探索主题建模:使用LDA分析文本主题 |
您所在的位置:网站首页 › ppt中应用主题包括一组主题和什么 › 探索主题建模:使用LDA分析文本主题 |
探索主题建模:使用LDA分析文本主题
|
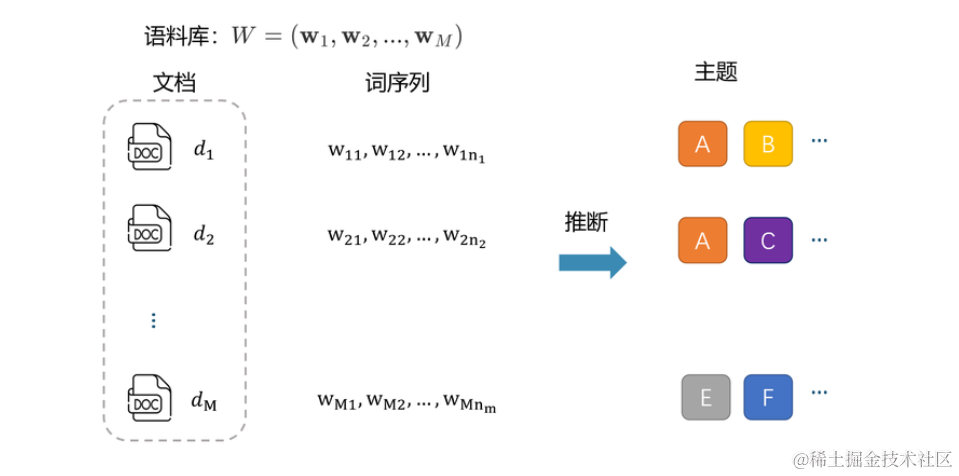
在数据分析和文本挖掘领域,主题建模是一种强大的工具,用于自动发现文本数据中的隐藏主题。Latent Dirichlet Allocation(LDA)是主题建模的一种常用技术。本文将介绍如何使用Python和Gensim库执行LDA主题建模,并探讨主题建模的各个方面。 什么是主题建模?主题建模是一种用于从文本数据中提取主题或话题的技术。主题可以被视为文本数据的概括性描述,它们涵盖了文本中的关键概念。主题建模可以应用于各种领域,如文档分类、信息检索、推荐系统等。 LDA的应用场景LDA(潜在狄利克雷分配)模型在自然语言处理(NLP)领域中有广泛的应用,以下是一些常见的应用场景. 特征生成:LDA可以生成特征供其他机器学习算法使用。例如,LDA为每一篇文章推断一个主题分布;K个主题即是K个数值特征,这些特征可以被用在像逻辑回归或者决策树这样的算法中用于预测任务。新闻质量分类:新闻APP通过各种来源获得到的新闻的质量良莠不齐。我们可以人工设计一些传统特征:新闻来源站点、新闻内容长度、图片数量、新闻热度等等。除了这些人工特征,也可利用主题模型来计算每篇新闻的主题分布,作为附加特征与人工特征一起组成新特征集合。短文本-短文本语义匹配:短文本-短文本的语义匹配在工业界的应用场景非常广泛。例如,在网页搜索中,我们需要度量用户查询 (query) 和网页标题 (web page title) 的语义相关性;在query推荐中,我们需要度量query和其他query之间的相似度。短文本-长文本语义匹配:短文本-长文本语义匹配的应用场景在工业界非常普遍。例如,在搜索引擎中,我们需要计算一个用户查询(query)和一个网页正文(content)的语义相关度。长文本-长文本语义匹配:通过使用主题模型,我们可以得到两个长文本的主题分布,再通过计算两个多项分布的距离来衡量它们之间的相似度。新闻个性化推荐:长文本-长文本的语义匹配可用于个性化推荐的任务中。例如,在新闻个性化推荐中,我们可以将用户近期阅读的新闻(或新闻标题)合并成一篇长“文档”,并将该“文档”的主题分布作为表达用户阅读兴趣的用户画像。垂类新闻CTR预估:新闻推荐服务涉及多个垂类新闻方向,如体育、汽车、娱乐等。在这些方向上,我们往往需要做更精细的个性化推荐。 使用LDA进行主题建模Latent Dirichlet Allocation(LDA)是一种用于主题建模的概率图模型。它的基本思想是,每个文档是由一组主题混合而成的,每个主题又由一组词汇构成。LDA试图找到最佳的主题和词汇组合,以解释给定的文本数据。
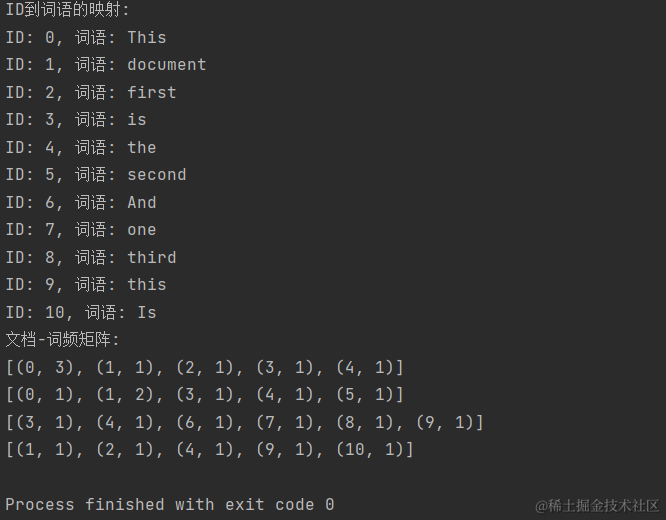
对底层逻辑感兴趣的掘友们可以参考这些文章: https://zhuanlan.zhihu.com/p/309419680 https://zhuanlan.zhihu.com/p/31470216 以下是如何使用Python和Gensim库执行LDA主题建模的步骤: 步骤1:文本预处理在进行主题建模之前,需要对文本进行预处理。这包括分词、去除停用词和标点符号等。分词可以使用工具如jieba,去除停用词可以使用nltk库。 样例: # 中文文本分词 def tokenize(text): return list(jieba.cut(text)) # 删除中文停用词 def delete_stopwords(text,tokens): # 分词 words = tokens # 假设你已经有分好词的文本,如果没有,你可以使用jieba等工具进行分词 # 加载中文停用词 stop_words = set(stopwords.words('chinese')) # 去除停用词 filtered_words = [word for word in words if word not in stop_words] # 重建文本 filtered_text = ' '.join(filtered_words) return filtered_text def remove_punctuation(input_string): import string # 制作一个映射表,其中所有的标点符号都被映射为None all_punctuation = string.punctuation + "!?。。"#$%&'()*+,-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏.\t " translator = str.maketrans('', '', all_punctuation) # 使用映射表来移除所有的标点符号 no_punct = input_string.translate(translator) return no_punct这些函数可以用于文本预处理,以准备文本数据进行自然语言处理任务。以下是函数的说明: tokenize(text) : 这个函数使用jieba分词库来将中文文本分成词语。它接受一个文本字符串作为输入,返回一个包含分词结果的列表。delete_stopwords(text, tokens) : 这个函数用于删除中文文本中的停用词。它接受两个参数,文本字符串和分好词的文本(词语列表)。函数首先加载了中文停用词表,然后将文本中的停用词去除,最后返回一个去除停用词后的文本字符串。remove_punctuation(input_string) : 这个函数用于去除文本中的标点符号。它使用一个映射表,将所有标点符号映射为None,从而删除它们。最后,它返回一个去除标点符号后的文本字符串。这样就完成了简单的数据预处理. 步骤2:创建字典和文档-词频矩阵LDA 采用词袋模型。所谓词袋模型,是将一篇文档,我们仅考虑一个词汇是否出现,而不考虑其出现的顺序。在词袋模型中,“我喜欢你”和“你喜欢我”是等价的。与词袋模型相反的一个模型是n-gram,n-gram考虑了词汇出现的先后顺序。 使用Gensim库,可以创建文档的字典和文档-词频矩阵。字典包含了所有文档中的词汇,而文档-词频矩阵表示每个文档中每个词汇的词频。 # 创建字典和文档-词频矩阵 dictionary = corpora.Dictionary([tokens]) corpus = [dictionary.doc2bow(tokens)] dictionary = corpora.Dictionary([tokens]) : 这行代码创建了一个文档的词汇表(Dictionary)。词汇表用于将文本中的词语映射到唯一的ID。tokens 是一个包含分好词的文本数据的列表。创建词汇表是为了建立每个词语与一个唯一ID之间的映射,以便后续处理。corpus = [dictionary.doc2bow(tokens)] : 这行代码创建了文档-词频矩阵(Corpus)。corpus 是一个包含文档的列表,每个文档都表示为一个词袋(Bag of Words),其中包含了文档中每个词语的ID和词频。doc2bow 方法将文档中的词语转化为词袋表示。为方便理解这两个类型的数据结构,参考下面代码样例演示: def test(): from gensim import corpora # 创建一个样本文本数据 sample_texts = [ "This is the first document This This ", "This document is the second document ", "And this is the third one ", "Is this the first document " ] # 分词并创建词汇表 tokenized_texts = [text.split() for text in sample_texts] dictionary = corpora.Dictionary(tokenized_texts) # 获取词汇表中的词语到ID的映射 word_to_id = dictionary.token2id # 获取ID到词语的映射 id_to_word = {v: k for k, v in word_to_id.items()} # 打印ID到词语的映射 print("ID到词语的映射:") for word_id, word in id_to_word.items(): print(f"ID: {word_id}, 词语: {word}") # 创建文档-词频矩阵 corpus = [dictionary.doc2bow(tokens) for tokens in tokenized_texts] # 打印文档-词频矩阵 print("文档-词频矩阵:") for doc in corpus: print(doc)运行结果为
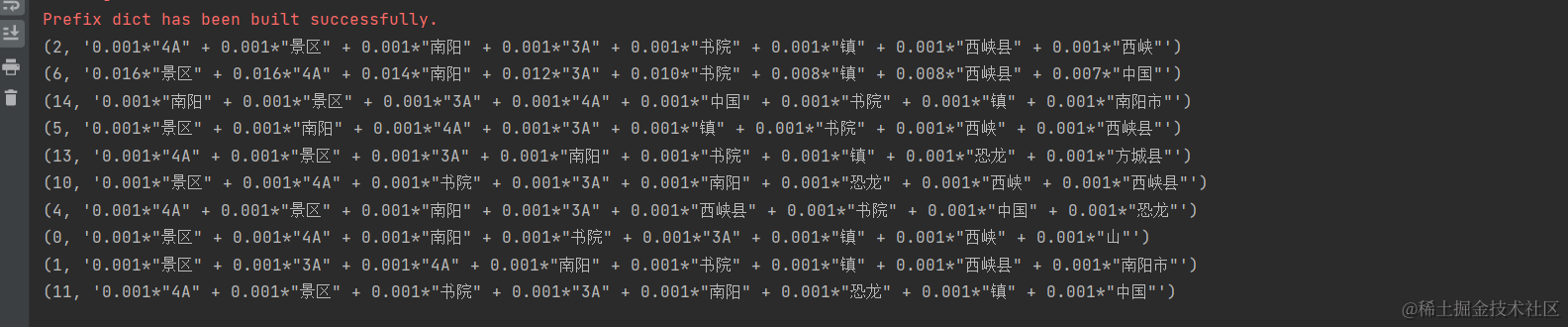
使用Gensim的LdaModel类,可以运行LDA模型。需要指定主题数量、字典和文档-词频矩阵作为输入参数。模型将自动学习主题和词汇的分布。 # 运行LDA模型 lda_model = models.LdaModel(corpus, num_topics=15, id2word=dictionary, passes=50) num_topics 表示预期生成的主题数量。在LDA中,这是一个需要预先指定的超参数。我们需要根据你的数据和分析目标来选择合适的主题数量。通常,我们可以根据领域知识或试验来确定主题数量。passes 是模型的迭代次数。LDA模型通过多次迭代来优化主题的分布以及文档-主题和词语-主题的分布。增加 passes 的值通常会提高模型的性能,但也会增加训练时间。通常情况下,10-50 之间的 passes 值是常见的选择,具体取决于数据集的大小和复杂性。 步骤4:提取主题一旦模型训练完成,可以使用show_topics方法提取主题。每个主题由一组高权重词汇表示。 # 提取主题 topics = lda_model.show_topics(num_words=8) # 输出主题 for topic in topics: print(topic)如下所示: 前边的序号为主题id,后边的词是主题相关词,相关词前边的是该相关词在主题中的权重. 步骤5:结果分析最后,对提取的主题进行分析和解释。可以查看高权重词汇,了解主题的内容,以及使用主题模型进行文档分类、信息检索等应用。 如何保存和加载模型在实际应用中,通常需要保存训练好的LDA模型,以便下次使用。可以使用Gensim的save和load方法来保存和加载模型。 保存模型: from gensim import corpora, models import os # 假设你已经有一个语料库 `corpus` 和字典 `dictionary`,以及训练好的 LDA 模型 `lda_model` # 保存字典 dictionary.save("my_dictionary.dict") # 保存语料库 corpora.MmCorpus.serialize("my_corpus.mm", corpus) # 保存 LDA 模型 lda_model.save("my_lda_model.model")加载模型: from gensim import corpora, models # 加载字典 dictionary = corpora.Dictionary.load("my_dictionary.dict") # 加载语料库 corpus = corpora.MmCorpus("my_corpus.mm") # 加载 LDA 模型 lda_model = models.LdaModel.load("my_lda_model.model") 权重值的作用在LDA模型中,每个词汇都有一个权重值,表示它在主题中的重要性。这些权重值可以用于主题识别、文档分类和信息检索。高权重词汇通常与主题相关,因此可以帮助理解主题内容,或是建立主题词云图. 总结主题建模是文本挖掘领域的重要技术,可以自动发现文本数据中的主题。LDA是一种常用的主题建模方法,可以通过Python和Gensim库进行实现。通过文本预处理、模型训练和结果分析,可以有效地提取文本数据中的隐藏主题,用于各种应用。 |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |