nceloss/info nceloss |
您所在的位置:网站首页 › nlp理论 › nceloss/info nceloss |
nceloss/info nceloss
对比学习损失函数比较常用的有nceloss/infonecloss等 NCE Loss求通俗易懂解释下nce loss? Noise Contrastive Estimation Loss(NCE loss)是从nlp(自然语言处理)领域提出的,主要解决的分类问题中类别数过多导致的softmax交叉熵损失函数计算量过大的问题。参考如上的资料,给出nce loss的解释. 参看softmax公式:  1.x,y是正例,比如x是user,y是该用户点击过的item2.y^{\prime}是x的负例,理论上应该取自整个y的集合(公式中的I)。比如,在u2i召回中,应该取自整个物料集。3.F(x,y)代表x,y之间的匹配度,是我们的模型要建模的目标 问题在于分母问题就在于分母\sum_{y^\prime \in I} exp(F(x,y^{\prime})),理论上需要user和库中所有item都计算一遍,特别当库非常巨大时,这种计算大到不现实. 而NCE的思想就是将这种巨量softmax计算问题转换为多个二分类问题. 以u2i为例,描述如下 给定一个用户x_i他点击过的物料是正例,来自一个集合T_i再给x_i按照某个概率Q(y|x)采样一部分物料当负例,组成负例集合S_i。这些负例也就是NCE中的“N”所说的噪声noise那么一个用户x_i的所有候选集合,不再像理论softmax那样是整个物料库,而是一个有限集合C_i=T_i \bigcup S_iNCE的二分类问题是,对于每个候选物料\forall y\in C_i y属于T_i,算一个正样本,label=1y属于S_i,算一个负样本,label=0那么y属于T_i的odds有多大?这里的odds可以理解成logit,就是未归一化的概率。应该等于y属于x的正例的概率P(y|x),与y属于x的负例(即,来自噪声)的概率Q(y|x),二个概率之差。即,y对应label=1的logit,G(y|x)=\log\frac{P(y|x)}{Q(y|x)}=\log P(y|x)-\log Q(y|x)。如果使以上公式更通用一些,不再用P(y|x)这样一个表示概率的小数,而是用F(y|x)表示我们模型建模的目标,比如双塔中,F(x,y)就是最后user embedding与item embedding的点积。那么给定一个样本(x,y),它属于label=1(即y\in T_i)的logit,G(x,y)=F(x,y) - \log Q(y|x)也就是要对模型的输出F(x,y)进行修正,修正量与负采样到相同y的概率Q(y|x)有关。至于第i个样本上loss,就是C_i中每个正负样本上的binary cross-entropy loss之和\begin{aligned} L_{NCE} &=-[\sum_{y_i \in T_i}\log\sigma(G(x_i,y_i)) + \sum_{y_i^{\prime}\in S_i}\log(1-\sigma(G(x_i,y_i^{\prime})))] \\ &=\sum_{y_i \in T_i}\log(1+exp(-G(x_i,y_i)))+\sum_{y_i^{\prime} \in S_i}\log(1+exp(G(x_i,y_i^{\prime}))) \end{aligned} \\其中\sigma是sigmoid函数。而G(x,y)=F(x,y) - \log Q(y|x),是修正后的x,y匹配度 说了这么多,感觉就一句话,用在集合的子集上的分类尽可能的逼近在原有集合上的效果NCE是有着很强的理论保证的,如果负采样足够多,那么nce loss的梯度与原始超大规模softmax的梯度趋于一致。info NCE Loss有了如上nce loss的简答描述,info necloss是nce的一个简答变体,引入的主要思想是 如果你只把问题看作是一个二分类,只有数据样本和噪声样本的话,可能对模型学习不友好,因为很多噪声样本可能本就不是一个类,因此还是把它看成一个多分类问题比较合理(但这里的多分类k指代的是负采样之后负样本的数量),如下公式: 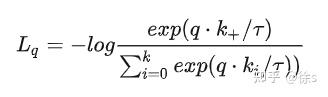 粗看,info nce loss和softmax交叉熵公式很像,如下为softmax公式:  交叉熵损失函数如下:  在有监督学习下,ground truth是一个one-hot向量,softmax的结果\hat y_+取-log,再与ground truth相乘之后,即得到如下交叉熵损失:  上式中的k在有监督学习里指的是这个数据集一共有多少类别,比如CV的ImageNet数据集有1000类,k就是1000。对于对比学习来说,理论上也是可以用上式去计算loss,但是实际上是行不通的。为什么呢?以CV领域的ImageNet数据集来举例,该数据集一共有128万张图片,我们使用数据增强手段(例如,随机裁剪、随机颜色失真、随机高斯模糊)来产生对比学习正样本对,每张图片就是单独一类,那k就是128万类,而不是1000类了,有多少张图就有多少类。但是softmax操作在如此多类别上进行计算是非常耗时的,再加上有指数运算的操作,当向量的维度是几百万的时候,计算复杂度是相当高的。 在infoness Loss的公式中, q\cdot k 是模型出来的logits,相当于上文softmax公式中的z,\tau是一个温度超参数,是个标量,假设我们忽略\tau,那么infoNCE loss其实就是cross entropy loss。唯一的区别是,在cross entropy loss里,k指代的是数据集里类别的数量,而在对比学习InfoNCE loss里,这个k指的是负样本的数量温度系数的作用 温度系数\tau虽然只是一个超参数,但它的设置是非常讲究的,直接影响了模型的效果。 上式Info NCE loss中的q\cdot k相当于是logits,温度系数可以用来控制logits的分布形状。对于既定的logits分布的形状,当\tau值变大,则1/\tau就变小,q\cdot k/\tau则会使得原来logits分布里的数值都变小,且经过指数运算之后,就变得更小了,导致原来的logits分布变得更平滑。相反,如果\tau取得值小,1/\tau就变大,原来的logits分布里的数值就相应的变大,经过指数运算之后,就变得更大,使得这个分布变得更集中,更peak. 如果温度系数设的越大,logits分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。如果温度系数设的过小,则模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差。 |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |