基于python的电商评论分析,通过商品评论了解买家需求 |
您所在的位置:网站首页 › python预处理分析 › 基于python的电商评论分析,通过商品评论了解买家需求 |
基于python的电商评论分析,通过商品评论了解买家需求
|
基于python的电商评论分析,通过商品评论了解买家需求
文章目录
基于python的电商评论分析,通过商品评论了解买家需求前言一、分析前准备工作二、使用步骤1.数据预处理2.引入库2.分词3.词频统计4.词云图5.差评查找
总结
前言
电商商品的需求是电商运营中重要的一部分,只有这里的需求指市场对商品的需求以及买家对商品的需求。商品需求又可以更具体到商品的属性、特点、质量、使用方法、使用环境等等。只有了解这些需求,你才能更好的和厂商沟通,让厂商研发符合市场需求的产品、才可以更清晰明确的知道自己应该突出什么卖点、才能更加精准具体的向商品的受众人群营销,从而提高转化。本章内容主要记录分享笔者在工作中遇到的需求分析问题以及解决思路,仅供交流参考。(本文以眼影为例)
一、分析前准备工作
1、数据准备: ①行业靠前同类竞品评论数据(笔者数据源为行业排名靠前20家竞品10w条评论数据) ②行业靠前同类竞品问大家数据(问大家同20家) 2、环境准备:python3、pandas包、jieba包、wordcloud包、word2vec包等
二、使用步骤
1.数据预处理
对手中的数据进行检查处理: 1、了解数据字段,明确自己数据的评论数据列在哪个字段,方便后续读取 2、读取数据 2.引入库代码如下: ##1.引入库 import pandas as pd import matplotlib.pyplot as plt import jieba import jieba.analyse from wordcloud import WordCloud import logging import os from gensim.models import word2vec ## 2.读入数据 代码如下: ```c data = pd.read_csv(r'F:\灯具彩妆执行\彩妆\十色眼影\评论数据\多色眼影问大家总.csv', header=0,encoding='utf-8',dtype=str).astype(str) data.head() dt1=data['问'] #“问”为问题所在字段名 print(data.head()) 2.分词代码如下: ## 3.分词 skill= data['问'] skill.unique() tmp = {} for t in list(skill.unique()): t = str(t) t = t.replace('/',',') t = t.split(',') for _ in t: tmp[_] = tmp.get(_,0) + 1 tmp join_words = ' '.join(tmp) tmp ## 4.停用词 #我们知道商品评论中会有很多垃圾评论凑字数毫无意义,因此需要引入停用词词典来筛掉这些垃圾词 jieba.analyse.set_stop_words('stoped.txt') stopwords = [line.strip() for line in open('stoped.txt',encoding='UTF-8').readlines()] object_list = [] jieba.load_userdict(r"F:\学习\py\user_dict.txt") #导入使用词表,针对不同类目有不同的特征词,如“粉质细腻”、“不够闪”等,需要建立使用词词库以免词被拆散 use_dict = jieba.load_userdict(r"F:\学习\py\user_dict.txt") use_dict = [line.strip() for line in open('user_dict.txt',encoding='UTF-8').readlines()] words = jieba.lcut(join_words,cut_all=False) words 3.词频统计代码如下: ## 5.词频 segments = [] splitedStr = '' for word in words: if word not in stopwords: segments.append({'word':word, 'count':1}) splitedStr += word + ' ' dfSg = pd.DataFrame(segments) none_vin = (dfSg["word"].isnull()) | (dfSg["word"].apply(lambda x: str(x).isspace())) df_null = dfSg[none_vin] df_not_null = dfSg[~none_vin] a=df_not_null['word'].value_counts() b=pd.DataFrame(a) b
代码如下: ## 6.词云图 wc = WordCloud(font_path=r'F:\学习\ttc字体\华康勘亭流简W9.ttc',width=800,height=600) skill= df_not_null['word'] skill.unique() # 统计关键字 tmp = {} for t in list(skill.unique()): t = str(t) t = t.replace('/',',') t = t.split(',') for _ in t: tmp[_] = tmp.get(_,0) + 1 tmp join_words = ' '.join(tmp) print(join_words) skill.unique() img = wc.generate(join_words) plt.figure(figsize=(15,10)) plt.imshow(img) plt.axis('off') wc.to_file('wordcloud.png')
代码如下: #7.查找 neg_use = [line.strip() for line in open('.\查找.txt',encoding='UTF-8').readlines()] matching = [s for s in dt1 if any(xs in s for xs in neg_use)] matching差评是评论分析中不可忽视的一点,是反应产品优化方向,和避免踩雷的信息来源,因此需要建立消极词词典,通过遍历将评论中的差评筛选出来。 总结对于通过商品评论数据来做的商品需求分析来说,首先数据的量和质量是很重要的,因此要准备的数据应当是有一定数量,并且是行业靠前商品&自己产品同类竞品的评论,才能够反映出对自己产品提升有用的买家需求信息。通过词频统计找到买家最关注的点,通过差评找出买家最忌讳的点,从这两个方向对自己店铺的产品进行优化提升,打造、突出有效卖点。 |
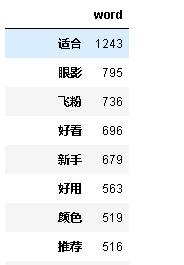 通过词频统计我们就可以知道买家的意向,了解买家的需求,买家对商品的关注点,从而去对自己的产品进行优化。
通过词频统计我们就可以知道买家的意向,了解买家的需求,买家对商品的关注点,从而去对自己的产品进行优化。 词云图可以直观的展示出,评论中的高频词句
词云图可以直观的展示出,评论中的高频词句【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |