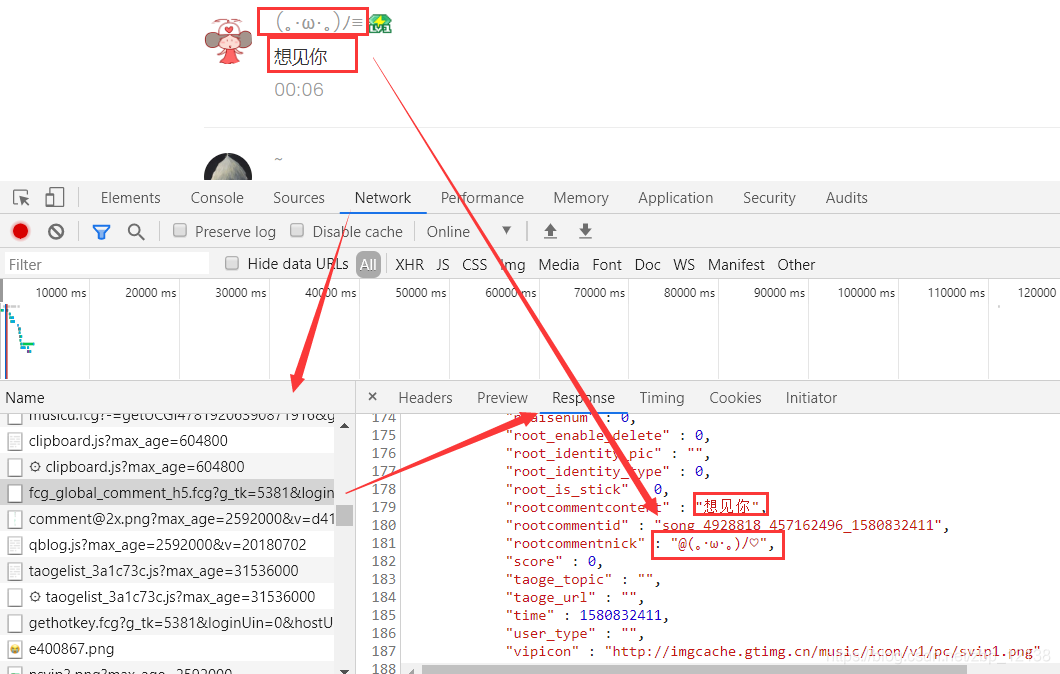 可以看到,这条数据里存放的是评论,我们看看Headers:
可以看到,这条数据里存放的是评论,我们看看Headers: 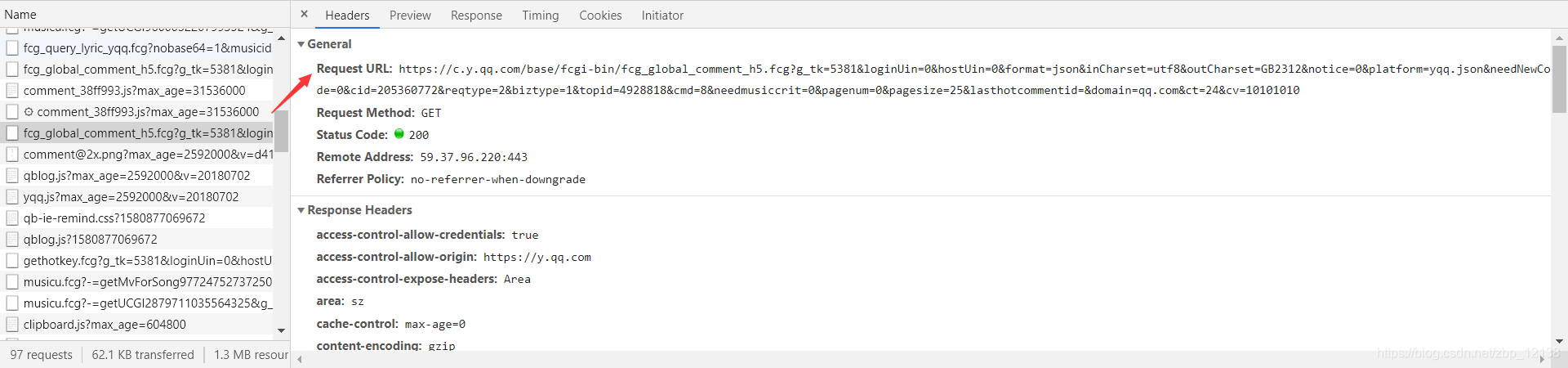 打开这个URL:
打开这个URL: 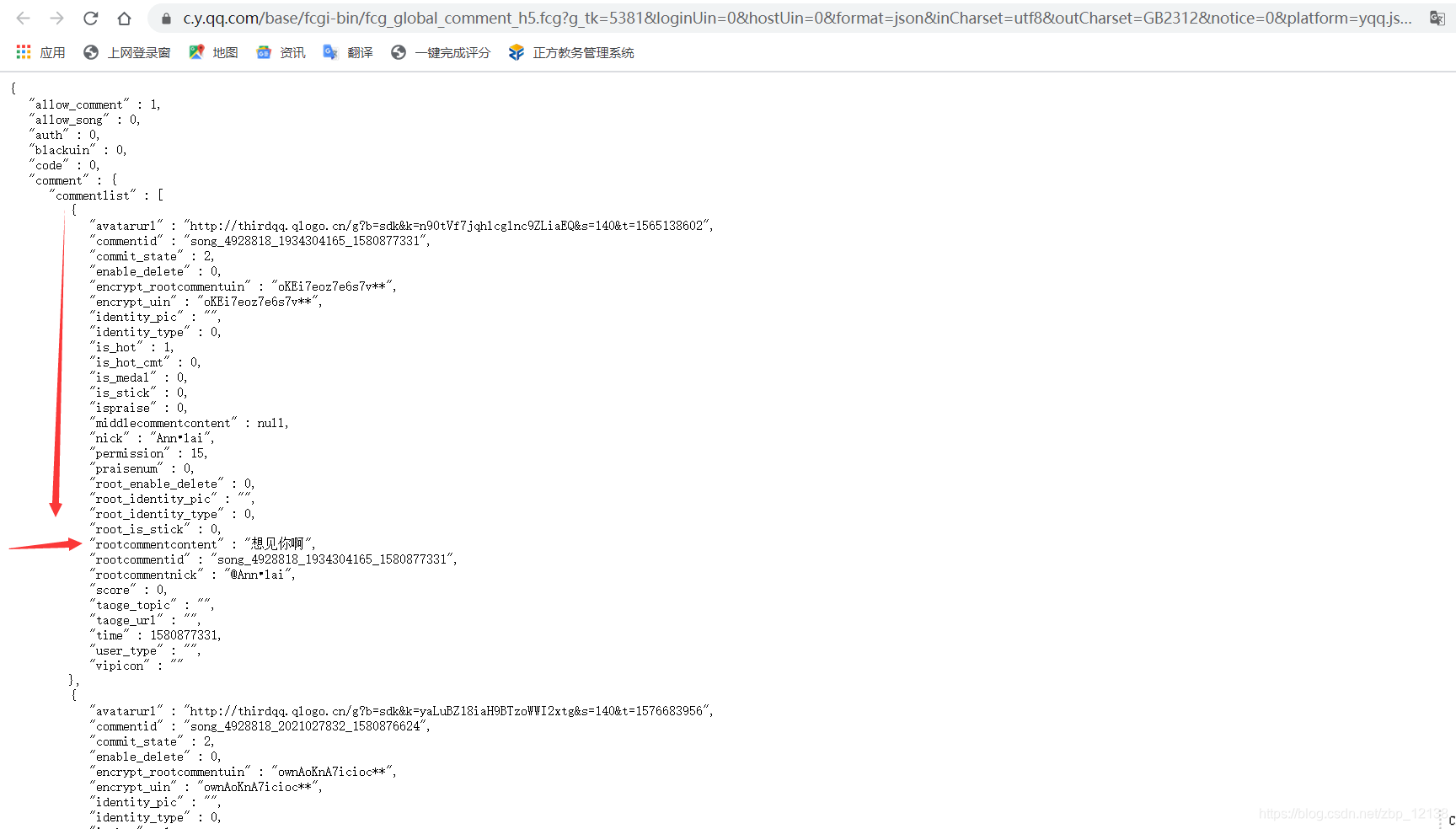 可以看到,返回的是json串,且格式正确:
可以看到,返回的是json串,且格式正确: 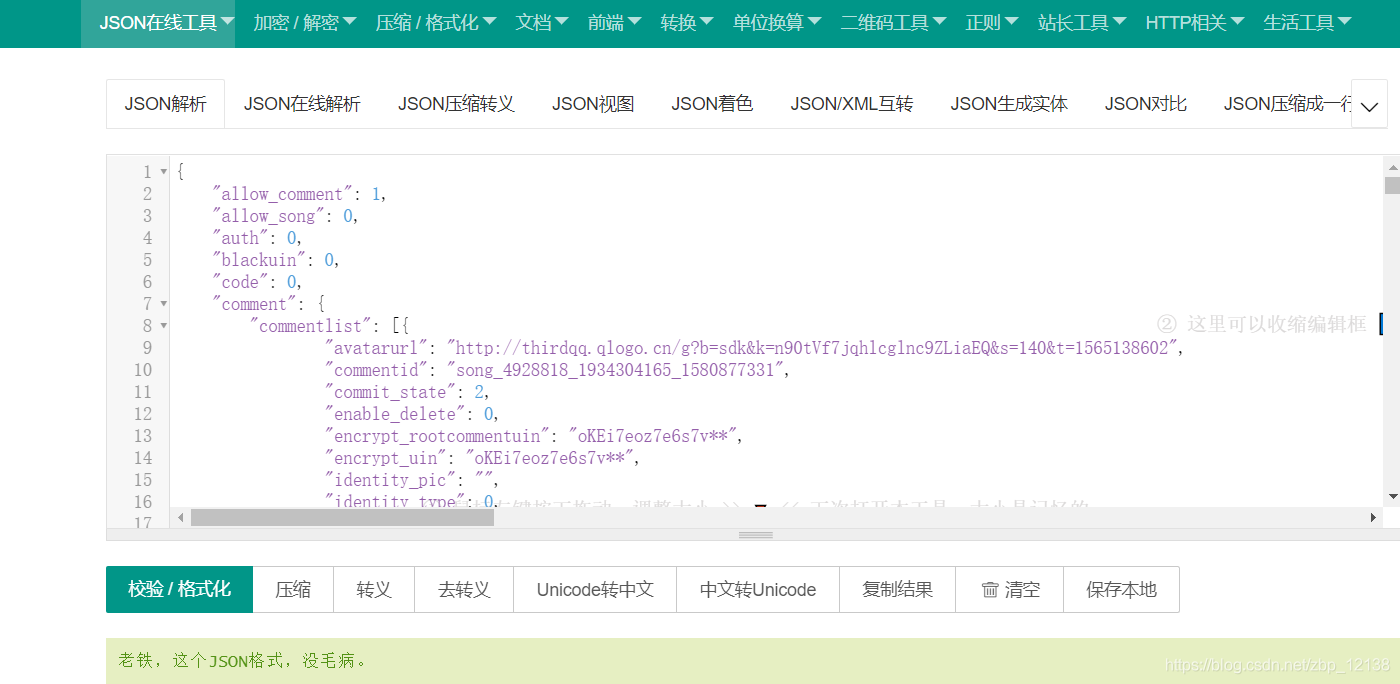 于是,我们的url地址就有了:
于是,我们的url地址就有了: 具体使用方法可以查看以下链接: https://www.paddlepaddle.org.cn/hubdetail?name=senta_lstm&en_category=SentimentAnalysis
具体使用方法可以查看以下链接: https://www.paddlepaddle.org.cn/hubdetail?name=senta_lstm&en_category=SentimentAnalysis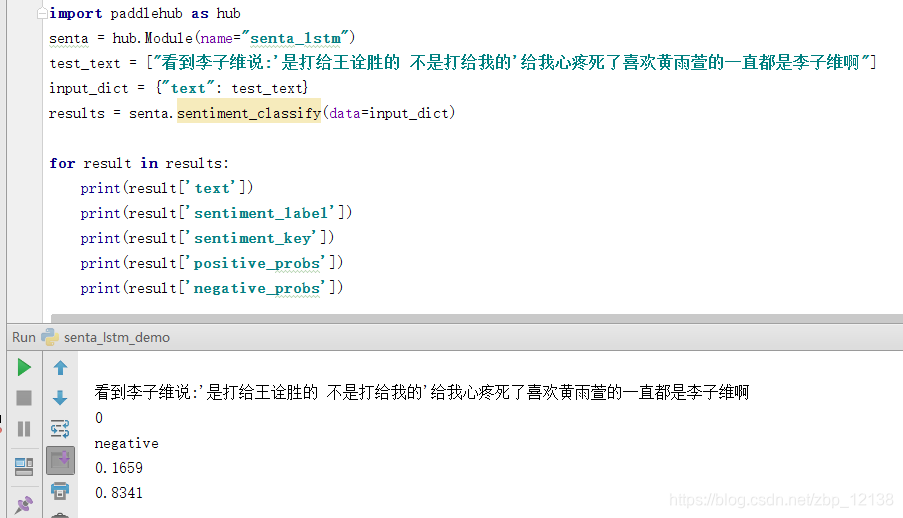 0代表消极,1代表积极。因此,可以看出,这句评论是偏消极的情感,准确的概率为0.8341。接下来,我们把评论提取出来,一一进行情感分析:
0代表消极,1代表积极。因此,可以看出,这句评论是偏消极的情感,准确的概率为0.8341。接下来,我们把评论提取出来,一一进行情感分析: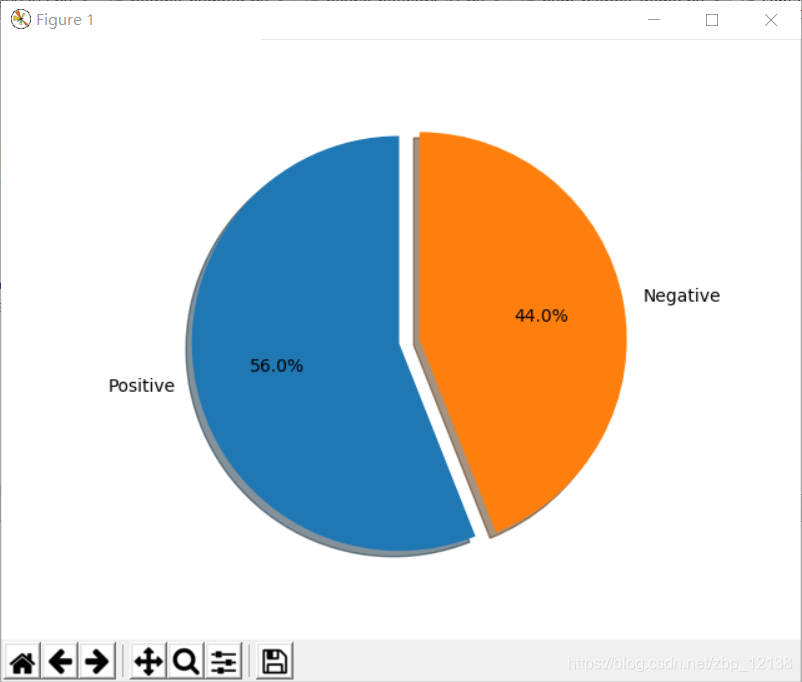 画图的代码在这:
画图的代码在这: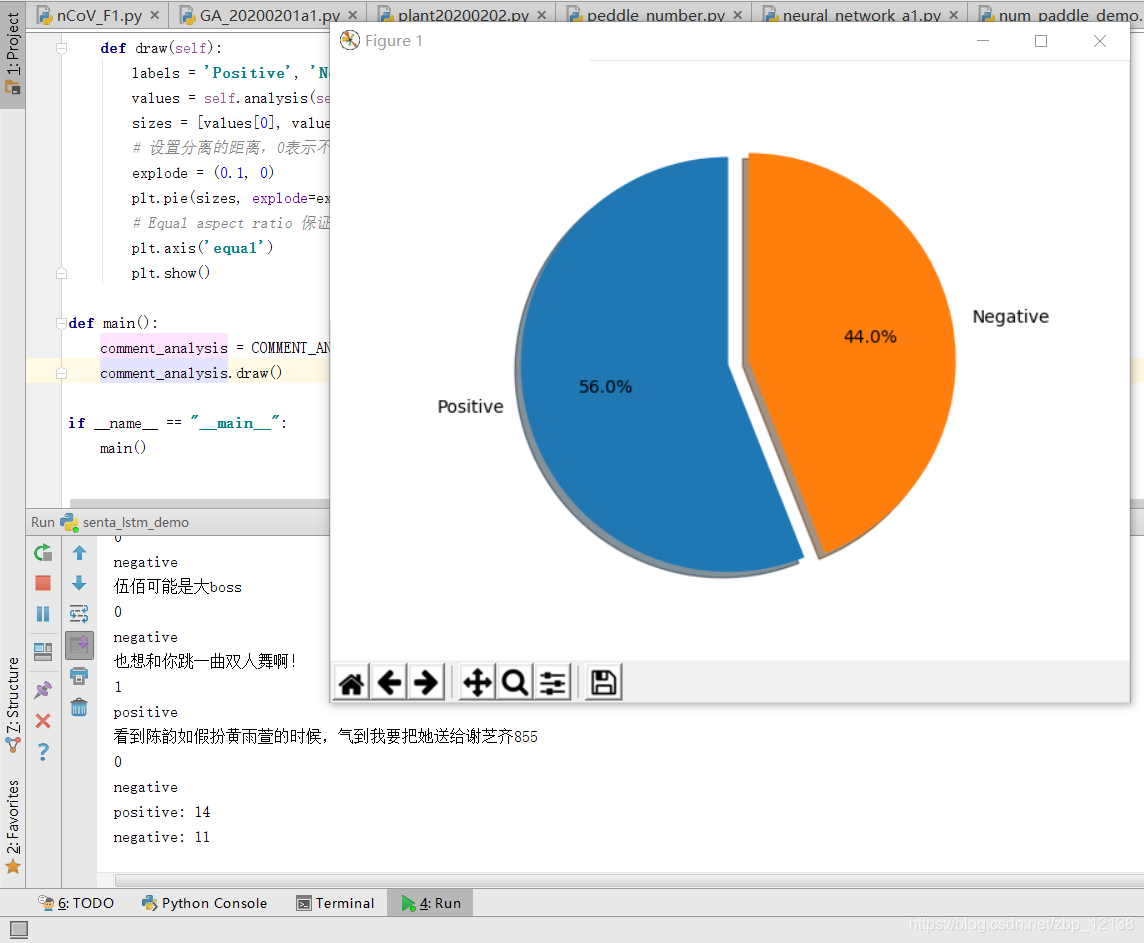 那么,恭喜你,你已经掌握了今天的内容!
那么,恭喜你,你已经掌握了今天的内容! 如有问题,欢迎大家在下方评论区留言!
如有问题,欢迎大家在下方评论区留言!【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |