应用训练MNIST的CNN模型识别手写数字图片完整实例(图片来自网上) |
您所在的位置:网站首页 › mnist手写数字图片 › 应用训练MNIST的CNN模型识别手写数字图片完整实例(图片来自网上) |
应用训练MNIST的CNN模型识别手写数字图片完整实例(图片来自网上)
|
1 思考训练模型如何进行应用
通过CNN训练的MNIST模型如何应用来识别手写数字图片(图片来自网上)? 这个问题困扰了我2天,网上找的很多代码都是训练模型和调用模型包含在一个.py文件中,这样子每一次调用模型都需要重新训练一次模型,这种方法显然效率低下; 我想到要把训练模型的.py文件和调用模型预测的.py文件分开,但是调用模型的.py文件该怎么写,很多回答都是如下所示: saver = tf.train.Saver() # 定义saver with tf.Session() as sess: sess.run(intt) # 载入模型 saver.restore(sess,"./save/model.ckpt")这个回答不是我要的答案,我觉得载入的模型要起作用,起码应该有个输入输出的参数,于是我想要在两个.py文件之间传递参数,我收到的结果是: from xxx import 参数 获取xxx.py文件的参数但是我这样写之后,直接是把训练模型的文件重新跑了一遍,这不是我要的效果,而且最后的图片识别也报错,程序执行中断; 终于我无意间看到了下面这篇文章: 多层神经网络建模与模型的保存还原 https://www.cnblogs.com/HuangYJ/p/11681357.html
从上图(main graph)可以直观看出我们一共需要定义的模型结构有10个: input image conv_layer1 pooling_layer1 conv_layer2 pooling_layer2 fc_layer3 dropout output_fc_layer4 softmax10个结构的代码(函数定义的代码没放上来): with tf.name_scope('input'): x=tf.placeholder(tf.float32,[None,784]) y_=tf.placeholder('float',[None,10]) with tf.name_scope('image'): x_image=tf.reshape(x,[-1,28,28,1]) tf.summary.image('input_image',x_image,8) with tf.name_scope('conv_layer1'): W_conv1=weight_variable([5,5,1,32]) b_conv1=bias_variable([32]) h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1) with tf.name_scope('pooling_layer1'): h_pool1=max_pool_2x2(h_conv1) with tf.name_scope('conv_layer2'): W_conv2=weight_variable([5,5,32,64]) b_conv2=bias_variable([64]) h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2) with tf.name_scope('pooling_layer2'): h_pool2=max_pool_2x2(h_conv2) with tf.name_scope('fc_layer3'): W_fc1=weight_variable([7*7*64,1024]) b_fc1=bias_variable([1024]) h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64]) h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1) with tf.name_scope('dropout'): keep_prob=tf.placeholder(tf.float32) h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob) with tf.name_scope('output_fc_layer4'): W_fc2=weight_variable([1024,10]) b_fc2=bias_variable([10]) with tf.name_scope('softmax'): y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2) 3 构造模型的输入和输出换一种说法,我们要调用这个训练好的模型,是希望我们输入一张手写数字图片,模型能自动帮我们识别出这张图片上的数字,并打印出来。以上是我们要达到的目的,但是训练的模型本质还是做数学运算,图片输入和识别数字输出都要根据模型来确定。 模型的输入要求的是一维张量(向量),图像要求是28*28的尺寸,一共784个像素点,需要由2维张量(矩阵)展开成一维张量,以下代码实现: text = Image.open('./images/text3.png') # 载入图片 data = list(text.getdata()) picture=[(255-x)*1.0/255.0 for x in data] #picture作为调用模型的输入模型的输出是经过softmax函数运算的输出,是一长串概率数组,我们要找出最大的概率对应的数字,这个数字就是调入的模型预测到的结果,以下代码实现: # 进行预测 prediction = tf.argmax(y_conv,1)#找概率最大对应的数字 predict_result = prediction.eval(feed_dict={x: [picture],keep_prob:1.0},session=sess) print("你导入的图片是:",predict_result[0]) 4 应用模型进行识别的完整.py代码 from PIL import Image import tensorflow.compat.v1 as tf tf.disable_v2_behavior() #---设置模型参数--- def weight_variable(shape):#权重函数 initial=tf.truncated_normal(shape,stddev=0.1) return tf.Variable(initial) def bias_variable(shape):#偏置函数 initial=tf.constant(0.1,shape=shape) return tf.Variable(initial) def conv2d(x,W): return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME') def max_pool_2x2(x): return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') with tf.name_scope('input'): x=tf.placeholder(tf.float32,[None,784]) y_=tf.placeholder('float',[None,10]) with tf.name_scope('image'): x_image=tf.reshape(x,[-1,28,28,1]) tf.summary.image('input_image',x_image,8) with tf.name_scope('conv_layer1'): W_conv1=weight_variable([5,5,1,32]) b_conv1=bias_variable([32]) h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1) with tf.name_scope('pooling_layer1'): h_pool1=max_pool_2x2(h_conv1) with tf.name_scope('conv_layer2'): W_conv2=weight_variable([5,5,32,64]) b_conv2=bias_variable([64]) h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2) with tf.name_scope('pooling_layer2'): h_pool2=max_pool_2x2(h_conv2) with tf.name_scope('fc_layer3'): W_fc1=weight_variable([7*7*64,1024]) b_fc1=bias_variable([1024]) h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64]) h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1) with tf.name_scope('dropout'): keep_prob=tf.placeholder(tf.float32) h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob) with tf.name_scope('output_fc_layer4'): W_fc2=weight_variable([1024,10]) b_fc2=bias_variable([10]) with tf.name_scope('softmax'): y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2) #---加载模型,用导入的图片进行测试-- text = Image.open('./images/text2.png') # 载入图片 data = list(text.getdata()) picture=[(255-x)*1.0/255.0 for x in data] intt=tf.global_variables_initializer() saver = tf.train.Saver() # 定义saver with tf.Session() as sess: sess.run(intt) # 载入模型参数 saver.restore(sess,"./save/model.ckpt") # 进行预测 prediction = tf.argmax(y_conv,1) predict_result = prediction.eval(feed_dict={x: [picture],keep_prob:1.0},session=sess) print("你导入的图片是:",predict_result[0])text2.png 每次代码运行完都需要 restart kernel 才能再次运行,否则会报错,具体什么原因我没深究。 以上是个人理解,有不对的希望批评指正 |
 简单来说,saver.restore() 是加载模型的参数:首先定义相同结构的模型(要定义一个和以前存盘模型相同结构的模型,只有它们的结构相同,这些变量才能吻合,才能把读取出来的变量的值赋给等待着被覆盖的变量的值)。
简单来说,saver.restore() 是加载模型的参数:首先定义相同结构的模型(要定义一个和以前存盘模型相同结构的模型,只有它们的结构相同,这些变量才能吻合,才能把读取出来的变量的值赋给等待着被覆盖的变量的值)。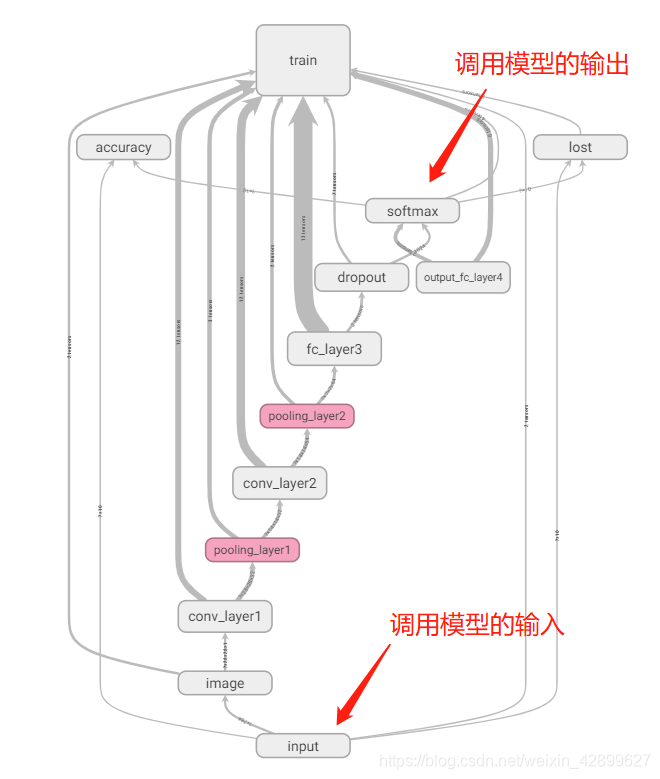
 识别结果(Spyder编译)
识别结果(Spyder编译) 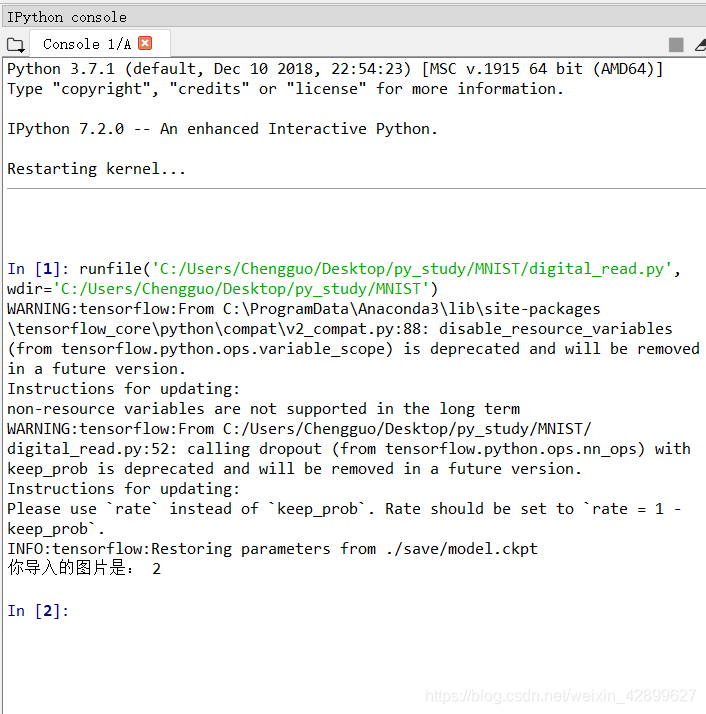 模型和图片下载链接: https://download.csdn.net/download/weixin_42899627/12672965
模型和图片下载链接: https://download.csdn.net/download/weixin_42899627/12672965 参考文章: 1 [Python]基于CNN的MNIST手写数字识别 - 东聃 - 博客园 2 TensorFlow下利用MNIST训练模型识别手写数字 - qiuhlee - 博客园 3 多层神经网络建模与模型的保存还原 4 TensorFlow实战(三)分类应用入门:MNIST手写数字识别
参考文章: 1 [Python]基于CNN的MNIST手写数字识别 - 东聃 - 博客园 2 TensorFlow下利用MNIST训练模型识别手写数字 - qiuhlee - 博客园 3 多层神经网络建模与模型的保存还原 4 TensorFlow实战(三)分类应用入门:MNIST手写数字识别【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |