【python脚本系列】python脚本2 |
您所在的位置:网站首页 › python凯撒密码超简单转换 › 【python脚本系列】python脚本2 |
【python脚本系列】python脚本2
|
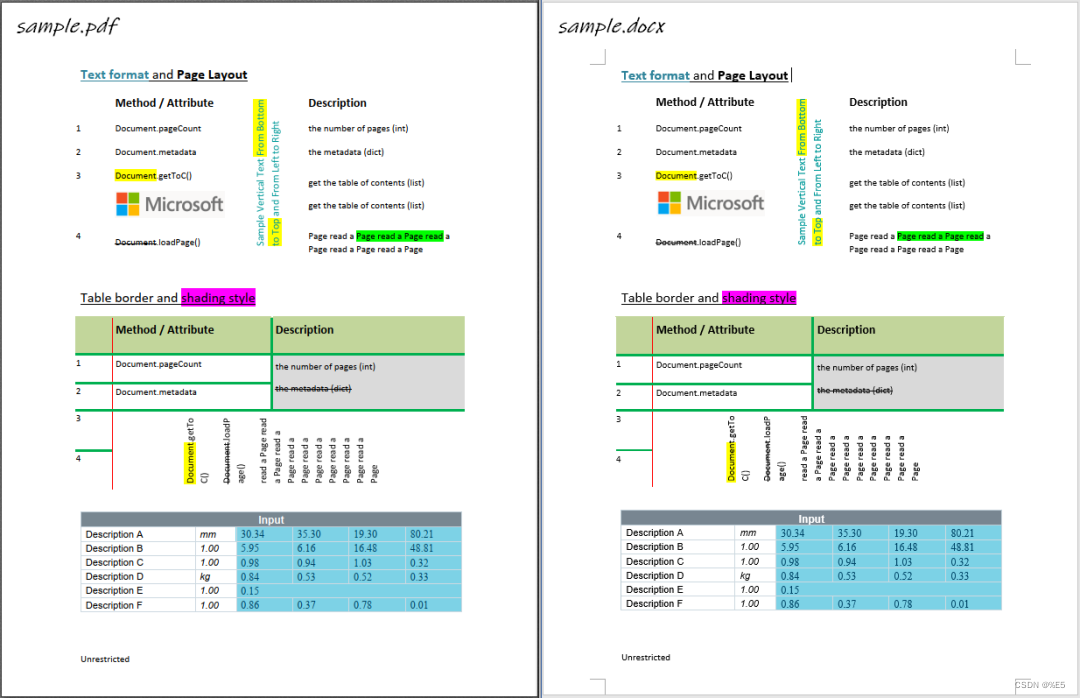
只需2行代码,轻松将PDF转换成Word 机器学习算法那些事 2023-05-05 18:58 发表于广东 编辑:数据分析与统计学之美 可将 PDF 转换成 docx 文件的 Python 库。该项目通过 PyMuPDF 库提取 PDF 文件中的数据,然后采用 python-docx 库解析内容的布局、段落、图片、表格等,最后自动生成 docx 文件。 pdf2docx功能 解析和创建页面布局 页边距章节和分栏 (目前最多支持两栏布局)页眉和页脚 [TODO]解析和创建段落 OCR 文本 [TODO]水平(从左到右)或竖直(自底向上)方向文本字体样式例如字体、字号、粗/斜体、颜色文本样式例如高亮、下划线和删除线列表样式 [TODO]外部超链接段落水平对齐方式 (左/右/居中/分散对齐)及前后间距解析和创建图片 内联图片 灰度/RGB/CMYK等颜色空间图片带有透明通道图片浮动图片(衬于文字下方)解析和创建表格 边框样式例如宽度和颜色单元格背景色合并单元格单元格垂直文本隐藏部分边框线的表格嵌套表格支持多进程转换 pdf2docx同时解析出了表格内容和样式,因此也可以作为一个表格内容提取工具。 限制 目前暂不支持扫描PDF文字识别仅支持从左向右书写的语言(因此不支持阿拉伯语)不支持旋转的文字基于规则的解析无法保证100%还原PDF样式安装 pip install pdf2docx 案例 from pdf2docx import parse pdf_file = ‘/path/to/sample.pdf’ docx_file = ‘path/to/sample.docx’ convert pdf to docxparse(pdf_file, docx_file) Run
参考:网址 |
【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |