常见的预测模型及算法 |
您所在的位置:网站首页 › nba最新预测 › 常见的预测模型及算法 |
常见的预测模型及算法
|
预测模型
1. 时间序列分析2.机器学习预测模型2.1 决策树2.2 支持向量机回归(SVR)
如果得到一份数据集,任务是要预测出一系列的值,而在预测任务中,我们大多数都采用的是拟合的方法,这篇文字主要介绍三种预测方法时间序列分析,灰色预测模型,神经网络。
1. 时间序列分析
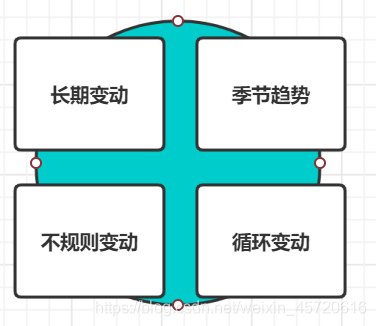
时间序列也叫动态序列,数据是按时间和数值性成的序列。而时间序列分析有三种作用,大致可以描述为描述过去,分析规律,预测将来。接下来将会讲到三种模型(季节分解,指数平滑,ARIMA模型)。 一般情况下时间序列的数值变化规律有四种(长期趋势T,循环变动C,长期趋势T,不规则变动I)。我们先要对数据做出时间序列图,观察数据随周期的变化,进而判断序列是否随周期波动大,如果说整体序列随周期波动大,或波动不大,我们对其进行季节性分解,分别采用乘法和叠加模型。 至于缺失值可以自己选择方法填补,这里主要介绍该模型的思想以及步骤。下面介绍具体预测模型。 首先介绍的是指数平滑模型 指数平滑大致分为简单平滑,Holt线性趋势模型,阻尼趋势模型,简单季节性 和温特模型 简单平滑模型 这里截取了一个文章的段落。 阻尼趋势模型 适用条件:线性趋势逐渐减弱且不含季节成分。Hole的线性趋势模型对未来预测值过高,这此基础上对该模型调整,加入阻力效应有效缓解较高的线性趋势。 模型如下: 通过观察数据,在每年中三月和十二月中,在一个周期内明显比其他月份的销售额大,并且随着周期的进行,我们发现整体时间序列数据随周期波动逐渐升高,因而,我们对该时间序列采用乘法模型的季节性分解,分解后如下图:
这篇博客介绍决策树还可以,借助这篇博客,用sklearn实现回归树 决策树介绍 from sklearn.datasets import load_diabetes from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_score from sklearn.tree import DecisionTreeRegressor #导入内置数据集 X, y = load_diabetes(return_X_y=True) #切分训练集和测试集 train_x,test_x,train_y,test_y = train_test_split(X,y,test_size=0.3) #构建回归树模型 regressor = DecisionTreeRegressor(random_state=0).fit(train_x,train_y) #十折交叉验证模型的性能 cross_val_score(regressor, X, y, cv=10) #预测 regressor.predict(test_x)另外可以对决策树可视化,效果图: 支持向量分类产生的模型(如上所述)仅依赖于训练数据的一个子集,因为构建模型的成本函数不关心超出边界的训练点。类似地,支持向量回归生成的模型仅依赖于训练数据的一个子集,因为成本函数忽略了预测接近其目标的样本。 支持向量回归有 3 种不同的实现: SVR、NuSVR和LinearSVR。LinearSVR 提供比SVR但仅考虑线性内核更快的实现,同时NuSVR实现与SVR和略有不同的公式LinearSVR。 具体实现如下: from sklearn.model_selection import train_test_split import numpy as np from sklearn.svm import SVR from sklearn import metrics from sklearn.metrics import accuracy_score,precision_score, recall_score ''' X:特征向量 y:样本的目标值 trn_x:训练集的特征 val_x:测试集的特征 trn_y:训练集的目标值 val_y:测试集的目标值 ''' trn_x, val_x, trn_y, val_y = train_test_split(X, y, test_size=0.3, random_state=42) ''' kernel参数可选:{'linear','rbf','sigmoid'...} ''' clf2 = SVR(kernel='linear',C=15,gamma='auto',probability=True,random_state=42).fit(trn_x,trn_y) resu = clf2.predict(val_x) y_pred_gbc = clf2.predict_proba(val_x)[:,1] y_pred = clf2.predict(val_x) y=np.array(val_y) print('-'*10,'svm','-'*10) fpr, tpr, thresholds = metrics.roc_curve(y,y_pred_gbc,pos_label=1) #输出测试集的Accuracy print('acc',accuracy_score(val_y,y_pred)) |

 这里说明一下平滑参数α的选择:(1)如果时间序列不规则起伏但长期趋于一个较稳定的数,那么α在(0.05,0.2)之间,(2)如果序列有明显的变化,那么α在(0.3,0.5)之间,(3)如果序列变化比较缓慢则,α在(0.1,0.4)之间。要注意的是,这个模型只能预测一期数据,原因是他的预测公式。
这里说明一下平滑参数α的选择:(1)如果时间序列不规则起伏但长期趋于一个较稳定的数,那么α在(0.05,0.2)之间,(2)如果序列有明显的变化,那么α在(0.3,0.5)之间,(3)如果序列变化比较缓慢则,α在(0.1,0.4)之间。要注意的是,这个模型只能预测一期数据,原因是他的预测公式。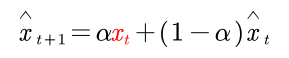 这里我们的第一项是要预测的。如果预测出来,再想要预测t+2时的数据,可见我们需要Xt+1的真实数据,而我们不存在它的真实数据,最终预测t+2时只能用t+1预测值代替,带入方程中就会得到Xt+2=Xt+1。就会有下面的现象。
这里我们的第一项是要预测的。如果预测出来,再想要预测t+2时的数据,可见我们需要Xt+1的真实数据,而我们不存在它的真实数据,最终预测t+2时只能用t+1预测值代替,带入方程中就会得到Xt+2=Xt+1。就会有下面的现象。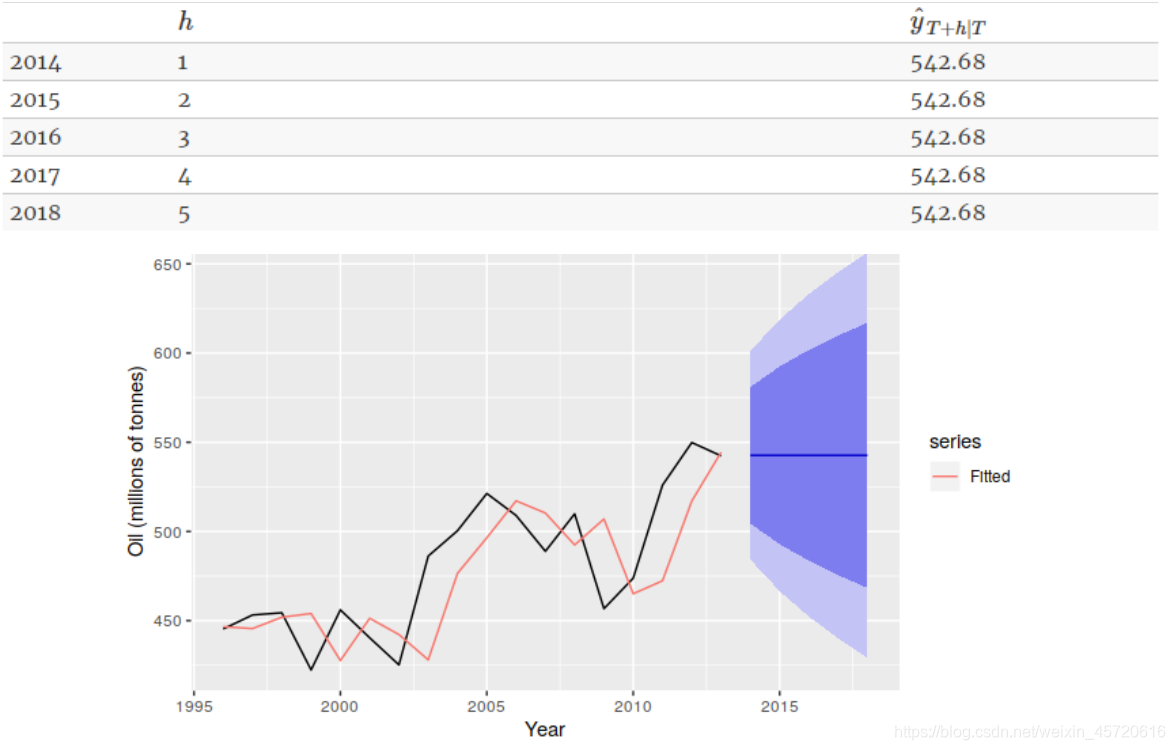 当再到2014后面时都为一个数。各个模型的具体介绍及比较 Hole现象趋势模型 Hole对简单的指数平滑模型进行了延申,能够预测包含趋势的数据,该方法包含一个预测方程和两个平滑方法。适用条件:线性趋势,不含季节成分。此外还有Brown线性趋势模型是此模型的特例。
当再到2014后面时都为一个数。各个模型的具体介绍及比较 Hole现象趋势模型 Hole对简单的指数平滑模型进行了延申,能够预测包含趋势的数据,该方法包含一个预测方程和两个平滑方法。适用条件:线性趋势,不含季节成分。此外还有Brown线性趋势模型是此模型的特例。 
 如下是两模型的比较,红色指的是加入阻尼后的模型,蓝色指的是Hole线性趋势模型。
如下是两模型的比较,红色指的是加入阻尼后的模型,蓝色指的是Hole线性趋势模型。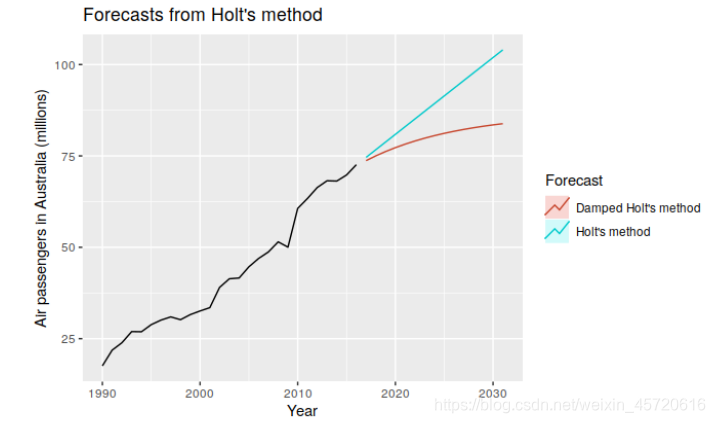 简单季节性 适用条件:含有稳定的季节性,不含趋势。模型如下:
简单季节性 适用条件:含有稳定的季节性,不含趋势。模型如下: 温特加法与温特乘法 他们的适用条件均是含有季节性和稳定的季节成分,但是前面提到过,加法和乘法的选择是要看时间序列的波动性,呈周期波动大的则是乘法,反之是加法。下面分别是温特加法和温特乘法。
温特加法与温特乘法 他们的适用条件均是含有季节性和稳定的季节成分,但是前面提到过,加法和乘法的选择是要看时间序列的波动性,呈周期波动大的则是乘法,反之是加法。下面分别是温特加法和温特乘法。
 从图中更清楚的看到他们的区别,一者预测波动较大的另一个预测波动较为平缓的。
从图中更清楚的看到他们的区别,一者预测波动较大的另一个预测波动较为平缓的。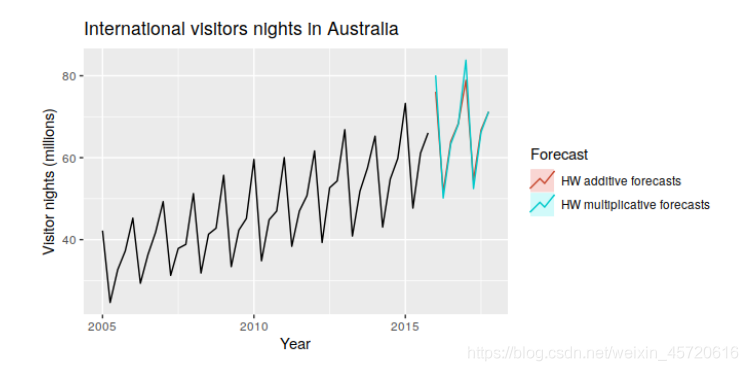 此外运用这些模型要需要时间序列的平稳性,若平稳度低,并时间序列间隔与预测无关即协方差为0则说明Xt是个白噪声序列。一般用ACF和PACF检测但是这两种检测偶然情况太多,很难判断出来,下文会提到,如果是ARMA模型,根本判断不出来。 由上面的指数平滑模型,这里预测女装的销售额,
此外运用这些模型要需要时间序列的平稳性,若平稳度低,并时间序列间隔与预测无关即协方差为0则说明Xt是个白噪声序列。一般用ACF和PACF检测但是这两种检测偶然情况太多,很难判断出来,下文会提到,如果是ARMA模型,根本判断不出来。 由上面的指数平滑模型,这里预测女装的销售额,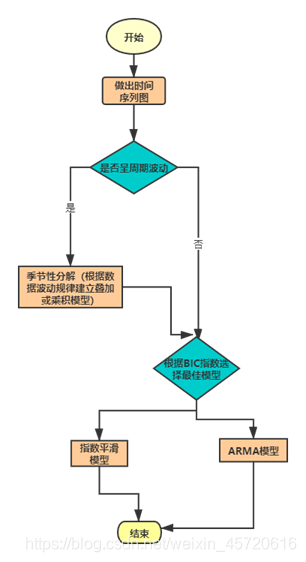 首先对数据做出时间序列图:
首先对数据做出时间序列图: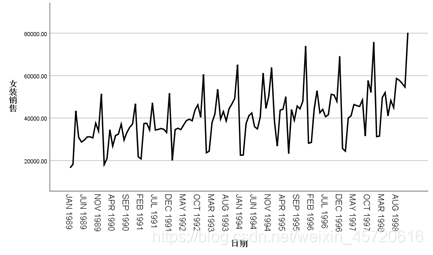 从中发现整体序列呈周期波动越来越大,因此,本文采用叠加模型对周期进行季节性分解。因时间序列数据受季节性影响较大和数据的波动规律,本文选取温特的乘法模型。
从中发现整体序列呈周期波动越来越大,因此,本文采用叠加模型对周期进行季节性分解。因时间序列数据受季节性影响较大和数据的波动规律,本文选取温特的乘法模型。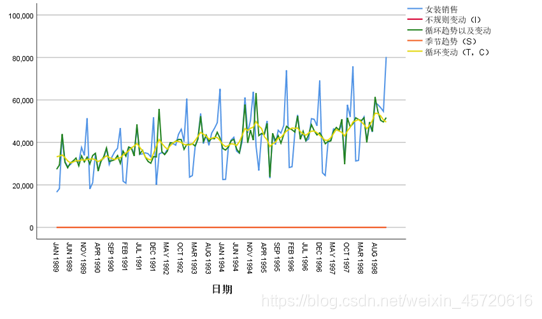
 由于时间序列数据受季节性波动影响较大,本文采用温特乘法(Winter’s multiplicative)模型对数据建模
由于时间序列数据受季节性波动影响较大,本文采用温特乘法(Winter’s multiplicative)模型对数据建模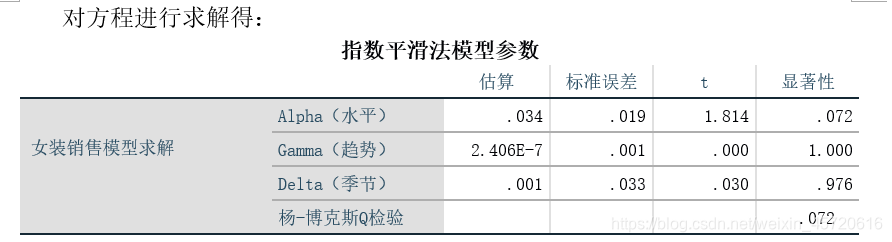 说明温特乘法序列模型的三个参数α,β,γ的值分别为0.034,2.4.6E-7,0.001,且此时Q检验服从原假设,并且做出残差ACF以及残差PACF图如下,可见在ACF检验中,所由滞后性阶数均与0无差异,而PACF中可能存在少许误差,说明扰动项噪声数据基本属于白噪声,温特乘法能够较好低识别本数据。
说明温特乘法序列模型的三个参数α,β,γ的值分别为0.034,2.4.6E-7,0.001,且此时Q检验服从原假设,并且做出残差ACF以及残差PACF图如下,可见在ACF检验中,所由滞后性阶数均与0无差异,而PACF中可能存在少许误差,说明扰动项噪声数据基本属于白噪声,温特乘法能够较好低识别本数据。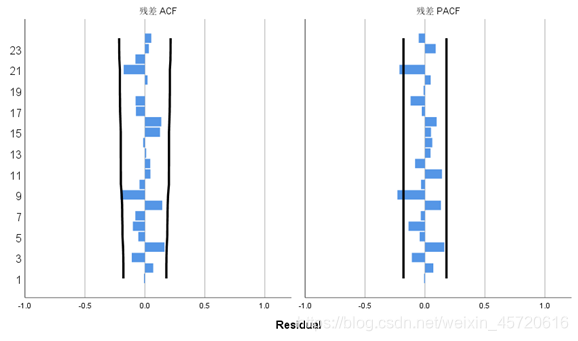 根据温特乘法,预测出的数据如下图所示,实际值与拟合值趋势基本符合,根据上表,拟合优度有0.815,说明拟合效果良好,预测出来的数据也显示出了周期性和波动的趋势。 最后预测出十年女装销售额的数据如下:
根据温特乘法,预测出的数据如下图所示,实际值与拟合值趋势基本符合,根据上表,拟合优度有0.815,说明拟合效果良好,预测出来的数据也显示出了周期性和波动的趋势。 最后预测出十年女装销售额的数据如下: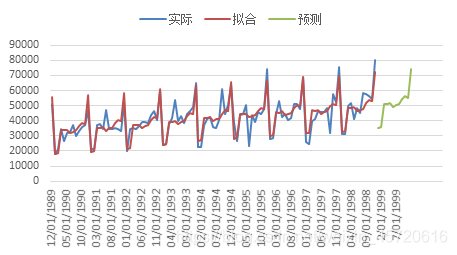
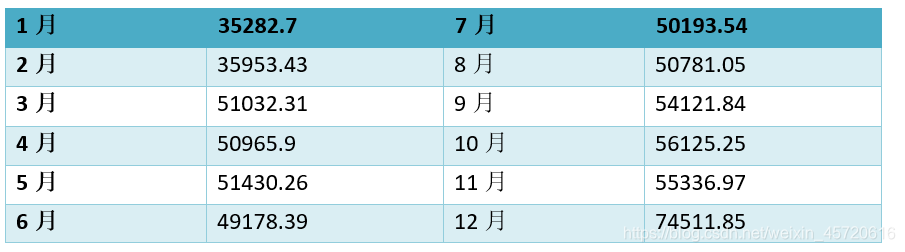
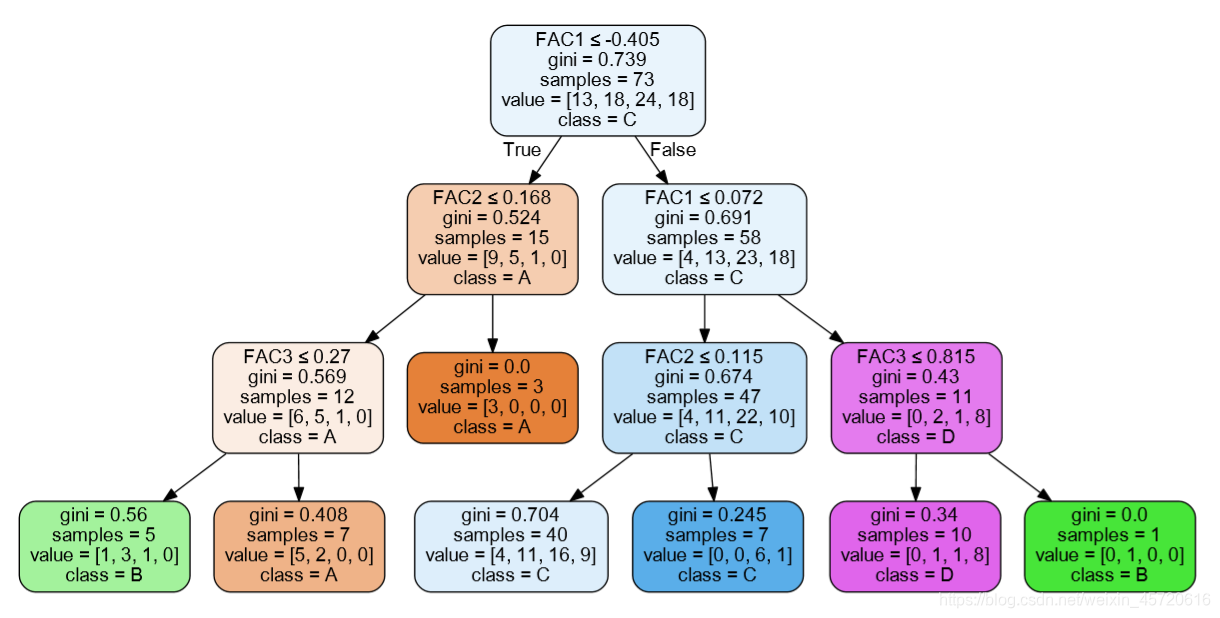 附上实现的连接:可视化
附上实现的连接:可视化【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |