python中parsel模块的css解析 |
您所在的位置:网站首页 › python中的parsel库 › python中parsel模块的css解析 |
python中parsel模块的css解析
|
一、爬虫页面分类
1.想要爬取的内容全部在标签中,可以使用xpath去进行解析如下图
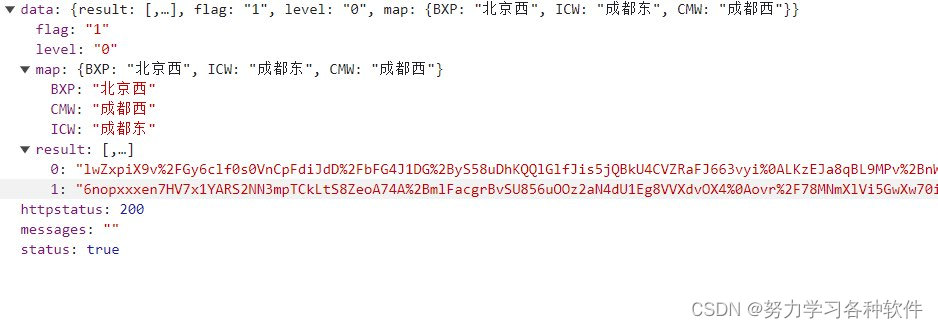
实例化一个selector对象 css格式总结: .代表class #代表id ::text 表示输出文本(即尖括号里面的内容) nth-child(page)表示匹配第page项 例子: div 返回的是全部div标签 div.content 返回的是class = 'content'的整个div标签 div.content #su 返回的是class = 'content'的整个div标签下id = 'su'的标签 div.content li 返回的是class = 'content'的整个div标签下的li标签 div.content li:nth-child(1)返回的是class = 'content'的整个div标签下的li标签中的第一个li标签 div.content li:nth-child(1)::text返回的是class = 'content'的整个div标签下的li标签中的第一个li标签中的文本数据 div.content li:nth-child(1)::attr(href)返回的是class = 'content'的整个div标签下的li标签中的第一个li标签,其中的href所对应的属性值 selector.css('css样式').get() 获得一个匹配的 selector.css('css样式').getall()获得多个匹配的 可以在开发者工具中尝试: 定位要爬取的数据,在elements中ctrl+f出现
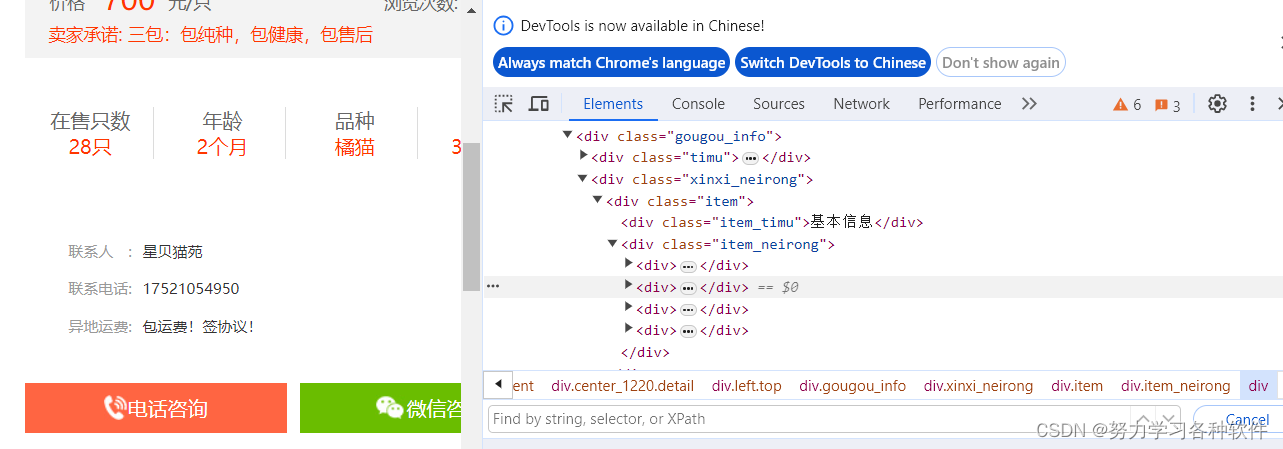
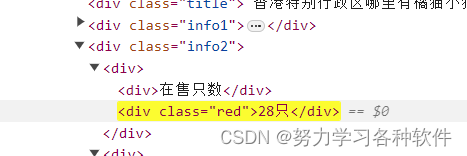
如想爬取在售只数应该怎么写:
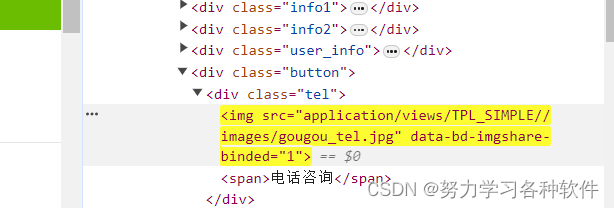
获得下图src的属性值:
注意,编写css时,要像树一样,一层一层找,不能跳的太远,否则会出错 三、在selenimu中用css选择器:代码展现 from selenium import webdriver import parsel import requests path = 'chromedriver.exe' broswer = webdriver.Chrome(path) url = 'http://maomijiaoyi.com/index.php?/chanpinliebiao_c_2.html' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36', } broswer.get(url) for page in range(1,25): selector = broswer.find_element_by_css_selector(f'#content > div.breeds_floor > div > div > a:nth-child({page}) > div.img > img') url = selector.get_attribute('src') print(url) ''' 筛选标签,与css语法一致,不会可以复制,以selector方式复制。find_element_by_css_selector返回的是一个标签,find_elements_by_css_selector返回的是多个标签 获取标签的属性值用selector.get_attribute方法 ''' lis = browser.find_elements_by_css_selector('.Content li') # 获取class=Content的ul的下面所有的li标签 for li in lis: bs = li.find_elements_by_css_selector('b') # 在li标签中找b标签 for b in bs: print(bs.text)# 获取b标签的文本值 |




【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |