python基础(十):文件处理 |
您所在的位置:网站首页 › pythontell,seek方法 › python基础(十):文件处理 |
python基础(十):文件处理
|
文章目录
一、引言
二、python实现操作文件流程
1、操作文件的流程
2、资源回收与with上下文管理
3、指定操作文本文件的字符编码
三、文件操作模式
1、控制文件读写操作的模式
2、r模式的使用
(1)r模式基本知识及使用案例
(2)read方法使用
3、w模式的使用
(1)writelines方法的案例
4、a 模式的使用
5、+ 模式的使用(了解)
(1)r+模式的使用
(2)w+模式的使用
(3)a+模式的使用
6、+模式整体总结
四、控制文件读写内容的模式
1、t模式的使用
2、b模式的使用
五、主动控制文件内指针移动
1、0模式详解
2、1模式详解
3、2模式详解
一、引言
众所周知计算机由应用程序、操作系统、硬件三部分结构。 我们python或其他编程语言编写的程序和数据要想持久化保存,就必须保存到硬盘中。但是我们的应用程序不能直接对硬盘进行操作,操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,文件就是这个接口,应用程序可以通过操作文件实现对硬盘操作。 注意:光理论是不够的,在此送大家一套2020最新Python全栈实战视频教程,点击此处 进来获取 跟着练习下,希望大家一起进步哦! 二、python实现操作文件流程 1、操作文件的流程 - 打开文件,得到一个文件句柄并赋值给一个变量 - 通过句柄对这个文件进行操作 - 关闭文件python实现: f = open('a.txt',mode='rt',encoding='utf-8') #打开文件得到句柄f print(f.read()) #读文件 f.close() #关闭文件
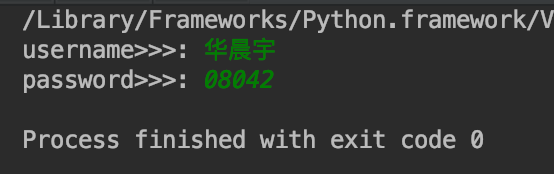
打开一个文件包含两个部分的资源:存储句柄的f占用的内存资源、操作系统打开的文件。在操作完毕一个文件时,这两部分的资源都必须回收。回收方法: f.close() #回收操作系统打开的文件资源 del f #回收存储句柄的f占用的内存资源 #f如果先被删除了,那么你再无法使用f调用close方法关闭文件。其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件无法关闭,白白占用资源, 而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close(),虽然我们如此强调,但是大多数读者还是会不由自主地忘记f.close(),考虑到这一点,python提供了with关键字来帮我们管理上下文: # 1、在执行完子代码块后,with 会自动执行f.close() with open('a.txt','w') as f: pass # 2、可用用with同时打开多个文件,用逗号分隔开即可 with open('a.txt','r') as read_f,open('b.txt','w') as write_f: data = read_f.read() write_f.write(data) #上面这个程序,实现了把一个文件复制到另外一个文件。with上下文时用来在代码块执行完文件操作后,自动关闭文件。 3、指定操作文本文件的字符编码f = open(…)是由操作系统打开文件,如果打开的是文本文件,会涉及到字符编码问题,如果没有为open指定编码,那么打开文本文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。 这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。 f = open(‘a.txt’,‘r’,encoding='utf-8') 三、文件操作模式 1、控制文件读写操作的模式 r(默认的):只读 w:只写 a:只追加写文件指针:总是指向需要操作的文件内容的某个地方。不同模式,开始时,文件指针指向不同的地方。 2、r模式的使用 (1)r模式基本知识及使用案例 # r只读模式: 在文件不存在时则报错,文件存在,文件指针直接跳到文件开头,读取文件指针后的所有内容,不能写。 with open('a.txt',mode='r',encoding='utf-8') as f: res=f.read() # 会将文件的内容由硬盘全部读入内存,赋值给res # 小练习:实现用户认证功能 inp_name=input('请输入你的名字: ').strip() inp_pwd=input('请输入你的密码: ').strip() with open(r'db.txt',mode='r',encoding='utf-8') as f: for line in f: # 把用户输入的名字与密码与读出内容做比对 u,p=line.strip('\n').split(':') if inp_name == u and inp_pwd == p: print('登录成功') break else: print('账号名或者密码错误')for line in f释疑: 对文件对象进行for循环遍历,是将文件中的内容一行行的以字符串赋值给line变量 (2)read方法使用 f.read() #读取所有内容,执行完该操作后,文件指针会移动到文件末尾 f.read(5) #代表读出5个字符 f.readline() #读取一行内容,光标移动到第二行首部 f.readlines() #把文件内容每行作为元素存在一个列表中文件内容: write方法可以写多行,因此它不是拿来写多行的! with open('db.txt',mode='wt') as f: l = ['111\n','222','333'] # f.writelines(l) #这个和下面的代码是一样的效果 for line in l: f.write(line)执行过后db.txt文件中的内容: 小练习运行示例:
这个模式你如果想搞懂,你需要对文件指针有一个清楚的认识,你需要时刻清楚文件指针当前在哪个地方。 # r+ w+ a+ :它们都是代表对文件内容具有可读可写 #在平时工作中,我们只单纯使用r/w/a,要么只读,要么只写,一般不用可读可写的模式它们对文件内容都具有可读可写,那么有什么区别? (1)r+模式的使用r+模式代表以r为主体,读写都具有r的特点 r的特点:不存在文件时,无法读文件,报错;文件存在,从文件内容开始的地方,开始读。r+模式的写操作案例: with open('db.txt', mode='r+', encoding='utf-8') as f: f.write('heihei') info = f.read() print(info)db.txt文件原始内容: haha:123 xixi:admin wowo:456执行结果: 结论: r+模式的读操作和r模式一致 r+模式的写操作,没有文件不会创建文件,会报错 r+模式的写操作是从文件开始处开始写的,且会覆盖原来的内容 (2)w+模式的使用w+模式代表以w为主体,读写都具有w的特点 w的特点:在文件不存在时会创建空文档,文件存在会清空文件,文件指针跑到文件开头。w+模式的读操作案例: with open('db.txt', mode='w+', encoding='utf-8') as f: info = f.read() print(info)执行后文档: a+模式代表以a为主体,读写都具有a的特点 a的特点:在文件不存在时会创建空文档,文件存在会将文件指针直接移动到文件末尾a+模式的读操作案例: with open('db.txt', mode='a+', encoding='utf-8') as f: f.write('haha') info = f.read() print(info)db.txt文件原始内容: 总结: a+模式的写操作和a模式的写操作一致 a+模式的读操作,文件指针一直指向文末,读的都是空白 6、+模式整体总结我们学习了上面三个+模式,发现w+模式和a+模式因为指针位置的问题,导致read功能相当于没有用,一直读的都是空白,r+模式因为指针位置问题,也会出现write添加内容之后,只能读部分内容。因此我们需要可以控制指针的移动,这个会在后面学习到。 四、控制文件读写内容的模式 1、t模式的使用 # t 模式:如果我们指定的文件打开模式为r/w/a,其实默认就是rt/wt/at with open('a.txt',mode='rt',encoding='utf-8') as f: res=f.read() print(type(res)) # 输出结果为: with open('a.txt',mode='wt',encoding='utf-8') as f: s='abc' f.write(s) # 写入的也必须是字符串类型,传整型、浮点型等都不行。 #强调:t 模式只能用于操作文本文件,无论读写,都应该以字符串为单位,而存取硬盘本质都是二进制的形式,当指定 t 模式时,内部帮我们做了编码与解码,所以我们需要指定编码格式,不然可能会出现乱码 2、b模式的使用 # b: 读写都是以二进制位单位 with open('1.mp4',mode='rb') as f: data=f.read() print(type(data)) # 输出结果为: with open('a.txt',mode='wb') as f: # msg="你好" # res=msg.encode('utf-8') # res为bytes类型 # f.write(res) # 在b模式下写入文件的只能是bytes类型 res = bytes("你好",encoding='utf-8') #相当于上面三行代码, f.write(res) f.write('1111\n222\n'.encode('utf-8')) # 针对b模式的写,需要自己写换行符 #强调:b模式对比t模式 1、在操作纯文本文件方面t模式帮我们省去了编码与解码的环节,b模式则需要手动编码与解码,所以此时t模式更为方便 2、针对非文本文件(如图片、视频、音频等)只能使用b模式 # 小练习: 编写拷贝工具 src_file=input('源文件路径: ').strip() dst_file=input('目标文件路径: ').strip() with open(r'{name}'.format(name=src_file),mode='rb') as read_f,open(r'{}'.format(dst_file),mode='wb') as write_f: # for line in read_f: #一般视频文件一行内容可能会过大,这样`在这里插入代码片`按行读取,可能会造成内存不够 # write_f.write(line) while True: res = read_f.read(1024) #按每次1024字节来读 if len(res) == 0 : #按字节读,你需要明确什么时候跳出循环。 break else: write_f.write(res) 五、主动控制文件内指针移动 #大前提:文件内指针的移动都是Bytes为单位的,唯一例外的是t模式下的read(n),n以字符为单位 with open('a.txt',mode='rt',encoding='utf-8') as f: data=f.read(3) # 读取3个字符 with open('a.txt',mode='rb') as f: data=f.read(3) # 读取3个Bytes # 之前文件内指针的移动都是由读/写操作而被动触发的,若想读取文件某一特定位置的数据,则则需要用f.seek方法主动控制文件内指针的移动,详细用法如下: # f.seek(指针移动的字节数,模式控制) 无论是t还是b模式移动的都是字节。 # 模式控制: # 0: 默认的模式,该模式代表指针移动的字节数是以文件开头为参照的 # 1: 该模式代表指针移动的字节数是以当前所在的位置为参照的 # 2: 该模式代表指针移动的字节数是以文件末尾的位置为参照的 # 强调:其中0模式可以在t或者b模式使用,而1跟2模式只能在b模式下用 1、0模式详解 # a.txt用utf-8编码,内容如下(abc各占1个字节,中文“你好”各占3个字节) abc你好 # 0模式的使用 with open('a.txt',mode='rt',encoding='utf-8') as f: f.seek(3,0) # 参照文件开头移动了3个字节 print(f.tell()) # 查看当前文件指针距离文件开头的位置,输出结果为3 print(f.read()) # 从第3个字节的位置读到文件末尾,输出结果为:你好 # 注意:由于在t模式下,会将读取的内容自动解码,所以必须保证读取的内容是一个完整中文数据,否则解码失败 with open('a.txt',mode='rb') as f: f.seek(6,0) print(f.read().decode('utf-8')) #输出结果为: 好 2、1模式详解 # 1模式的使用 with open('a.txt',mode='rb') as f: f.seek(3,1) # 从当前位置往后移动3个字节,而此时的当前位置就是文件开头 print(f.tell()) # 输出结果为:3 f.seek(4,1) # 从当前位置往后移动4个字节,而此时的当前位置为3 print(f.tell()) # 输出结果为:7 3、2模式详解 # a.txt用utf-8编码,内容如下(abc各占1个字节,中文“你好”各占3个字节) abc你好 # 2模式的使用 with open('a.txt',mode='rb') as f: f.seek(0,2) # 参照文件末尾移动0个字节, 即直接跳到文件末尾 print(f.tell()) # 输出结果为:9 f.seek(-3,2) # 参照文件末尾往前移动了3个字节 print(f.read().decode('utf-8')) # 输出结果为:好 # 小练习:实现动态查看最新一条日志的效果 import time with open('access.log',mode='rb') as f: f.seek(0,2) while True: line=f.readline() if len(line) == 0: # 没有内容 time.sleep(0.5) else: print(line.decode('utf-8'),end='')注意:最后送大家一套2020最新企业Pyhon项目实战视频教程,点击此处 进来获取 跟着练习下,希望大家一起进步哦! |

 f.read():
f.read(): f.readline():
f.readline():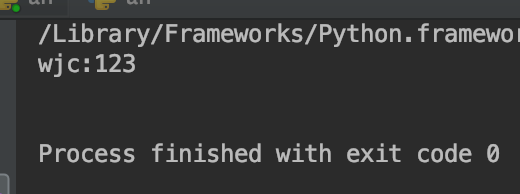 f.readlines():
f.readlines():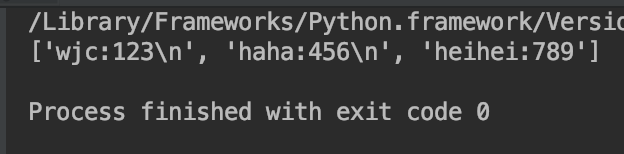 看完三面三个运行结果,有人就有疑问了,为什么readlines方法的运行结果多了个\n?
看完三面三个运行结果,有人就有疑问了,为什么readlines方法的运行结果多了个\n?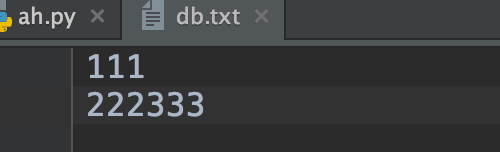
 为什么没有换行呢?
为什么没有换行呢?
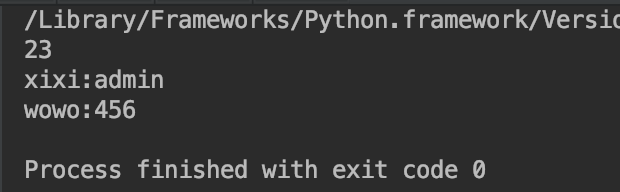 执行后db.txt文件的内容:
执行后db.txt文件的内容: 疑问:为什么read读出来的内容和执行命令后的db.txt文件内容不一致?
疑问:为什么read读出来的内容和执行命令后的db.txt文件内容不一致? 即使你再添加内容,文件指针也一直是在文末,read永远都读的都是空白。总结:
即使你再添加内容,文件指针也一直是在文末,read永远都读的都是空白。总结: 执行后文件的内容:
执行后文件的内容: 运行结果:
运行结果: a+模式中read操作一直都是空白的,这是为什么呢?
a+模式中read操作一直都是空白的,这是为什么呢?【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |